



一、概述
OpenObserve 是一款开源的云原生可观测性平台,专为日志、指标和追踪数据分析设计,相较于Elasticsearch,其存储成本降低了约140倍,支持PB级数据处理,并提供高性能分析与易用部署方案。
- 多模态数据支持:兼容日志、指标、追踪(OpenTelemetry)、实时用户监控(RUM)等数据类型,支持SQL和PromQL混合查询。
- 存储成本优化:采用列式存储(Parquet格式)与对象存储(如S3/Azure Blob),压缩效率高,实测日志存储成本仅为Elasticsearch的1/140。
- 高性能架构:基于Rust开发,利用向量化处理(SIMD指令集)与无状态节点设计,实现计算存储分离,支持PB级数据实时分析。
- 全托管兼容性:提供Docker快速部署方案,支持本地化集群与云原生环境(如Kubernetes),可通过内网穿透实现远程监控。
包含的组件如下:
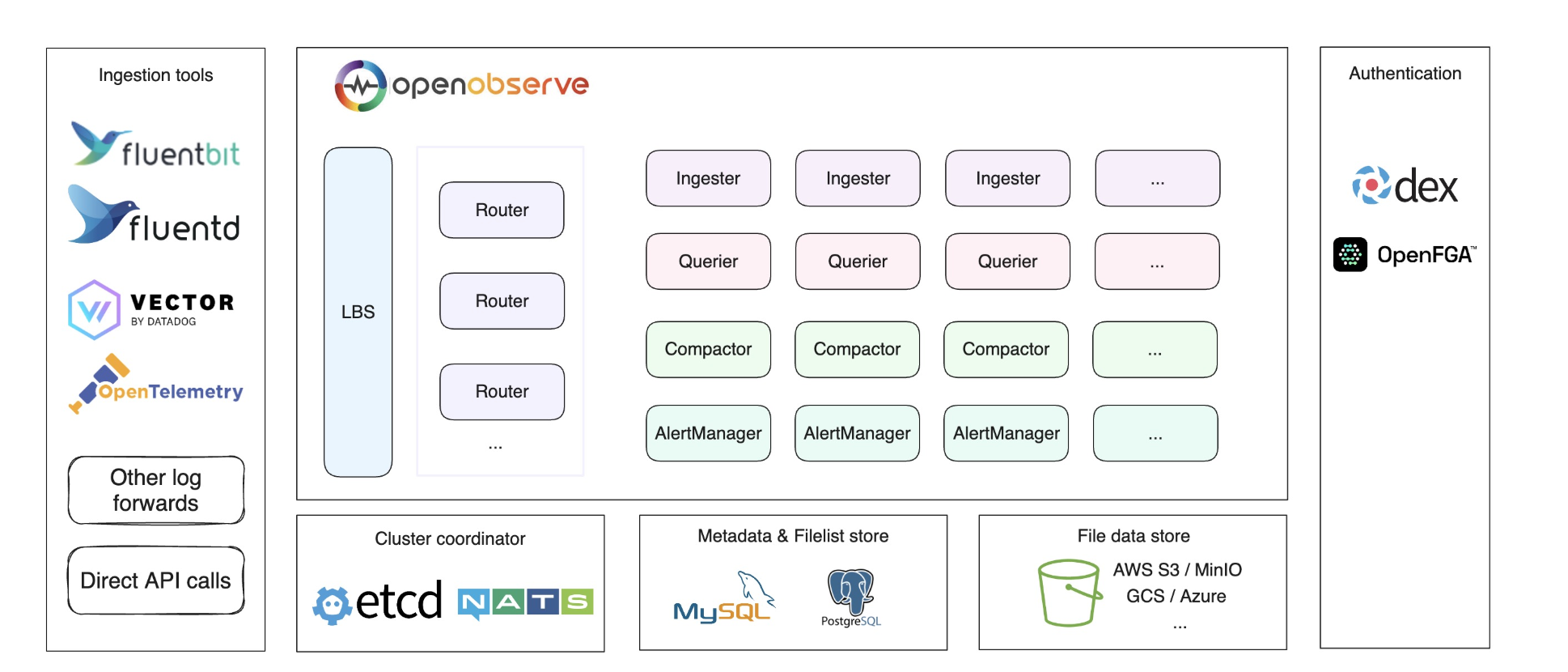
为啥要用OpenObserve呢?因为接触到项目,资源有限,部署elk太耗资源了。所以需要一个支持链路追踪,同时能收集java日志的。OpenObserve就可以完美实现了。
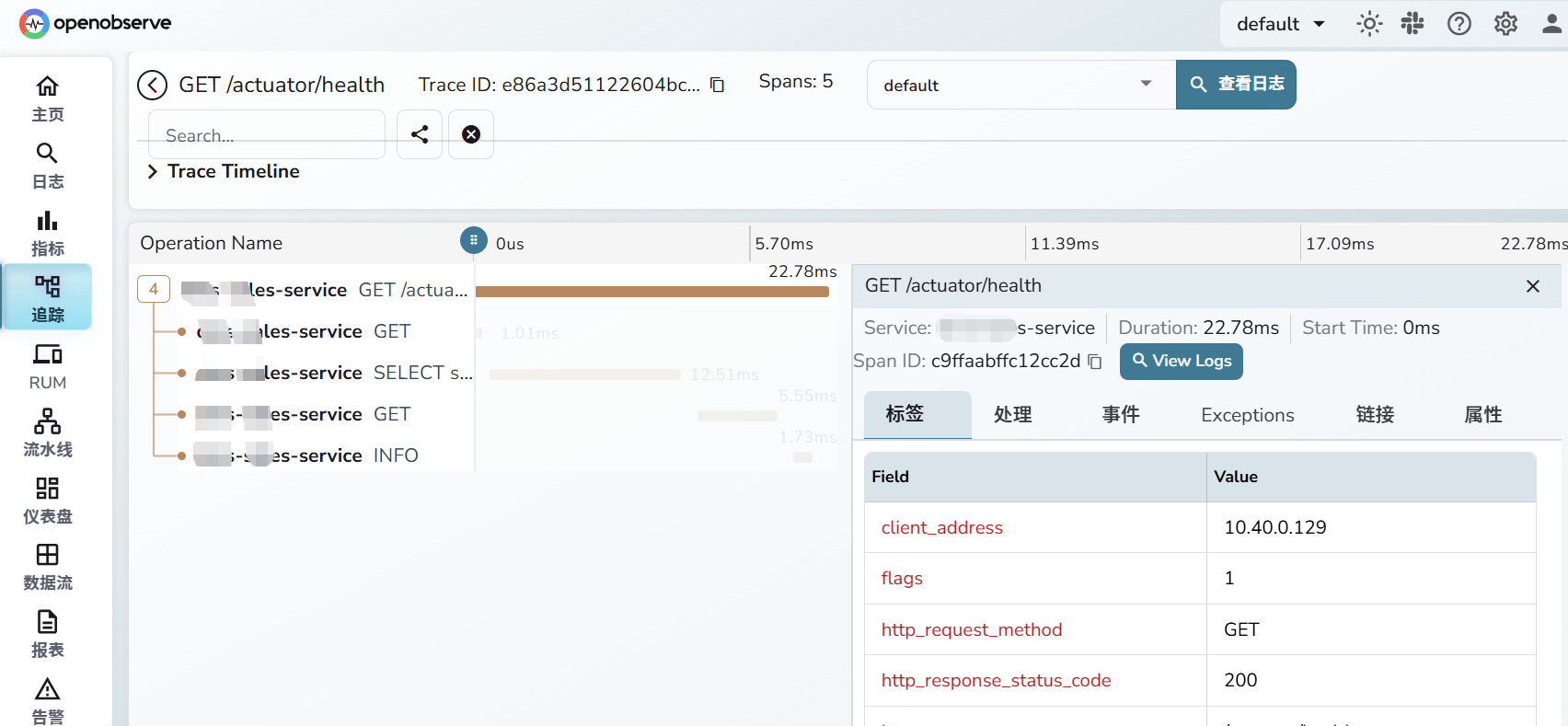
看一下效果图
链路追踪
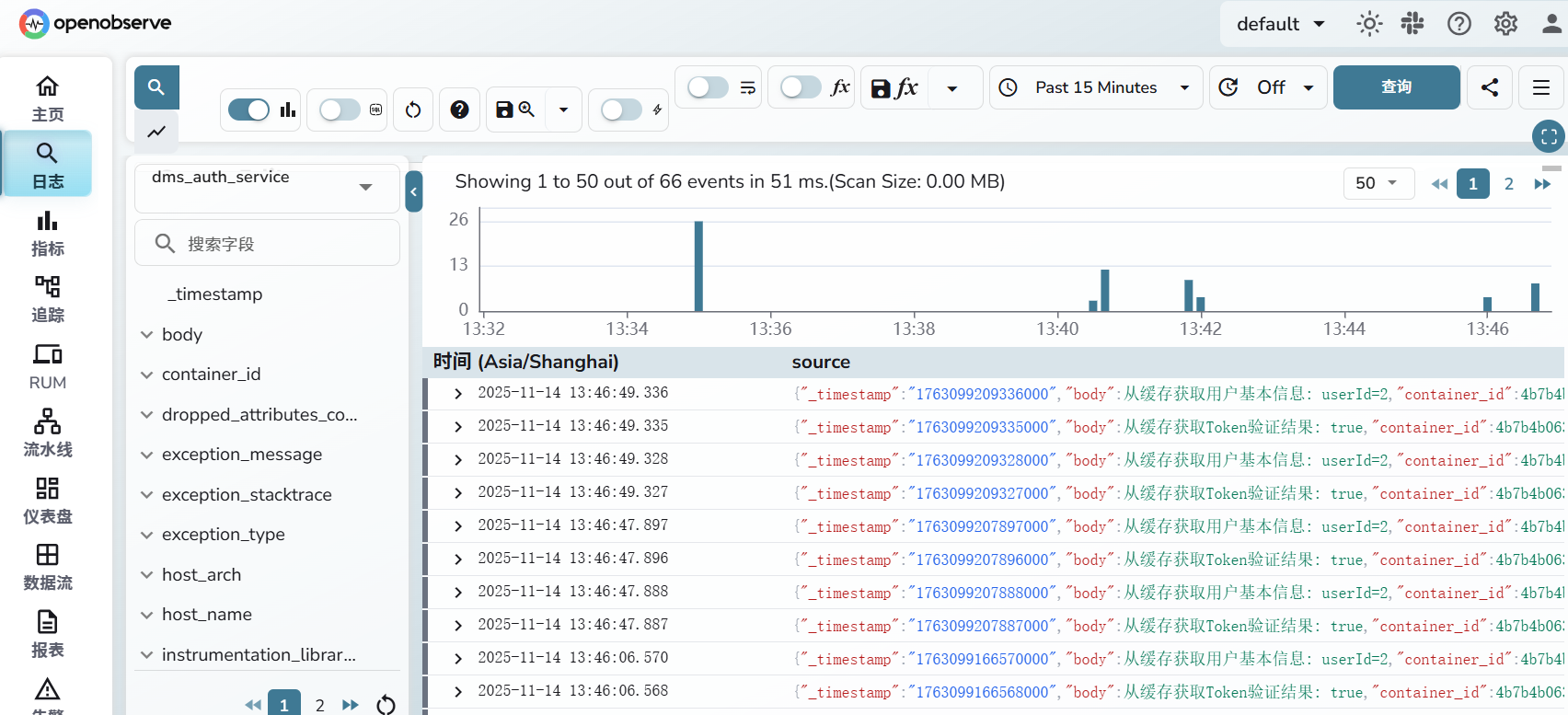
java日志
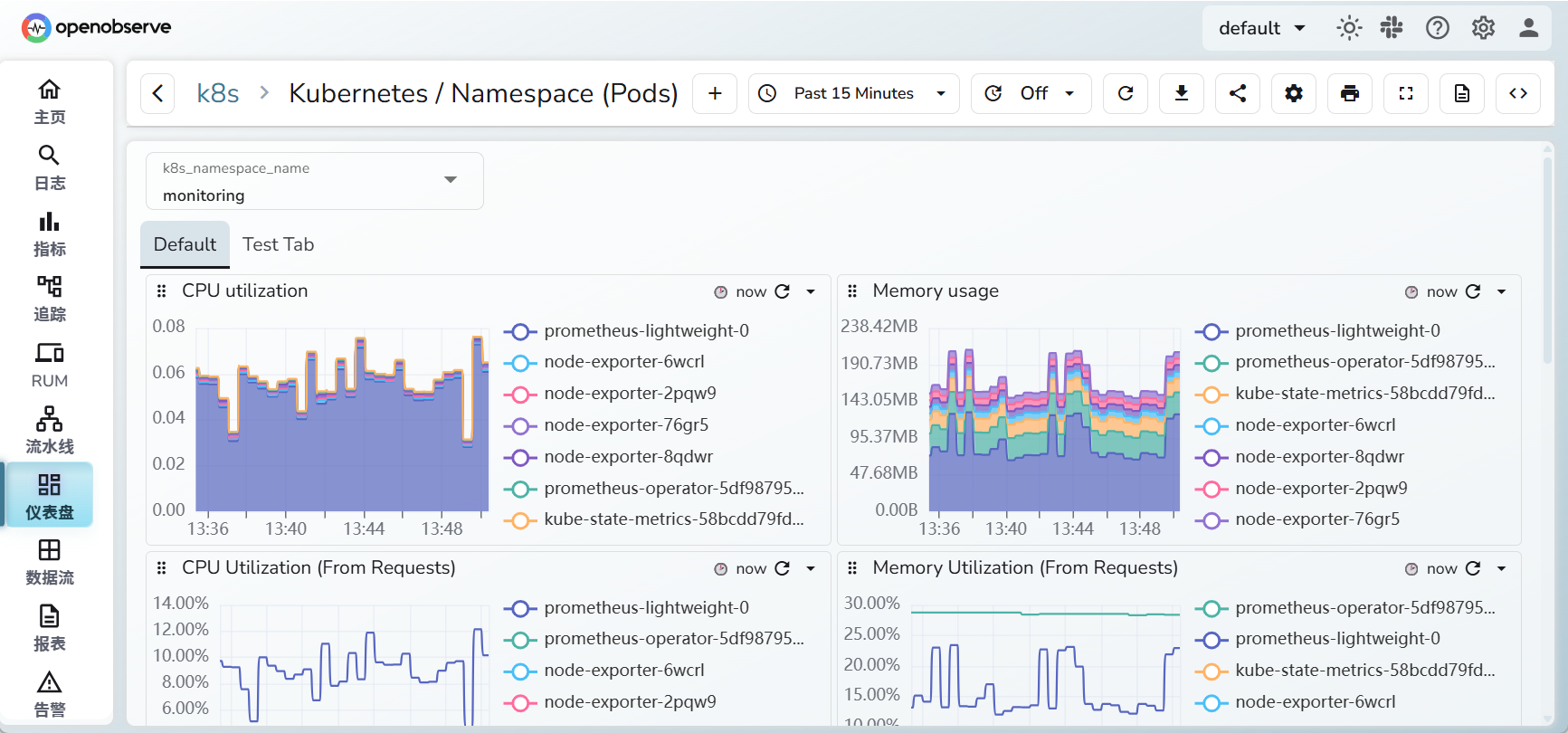
k8s pod监控
二、安装
这里使用k8s安装,准备以下yaml文件
secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: oo-admin
namespace: default
type: Opaque
data:
# echo -n 'abcd@1234' | base64 -w0
password: YWJjZEAxMjM0
说明:
这里密码使用base64加密,使用上面的命令,就可以得到加密字符串。
StatefulSet.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: openobserve
namespace: default
spec:
serviceName: openobserve
replicas: 1
selector:
matchLabels:
app: openobserve
template:
metadata:
labels:
app: openobserve
spec:
containers:
- name: openobserve
image: public.ecr.aws/zinclabs/openobserve:latest
ports:
- containerPort: 5080
name: http
env:
- name: ZO_COMPACT_ENABLED
value: "true"
- name: ZO_COMPACT_INTERVAL
value: "3600" # 秒,1 小时检查一次
- name: ZO_COMPACT_DATA_RETENTION_DAYS
value: "30" # 保留 30 天
- name: ZO_ROOT_USER_EMAIL
value: "root@example.com"
- name: ZO_ROOT_USER_PASSWORD
valueFrom:
secretKeyRef:
name: oo-admin
key: password
- name: ZO_DATA_DIR
value: "/data"
resources:
limits:
cpu: 1000m
memory: 2Gi
requests:
cpu: 250m
memory: 500Mi
volumeMounts:
- name: data
mountPath: /data
volumes:
- name: data
persistentVolumeClaim:
claimName: pvc-dev
注意:这里数据是挂载在pvc的/data目录。 pvc云平台已经创建好了,这里直接使用。 如果你没有pvc,请手动创建好。
注意:挂载到数据目录/data,首次加载后,密码会写入到文件,之后就不能修改密码了。如果要修改,只能清空/data目录,重新加载即可。
这里设定的是OpenObserve登录用户名为root@example.com,密码就是上面的abcd@1234,数据保留30天。
service.yaml
apiVersion: v1
kind: Service
metadata:
name: openobserve
namespace: default
spec:
type: NodePort
ports:
- port: 5080
targetPort: 5080
name: http
selector:
app: openobserve
启动OpenObserve
kubectl apply -f secret.yaml
kubectl apply -f service.yaml
kubectl apply -f StatefulSet.yaml
等待几分钟,查看pod是否运行正常
# kubectl get pods
NAME READY STATUS RESTARTS AGE
openobserve-0 1/1 Running 0 162m
使用ingress发布域名访问,这里直接云平台,点点点就完成了。
访问页面:http://域名
输入用户名和密码

登录之后,默认是空数据,需要进行接入。
三、java程序接入
下载agent,访问github,下载最新版本
https://github.com/open-telemetry/opentelemetry-java-instrumentation/releases
启动命令模板
java -javaagent:./opentelemetry-javaagent.jar \
-Dotel.exporter.otlp.endpoint=http://<OpenObserve_IP>:5080/api/default \
-Dotel.exporter.otlp.protocol=http/protobuf \
-Dotel.exporter.otlp.compression=gzip \
-Dotel.exporter.otlp.headers="Authorization=Basic <base64(用户:TOKEN)>,stream-name=<你的流名>" \
-Dotel.service.name=my-java-app \
-jar your-app.jar
参数说明
<base64(用户:TOKEN)>:例如root@example.com:abcd@1234→ cm9vdEBleGFtcGxlLmNvbTphYmNkQDEyMzQ=stream-name:OpenObserve 里用来区分业务的数据流,可随意起,查询时会当成表名。
计算base64,使用以下命令
echo -n 'root@example.com:abcd@1234' | base64 -w0
以上命令太长了,可以直接通过k8s环境变量注入进去
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: "http://openobserve.default:5080/api/default"
- name: OTEL_EXPORTER_OTLP_PROTOCOL
value: "http/protobuf"
- name: OTEL_EXPORTER_OTLP_COMPRESSION
value: "gzip"
- name: OTEL_EXPORTER_OTLP_HEADERS
value: "Authorization=Basic cm9vdEBleGFtcGxlLmNvbTphYmNkQDEyMzQ=,stream-name=你的应用名"
- name: OTEL_SERVICE_NAME
value: "你的应用名"
- name: OTEL_LOGS_EXPORTER
value: "otlp"
- name: OTEL_METRICS_EXPORTER
value: "otlp"
然后java的dockerfile,启动命令为:
java $JAVA_OPTS -javaagent:/opentelemetry-javaagent.jar -jar /app.jar
等应用都发布完成之后,就可以看到日志了
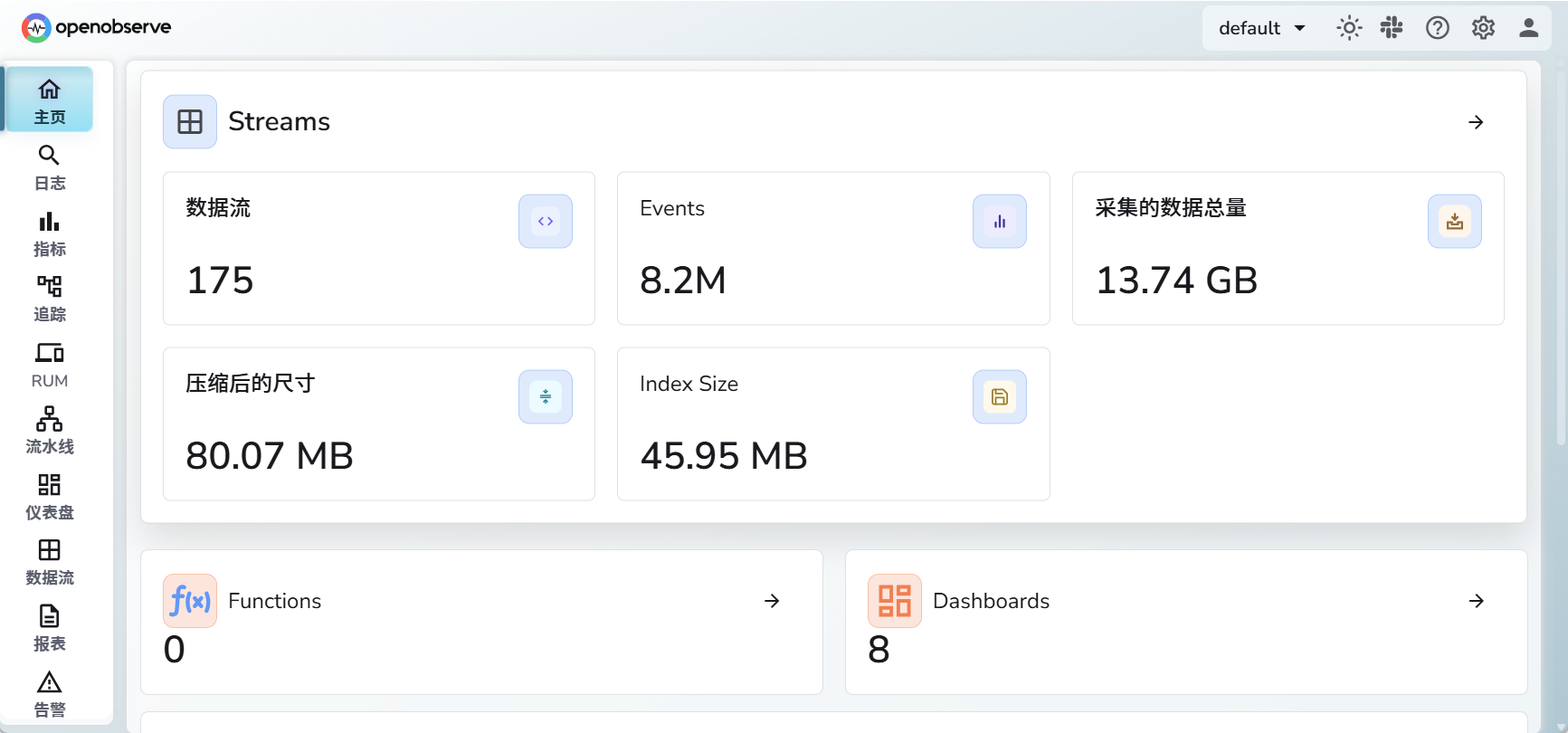
点击数据流,这里可以看到你接入了多少应用
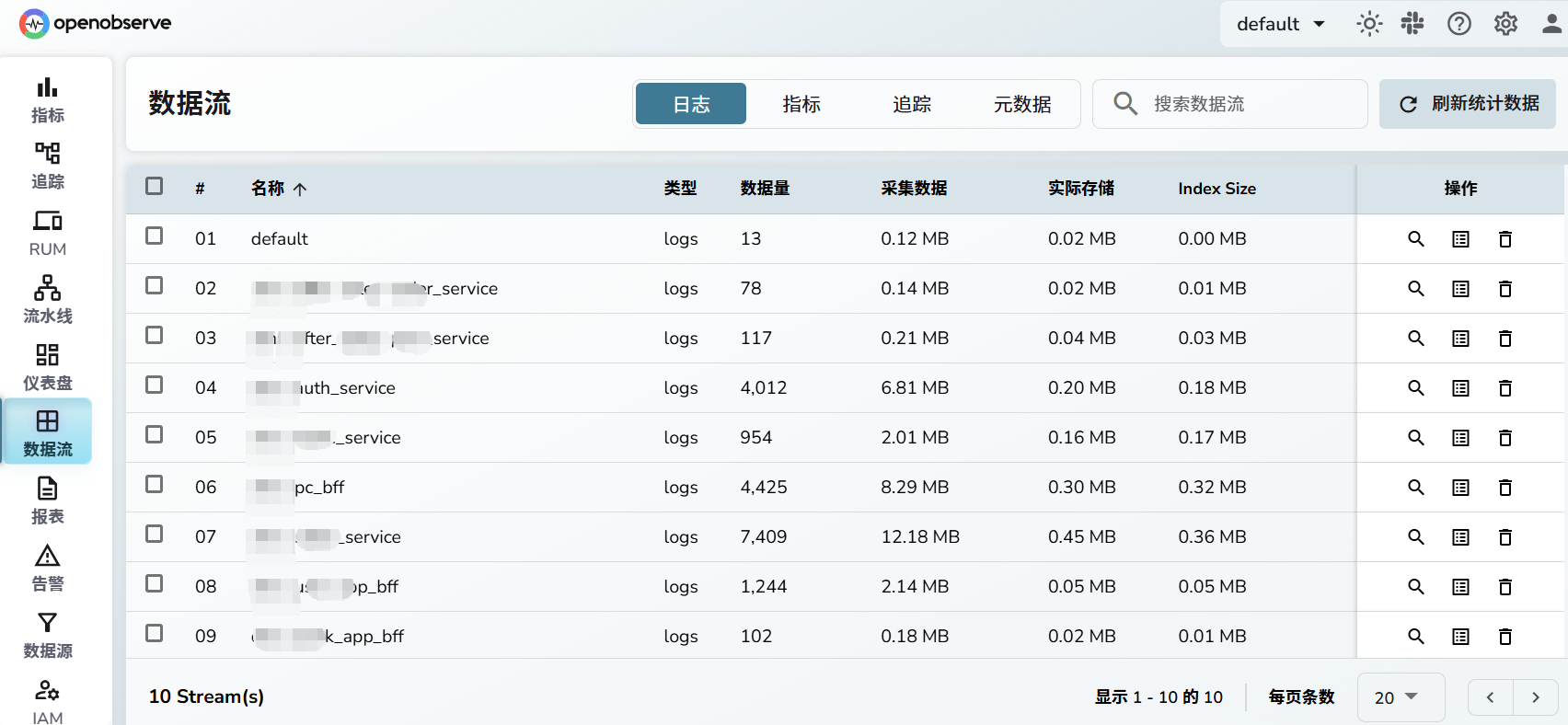
三、数据源Kubernetes
点击数据源,选择Kubernetes
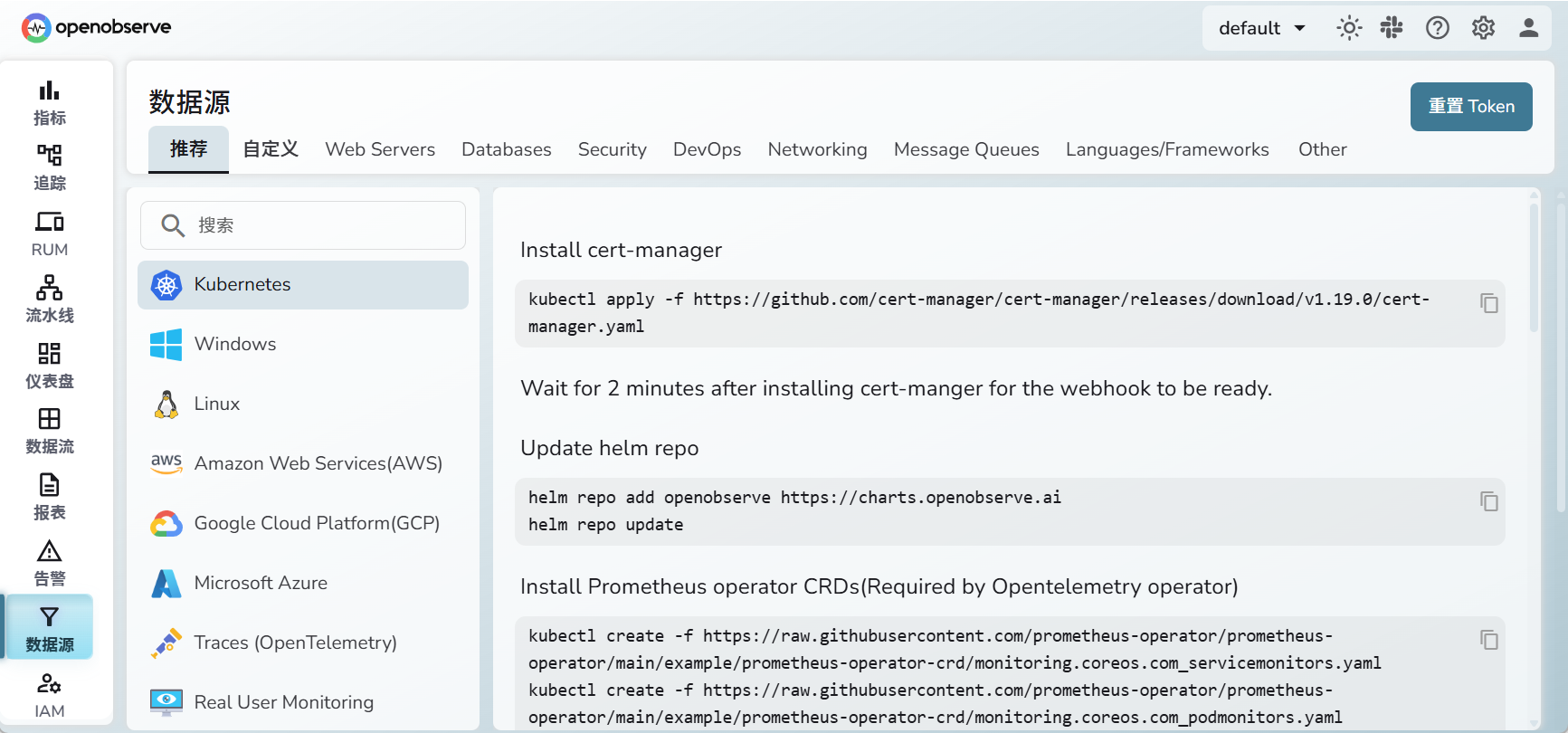
以上命令,都是要执行的,但是缺少helm命令
安装helm,使用官方脚本
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh
剩下就是,将以上页面出现的所有命令,都执行一遍,就可以了
最后一步Install OpenObserve collector,这里会根据你安装OpenObserve设定的token,自动生成安装命令,直接复制粘贴执行即可。
四、仪表盘
默认仪表盘是空的,需要手动导入。
官方仪表盘已经放到github了,链接:https://github.com/openobserve/dashboards
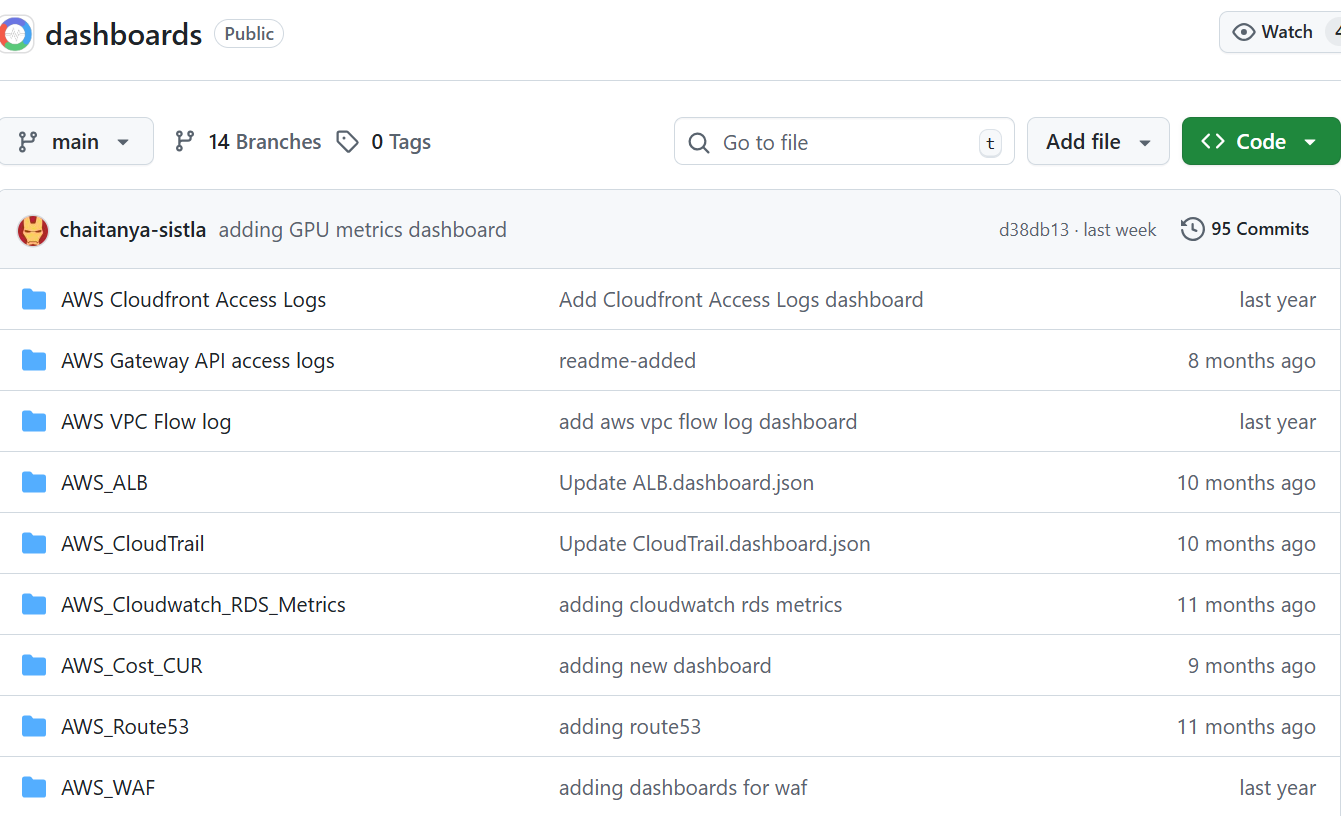
这里有N多仪表盘,但是目前我只需要k8s的,进入文件夹Kubernetes(openobserve-collector)
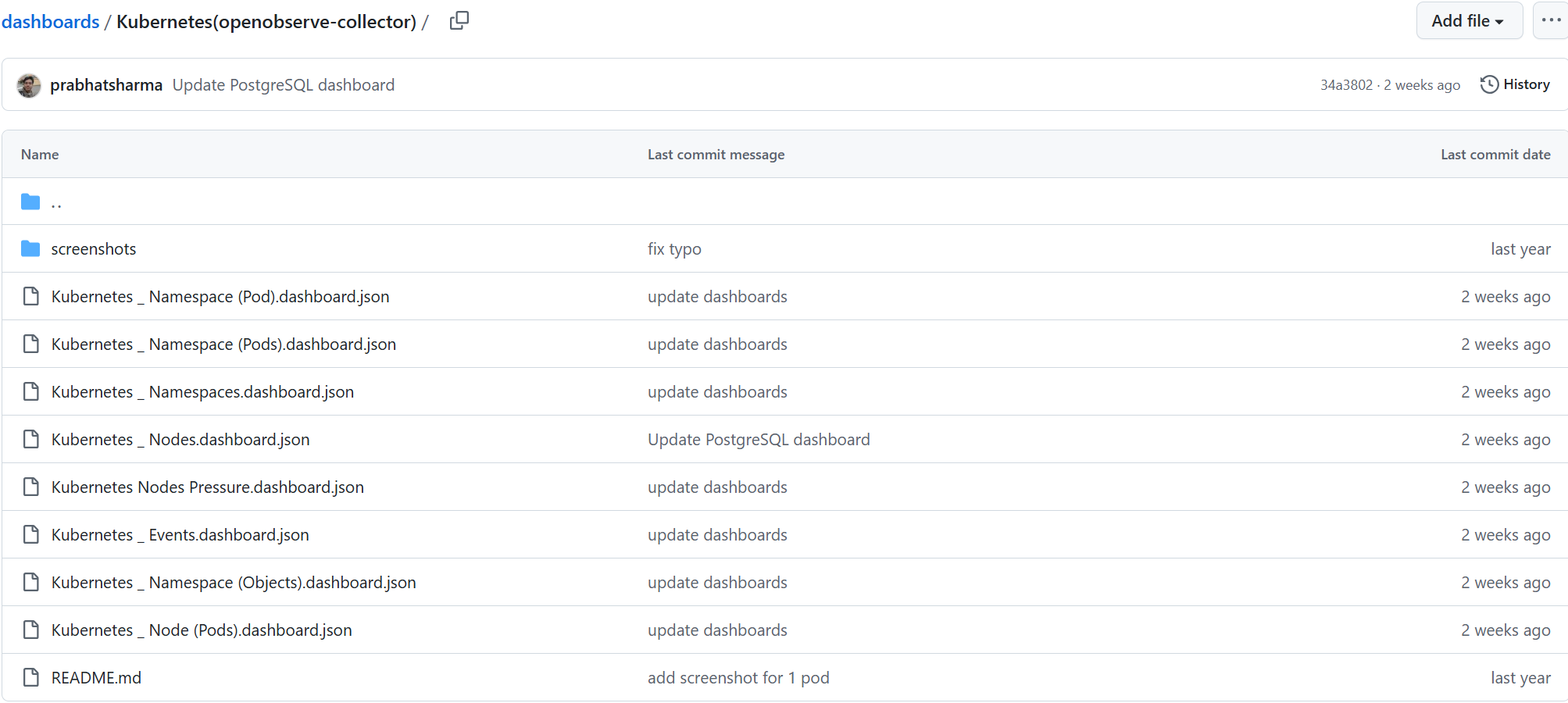
将这里面的8个json文件,下载下来。
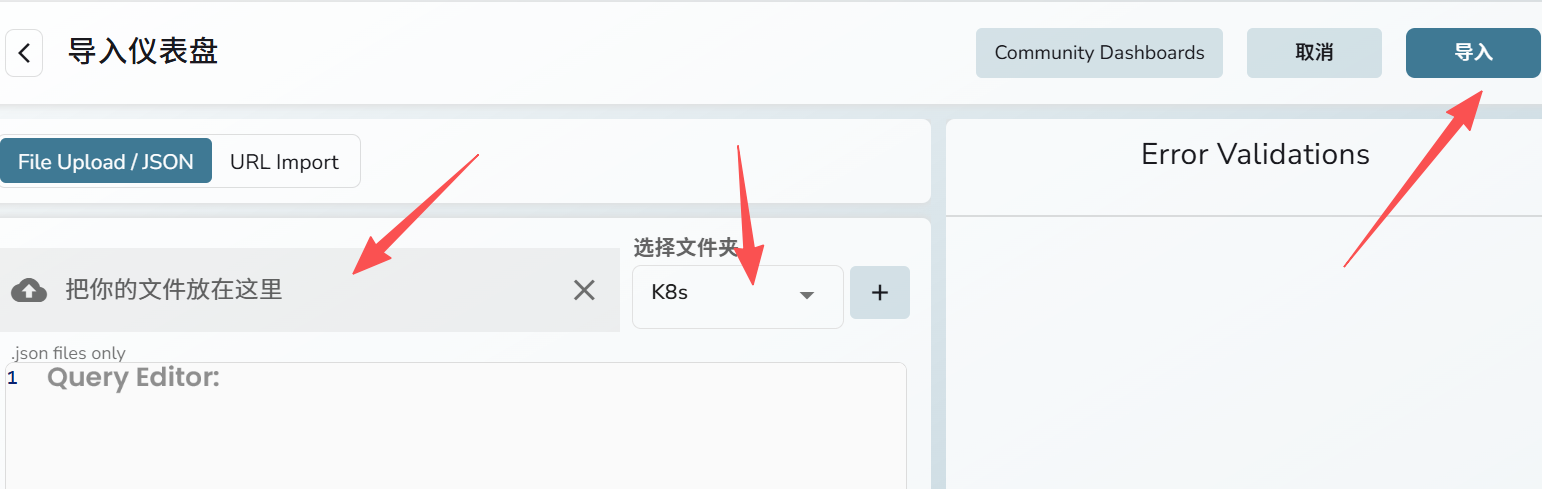
点击导入
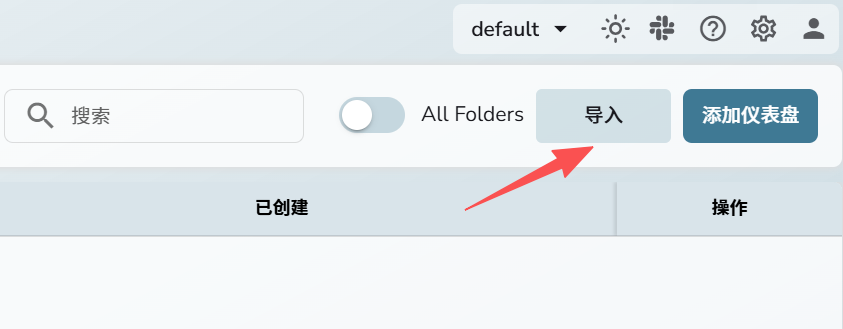
点击添加
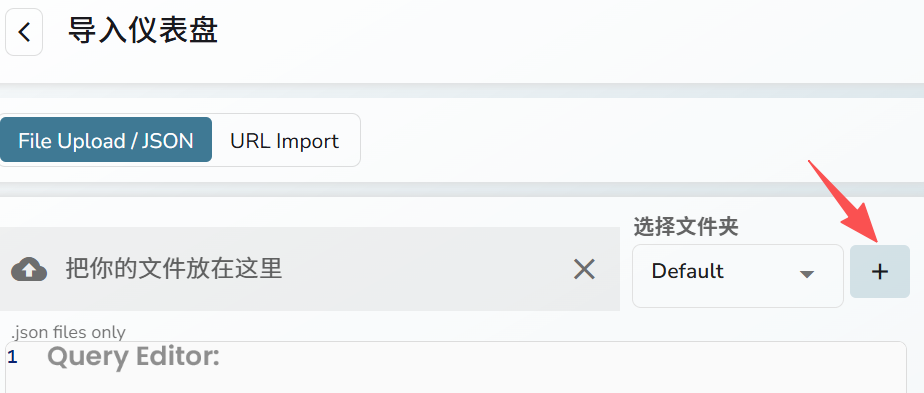
输入k8s
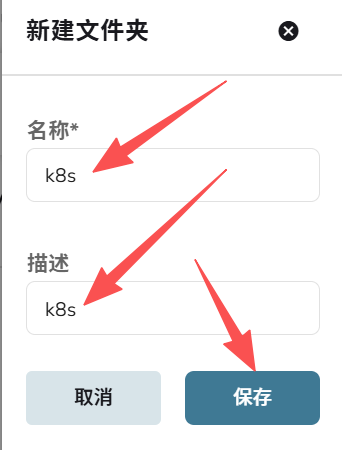
上传json文件,选择k8s文件夹,点击导入
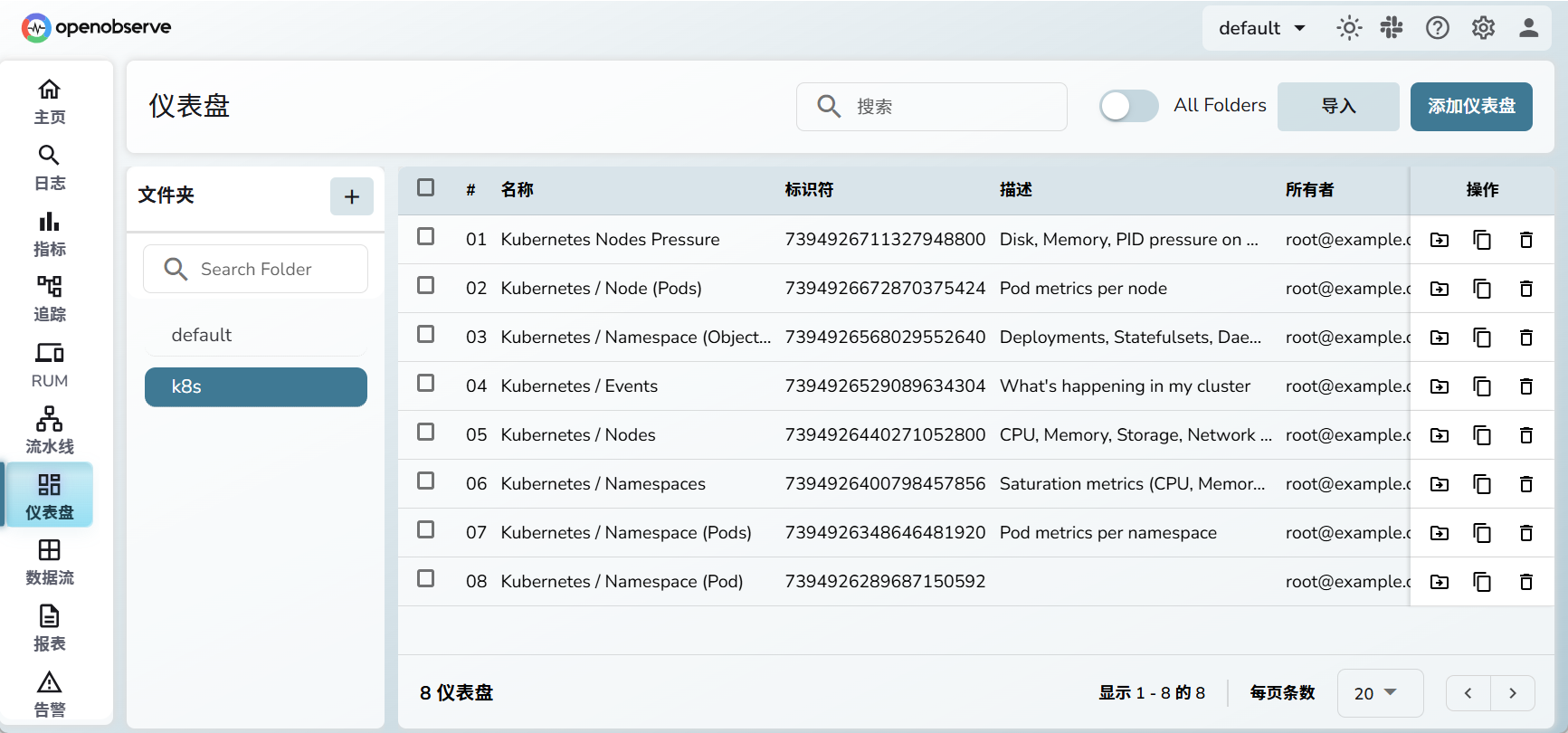
导入完成后,可以看到8个
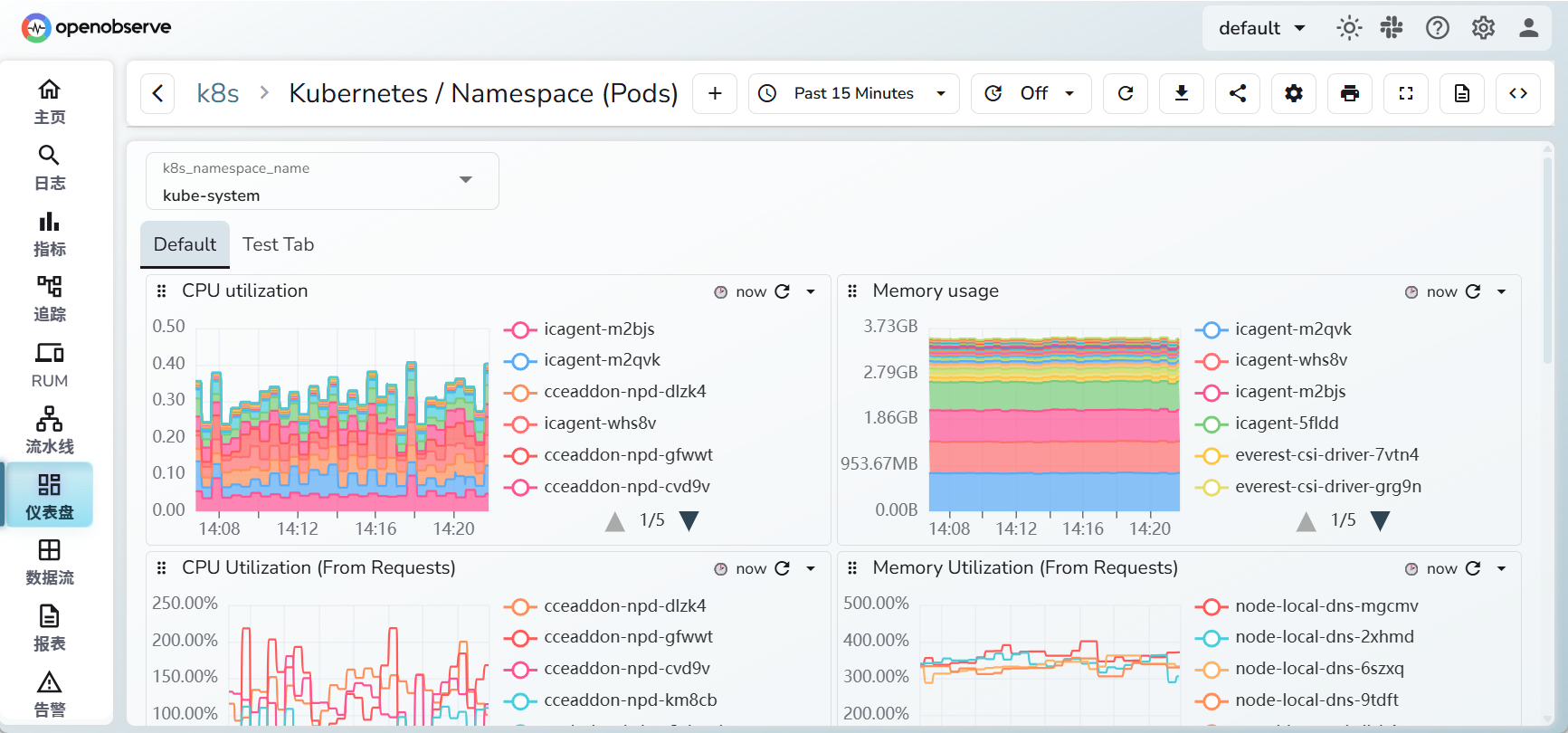
点击第7个,刷新数据,效果如下:

















 1413
1413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









