




 本文详细介绍如何使用Elasticsearch、Fluentd和Kibana(EFK)搭建日志管理系统,实现Docker环境下日志的收集、存储和可视化分析。
本文详细介绍如何使用Elasticsearch、Fluentd和Kibana(EFK)搭建日志管理系统,实现Docker环境下日志的收集、存储和可视化分析。
一、概述
Elasticsearch是一个开源搜索引擎,以易用性着称。kibana是一个图形界面,可以在上面条件检索存储在ElasticSearch里数据,相当于提供了ES的可视化操作管理器。
fluentd
fluentd是一个针对日志的收集、处理、转发系统。通过丰富的插件系统,可以收集来自于各种系统或应用的日志,转化为用户指定的格式后,转发到用户所指定的日志存储系统之中。
fluentd 常常被拿来和Logstash比较,我们常说ELK,L就是这个agent。fluentd 是随着Docker,GCP 和es一起流行起来的agent。
这篇文章里概括一下的话,有以下区别:
- fluentd 比 logstash 更省资源;
- 更轻量级的 fluent-bid 对应 filebeat,作为部署在结点上的日志收集器;
- fluentd 有更多强大、开放的插件数量和社区。插件列表这一点值得多说,插件太多了,也非常灵活,规则也不复杂。
基本的架构
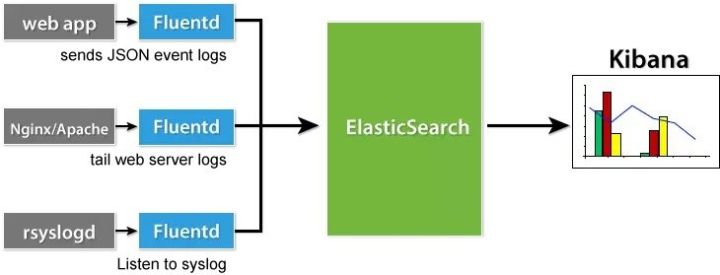
这里主要解决的问题是日志查询,日志来源是docker。我们使用docker部署任务时,可以使用docker logs -f <容器id>查看日志,也可以去/var/lib/docker/containers/<容器id>/<容器id>-json.log查看日志文件。但是这都很难去做查询,本文介绍的EFK就可以解决这个问题。
我们会创建四个容器:
- httpd (发送日志给EFK)
- Fluentd
- Elasticsearch
- Kibana
环境说明:
请安装最新的docker及docker-compose,老版本会有些问题。
docker安装,请参考链接:
https://www.cnblogs.com/xiao987334176/p/11771657.html
docker-compose安装,请参考链接:
https://www.cnblogs.com/xiao987334176/p/12377113.html
操作系统:centos 7.6
配置:2核8g
docker版本:19.03.6
docker-compose版本:1.24.1
本文使用一台centos7.6服务器,来演示EFK。
注意:内存至少在4g或者以上。
二、docker-compose运行EFK
目录结构
创建一个空目录
mkdir /opt/efk/
目录结构如下:
./ ├── docker-compose.yml └── fluentd ├── conf │ └── fluent.conf └── Dockerfile
docker-compose.yml


version: '2' services: web: image: httpd ports: - "1080:80" #避免和默认的80端口冲突 links: - flue
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









