




文章目录
一、认识数据中台
数据中台是一个可持续的机制,旨在让企业的数据发挥更大的价值和作用。它是一种战略选择和组织形式,通过构建一套持续不断将数据变成资产并服务于业务的机制,实现数据的集中管理与运营,从而提升企业的竞争力和创新能力。
数据中台可以理解为处于业务前台和技术后台之间的中间层,它抽象和共享了对业务提供的数据能力。通过将企业的数据变成数据资产,并提供相应的数据能力组件和运行机制,数据中台可以实现对数据进行聚合、加工、分析,并以共享服务的方式将数据提供给业务端使用。这样就能够与业务产生联动,并最终实现数据变现。
二、数据中台本质
数据中台,听起来有点高大上,是不是很难理解呢?其实,它的本质很简单,就是把企业的数据变成有价值的资产,并通过数据服务支持业务发展。
想象一下,你家里堆满了各种杂乱无章的东西,你需要找到一件特定的物品时得费好大劲。但如果你能将这些物品整理分类,并且在一个地方标明每个物品的位置和用途,那么你就可以方便快捷地找到所需的物品了。
数据中台也是一样的道理。企业通常会收集大量的数据,但这些数据往往散落在各个部门和系统中。当我们需要分析数据、做决策时,却发现数据无法统一、难以获取。这时候,一个数据中台就派上用场了。
所以,数据中台而言,是将企业内部所有的数据资源进行整合和管理。它提供了一个统一的平台,在这个平台上可以对所有的数据进行分类、标记和归档。比如说,销售部门的销售额、采购部门的采购量、市场部门的市场调研等等,都可以在一个地方进行管理和查询。
我们通过建立数据中台,可以实现以下几个目标:
- 首先,提高数据的质量和准确性。通过统一管理,可以避免数据重复、冗余和错误,保证数据的一致性和可靠性。
- 其次,提高数据的可访问性和可用性。数据中台提供了一个统一的接口,让用户可以方便地查询和获取所需的数据,无论是内部员工还是外部合作伙伴。
- 再次,提升数据的价值和应用能力。通过对数据进行加工、分析和挖掘,可以发现其中蕴藏的商业价值,并将其转化为具体的业务决策和行动。
- 最后,实现业务创新与增长。通过充分利用企业内部的数据资源,可以发现新的商机、优化运营流程、提升客户体验等,从而推动企业的创新与增长。
总之,数据中台就是将企业内部所有的数据资源整合起来,并为其赋予更大的价值和应用能力。它不仅是一个技术平台,更是一个推动企业数字化转型和发展的战略选择。相信随着时间的推移,越来越多的企业会意识到建立数据中台对于他们未来发展至关重要!
注意:数据中台的核心,是避免数据的重复计算,通过数据服务化,提高数据的共享能力,赋能数据应用。
三、数据中台建设方法论
阿里巴巴就提出了数据中台建设的核心方法论:OneData 和 OneService。经过这么多年,很多公司都进行了实践。
方法论就相当于一个设计图纸。就比如,你要建房子,肯定不可以拍拍屁股上来就干。
只能先有了设计图纸,我们才知道如何去实施。
同理,在建设数据中台的前提,也是需要设计图纸---->方法论。
1.1 OneData
用一句话定义 OneData 的话,就是所有数据只加工一次。
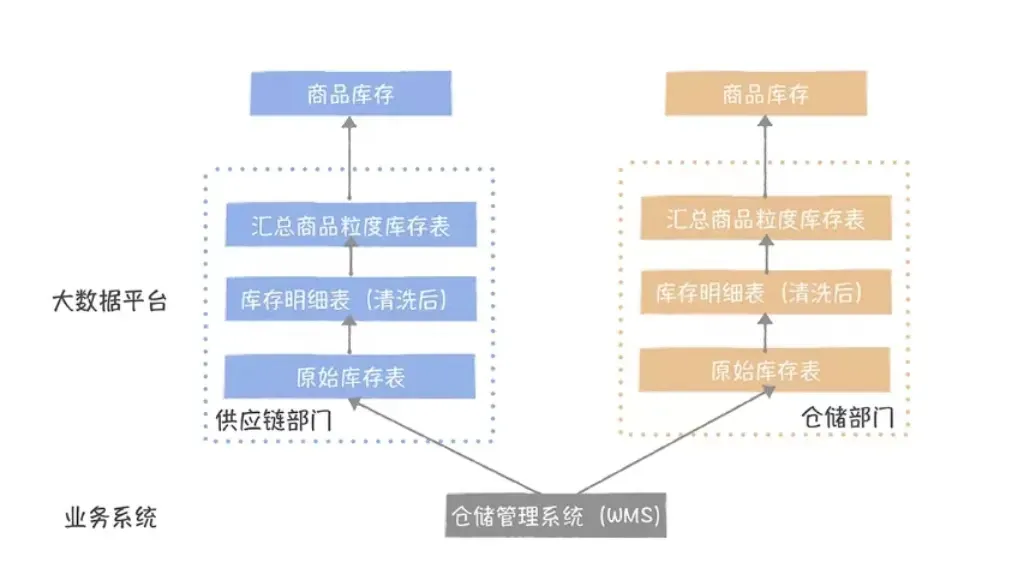
在没有数据中台之前,每个部门统计指标都是各自按照自己的需求进行计算,互相不进行数据的沟通交流。如果有相同的指标需求,那么就会重复计算两次。
造成了时间和人力成本的浪费。
专业的来说,就是不同部门、不同业务信息系统数据库中的数据往往无法互通,只能在各自数据库中储存,无法统一进行利用,没有针对企业整体的全局视角。
这样一来,每个部门、每个业务系统的数据都相互分隔,就像海外一座座孤岛,彼此无法连接,无法交流,这就是平时经常听到的数据孤岛。
而数据中台就是要在整个业务形成一个公共数据层,消灭这些跨部门的小数仓,实现数据的复用,所以强调数据只加工一次,不会因为不同的应用场景,不同的部门数据重复加工。
1.2 OneService
OneService,数据即服务,强调数据中台中的数据应该是通过 API 接口的方式被访问。
如果你是数据应用开发,当你要开发一个数据产品时,首先要把数据导出到不同的查询引擎上:
- 数据量小的使用 MySQL;
- 大的可能用到 HBase;
- 需要多维分析的可能需要 Greenplum;
- 实时性要求高的需要用到 Redis;
总的来说,不同的查询引擎,应用开发需要定制不同的访问接口。
而 API 接口一方面对应用开发屏蔽了底层数据存储,使用统一标准的 API 接口查询数据,提高了数据接入的速度。另一方面,对于数据开发,提高了数据应用的管理效率,建立了表到应用的链路关系。
四、数据中台支撑技术
讲完方法论,我们接着要来讲数据中台的支撑技术,因为一个好用的工具,可以让你的数据中台建设事半功倍。
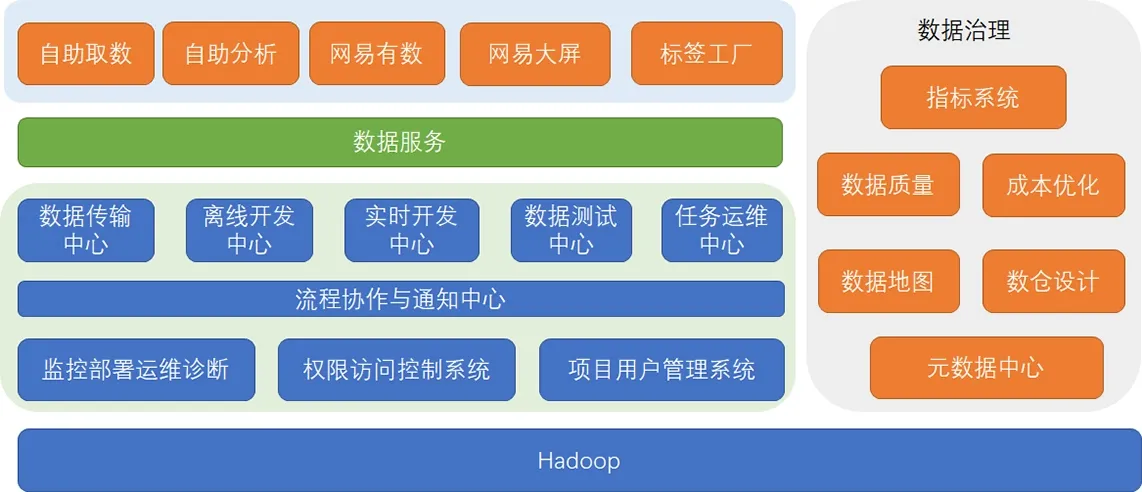
这个图完整地描述了数据中台支撑技术体系,它的底层是以 Hadoop 为代表的大数据计算、存储基础设施,提供了大数据运行所必须的计算、存储资源。
以 HDFS 为代表的分布式文件系统,以 Yarn/Kubernates 为代表的资源调度系统,以 Hive、Spark、Fink 为代表的分布式计算引擎,都属于基础设施范畴。如果把数据中台比作是一个数据工厂,那可以把它们比作是这个工厂的水、电。
在 Hadoop 之上,浅绿色的部分是原有大数据平台范畴内的工具产品,覆盖了从数据集成、数据开发、数据测试到任务运维的整套工具链产品。同时还包括基础的监控运维系统、权限访问控制系统和项目用户的管理系统。由于涉及多人协作,所以还有一个流程协作与通知中心。
灰色的部分,是数据中台的核心组成部分:数据治理模块。它对应的方法论就是 OneData 体系。以元数据中心为基础,在统一了企业所有数据源的元数据基础上,提供了包括数据地图、数仓设计、数据质量、成本优化以及指标管理在内的 5 个产品,分别对应的就是数据发现、模型、质量、成本和指标的治理。
深绿色的部分是数据服务,它是数据中台的门户,对外提供了统一的数据服务,对应的方法论就是 OneService。数据服务向下提供了应用和表的访问关系,使数据血缘可以延申到数据应用,向上支撑了各种数据应用和服务,所有的系统通过统一的 API 接口获取数据。
在数据服务之上,是面向不同场景的数据产品和应用,包括面向非技术人员的自助取数系统;面向数据开发、分析师的自助分析系统;面向敏捷数据分析场景的 BI 产品;活动直播场景下的大屏系统;以及用户画像相关的标签工厂。
这套产品技术支撑体系,覆盖了数据中台建设的整个过程,配合规范化实施,你就可以搭建出一个数据中台,关于具体的细节我会在实现篇中逐一分析讲解,这里你只需要知道这个框架就可以了。
五、数据中台的开源解决方案
如何利用纯开源的方案建设一个数据中台,事实上难倒了不少人。因为开源框架种类繁多,每一个模块都有很多的开源套件。以查询引擎为例,可以使用的开源工具有MySQL、Redis、Impala、MongoDB、PgSQL 等。大家可以根据实际业务需要,选择合适的开源套件。
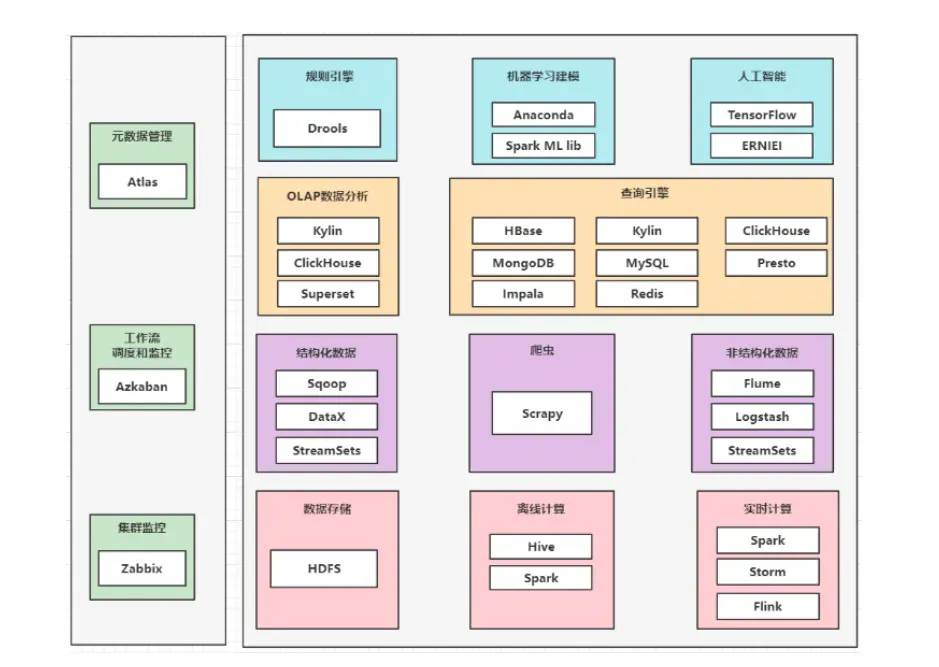
可供选择的解决方案太多,笔者根据自身的建设经验,重点推荐开源解决方案,框架图如下所示。企业的数据应用主要有离线计算和实时计算。建议离线计算优先选择 Hive 和 Spark 。Spark是基于内存的。实时计算目前主流的选择是 Flink 框架。
3.1 数据存储
目前,互联网行业大数据的主流存储框架是基于Hadoop的分布式文件系统HDFS。由于其具有高容错性和适合批处理数据的特点适合部署在低廉的PC服务器上存储海量的数据,数据存储的性价比较高。从0到1搭建大数据平台
3.2 数据开发
- 离线计算
在HDFS的基础上,Hadoop 生态又开发了离线数据仓库计算引擎 Hive。Hive基于 MapReduce技术支持分布式批处理计算,同时支持以 SQL 操作的方式对存储在HDFS上的数据进行“类数据库”的操作、计算和统计分析。Hive 适合海量数据的批处理操作场景操作简单,容错性和扩展性好,缺点是高延迟,查询和计算都比较慢。因此Hive被广泛应用在离线计篡场景中,尤其是对海量数据的批处理操作和分析场景中。
因为基于 MapReduce技术涉及磁盘间高频的 I/O 操作,所以Hive的计算效率较低,时效很长。为了提高计算的效率,Hive 社区增加了新的计算引擎,即 Spark 。与 MapReduce 相比,Spark 的RDD计算引擎基于内存进行计算,计算和查询效率显著提升。
目前,主流的离线计算框架采用 Hive 和 Spark 结合的方式。在100个节点以下时,可以选用 Hive 作为数据仓库、Spark作为计算引擎。另外,对于海量数据场景(如节点数需要几百个甚至上千个时),Hive 的优势是稳定性和容错性好,可以用于处理海量数据的复杂计算。Spark 的优势是计算速度快,缺点是容易出现内存泄漏和不足,从而导致计算缓慢或者任务失败。在海量数据场景中,出于稳定的要求,Spark 一般用于处理数据仓库上层的查询、计算和分析操作。而底层的操作由 Hive完成。笔者重点推荐使用 Hive 和 Spark工具。
- 实时计算
开源的实时计算框架比较多,如 Spark、Storm 和 Flink 等。与 Storm 相比,Spark的优势是用一个统一的框架和引擎支持批处理、流计算、查询、机器学习等功能 。由于 Spark 的微批处理的设计机制,在处理流数据的时候,效率比 Storm 要低 。
Flink 比 Spark 诞生得晚,因此有很多新的设计思路和特色,如数据流模型、反压机制、内存自管理、异步节点检查机制和有状态处理机制等。Flink 和 Spark 一样,也提供查询、机器学习、图计算等功能,但是 Spark 在 SQL 语句丰富程度、 API 功能完备和简单易用方面比 Flink 更优秀。而 Flink 在数据流的实时处理能力、界面设计和操作友好性、平台化管理、任务分析能力等方面要优于 Spark。
整体而言,Spark 体系更加成熟,易用性较好、社区文档和案例更加丰富,如果对于数据延迟要求是秒级,那么 Spark 更容易上手且能满足性能要求。Flink 是后起之秀,特别是 Flink 1.10 之后的版本,强化流批一体数据仓库,高度兼容 Hive,其实时处理能力和设计理念要优于 Spark,成为实时数据仓库计算引擎的热门选择。因此笔者重点推荐使用 Spark 和 Flink 工具 。
3.3 查询引擎
为了提高数据交互性查询的效率,在大数据时代根据不同的业务要求诞生了很多新的查询引擎,常见的查询引擎有 HBase、Redis、MongoDB 等。按照大类划分,查询引擎可以分为 SQL 交互式查询引擎和 NoSQL 交互式查询引擎。HBase、Redis、MongoDB 都属于 NoSQL 交互式查询引擎。
- SQL 交互式查询引擎
常用的 SQL 交互式查询引擎有 Impala、Presto、ClickHouse、Kylin 等。Impala 和 Presto 基于 MPP 架构,通过分布式查询引擎提高查询效率。ClickHouse、Kylin 是目前主流的联机分析处理(Online Analytical Processing,OLAP) 计算和查询引擎。
Kylin 通过预计算机制,提前将客户经常查询的维度和指标设计好并进行预处理操作,以数据立方体模型(Cube)形式缓存,以便加快聚合操作和查询的速度,特别适合对海量数据的 OLAP 场景。由于需要提前将数据预处理好,Kylin 需要消耗额外的空间,且无法高效支持随机的计算和查询。
ClickHouse 适合海量数据的大宽表(维度和指标较多的表)的灵活和随机的查询、过滤和聚合计算,写入和查询性能很好,而多表关联操作性能一般,尤其是多个数据量较大的表(即大表)关联的情况。其劣势是不擅长高频的修改和删除操作,在多用户高并发场景中性能一般。
Presto 由 Facebook 开源,支持基于内存的并行计算,支持多个外部数据源和跨数据源的级联查询,在对单表的简单查询和多表关联方面性能较好,擅长进行实时的数据分析。在处理海量数据时,Presto 对内存容量要求高,多个大表关联容易出现内存溢出。
Impala 由 Cloudera 推出,是一个 SQL on Hadoop 的查询工具,也基于内存进行并行计算,目标是提供 HDFS、HBase 数据源复杂的高性能交互式查询。Impala 的单表和多表关联查询性能和 Presto 相近,支持窗口函数、增量统计、多用户高并发查询,但是数据源的丰富程度不如Presto。Impala 对内存容量要求高,多个大表关联容易出现内存不足。
目前,ClickHouse 和 Kylin 的热度很高,很多“互联网大厂”都开始采用这两个计算和查询框架作为 OLAP 的主流框架。一般而言,预先设计好维度和指标,然后进行聚合计算和查询的场景适合使用Kylin,而对于随机(ad_hoc)查询更适合使用 ClickHouse。
在实际应用中,根据不同的应用场景,一般会部署多种引擎,比如 ClickHouse 和 Kylin 。
- NoSQL 交互式查询引擎
HBase是基于 key-value 原理的列式查询引擎,适用于频繁进行插入操作且查询字段较多的场景,如统计每分钟每个商品的点击次数、收藏次数、购买次数等。HBase的列式扩展能力较强,理论上硬盘有多大,HBase 的存储能力就有多大。HBase不适用于大量更改了(update)操作的场景。HBase的主要缺点是 update 操作性能较低。
Redis是内存数据库。Redis 的原理是基于内存进行计算和查询。Redis 的存储容量与内存容量有关,支持的数据类型比较丰富,有一定的持久话能力,适用于高频 update 操作的场景,读写的速度都非常快。其缺点是内存容量有限,价格较高,一般用于存储非常有价值且需要高频读写的数据。比如,实时统计全站客户累计点击次数、收藏次数、购买次数等用于数据看板(dashboard)的展示。
MongoDB 主要以 JSON 数据串格式存储数据,适用于表结构变化大的海量数据查询和聚合计算的场景,这是其区别于其他数据库的重要特色。比如,构建客户大宽表,客户的有关字段经常发生改变或增删,在这种场景中很适合用 MongoDB 存储并高效读取客户的单一维度信息或聚合信息。但是其写入操作和多表关联复杂操作性能一般,很少用于复杂的多表关联的计算场景。在实际应用中,一般会综合部署上述 NoSQL 引擎,满足不同的应用场景。
3.4 数据采集工具
开源的数据采集工具很多,如 Sqoop、DataX、Scrapy、Flume、Logstash 和 StreamSets 等。Sqoop 和 DataX 主要用于采集结构化数据,Flume 和 Logstash 主要用于采集非结构化数据。StreamSets 同时支持结构化和非结构化数据的采集。
在结构化数据采集方面,与 DataX 相比,Sqoop 的综合性能更好,社区更活跃,插件更丰富,使用更广泛。
Logstash 更轻量,使用更简单,插件丰富,对技术要求不高,运维比较简单。Flume 框架更复杂,偏重于数据传输过程中的安全,不会出现丢包的情况,整体配置更复杂,入门难度较高,运维难度更高。StreamSets 通过可视化界面的拖、拽等操作实现数据的采集和传输,支持多种数据源,组件丰富,功能强大,简单易用,且内置监控组件,可以实时监控数据传输情况。由于 StreamSets 的这些优势,目前它在数据采集领域大有一统江湖的趋势。笔者重点推荐使用 StreamSets。
有时候还需要从第三方平台获取一些公共数据,数据爬虫工具 Scrapy 可以支持从网上爬取数据。
3.5 数据仓库
在数据平台选择好后,下一步的重要工作是实现企业的数据资产化,满足前端业务对数据应用的需求。数据资产化的关键举措是对企业的原始数据进行清洗和规整,将其转化为价值数据,然后从中抽离出主数据,进一步构建不同主题的数据标签体系。这些关键举措离不开数据仓库的标准化、存储、计算和建模体系化的支撑。
目前,主流的数据仓库分为离线数据仓库和实时数据仓库,两者的典型区别是数据服务时间粒度。传统的离线数据仓库一般的数据服务时间粒度是天,实时数据仓库的数据服务时间粒度是分钟,甚至秒。从数据仓库存储和计算框架开源解决方案来看,目前行业的离线数据仓库普遍采用 Hive + Spark 的综合方案,而实时数据仓库当前的主流方案之一是 HDFS + Flink + Kafka 。目前,大部分企业在建设数据仓库时,综合考量性能、健壮性、投入产出比和运维复杂度,主要策略是以离线数据仓库的批处理计算为主,以实时数据仓库为辅助。
3.6 可视化自助数据分析
数据分析是实现数据价值的关键举措之一。透过错综复杂的数据关系发现价值点是一项费力、费时的工作。好的工具能够使这项工作事半功倍。为了提高数据分析的效率,行业涌现了多种解决方案,集中体现在自助取数、自助分析、多维分析、分析可视化这几个方面,目标是实现可视化自助数据分析。可视化自助数据分析的核心功能是支持多数据源接入、权限管理、高性能计算和可视化多维分析。
日前,自助 OLAP 开源主要使用的计算引擎有 Impala、 Presto、ClickHouse 和 Kylin。在查询引擎部分,已经介绍过这几种计算引擎的特点,在此不再赘述。开源可视化解决方案主要有 Superset、 Redash 和 Metabasea。Superset 出自 Airbnp,目前是 Apache 的开源项目,功能比较强大,网上的参考案例较多。Redash 是一个轻量级的应用,部署简单,短小精悍,能满足日常分析需求。Metabase 的功能丰富程度介于 Superset 和 Redash 之间,网上的参考案例较少。在实际应用中,笔者重点推荐 ClickHouse+Kylin+Superset的统一解决方案。预计算的 OLAP 使用 Kylin 引擎,及时查询的计算使用ClickHouse。
3.7 规则引擎
规则引擎是常用的实现数据价值的基础工具之一,常用的应用场景有风险管理、动态定价、精准营销、监控预警等。笔者过去一直使用开源工具 Drools 结合二次开发搭建规则引擎,其优点是语法规则简单、支持动态规则配置、社区热度高、网上落地案例丰富、功能丰富且不断升级迭代,缺点是相对较重、应用门槛较高、聚合计算效率低等。对于实时规则应用场景,建议使用流式计算引擎计算复杂的聚合规则,而简单的规则计算使用Drools内核。
3.8 机器学习引擎
要从错综复杂的数据中挖掘出核心价值离不开算法的支持。智能化的真谛是使用机器学习算法、AI算法和其他算法不同程度地实现用机器替代人工。目前,各种开源的算法包特别多,当建模数据行数在千万级别时,笔者常用 Anaconda 包和XGBoost包。当建模数据行数在亿级别时,笔者常用Spark MLlib。笔者使用的AI算法框架是TensorFlow。在自然语言处理方面,笔者常用的是百度的 ERNIE 框架,该框架在多个公开中文数据集下的性能比 Google 的BERT框架略好。
3.9 元数据管理
笔者一直使用的元数据管理的开源工具是Apache Atlas 。Atlas 和 Hadoop无缝连接,能有效地支持元数据管理、数据资产分类、元数据搜索、血缘关系可视化和数据治理。
Atlas支持对元数据添加标签,然后通过标签对数据资产进行分门别类的管理,并基于标签进行统一权限控制和数据资产的安全管理。同时,Atlas还可以捕获各种元数据信息(如数据的产生、表的建立和执行、数据交互、数据ETL执行、数据存储、数据安全访问、数据的使用等),并支持查看元数据和血缘的可视化,便于及时发现数据的变化,快速定位数据问题。数据具有时效性,Atlas支持数据全生命周期管理(如在过了数据时效后,临时表被自动删除)。
Atlas 还支持和多个外部平台(如Hive、SAS 等)的元数据互联互通。我们可以将这些平台的元数据导入 Atlas 中,然后应用 Atlas 进行无数据管理和数据治理。
3.10 工作流调度和监控
目前,数据应用百花齐放,系统后台需要对这些数据应用的工作流进行合理调度和监控,确保数据应用的及时性和稳定性。当任务运行失败时,系统要能及时发现并实时通知相关数据运维人员。这些功能是对工作流调度和监控工具的基本要求。
(1)Oozie
Oozie是一个用来管理Hadoop生态圈job的工作流调度系统。由Cloudera公司贡献给Apache。
Oozie是运行于Java servlet容器上的一个java web应用。
目的:是按照DAG(有向无环图)调度一系列的Map/Reduce或者Hive等任务。
应用场景:Hadoop 自带的开源调度系统,使用方式比较复杂,适合大型项目场景,但是它使用XML配置,oozie任务的资源文什都必颈放在HDFS文什系统上,配置不方便,同时也只用于Hadoop。
(2)Azkaban
Azkaban是由Linkedin开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。
应用场景:一个开源调度系统,使用方式比较简单,适合中小型项目场景,但是它使用java properties文件维护任务依赖关系,任务资源文件需要打包成zip,azkaban部署不是很方便。
(3) Airflow
Airf1ow是一款开源的,分布式任务调度框架,它将一个具有上下级依赖关系的工作流,组装成一个有向无环图。
利用Python的可移植性和通用性,快速的构建的任务流调度平台,实现依赖调度、定时调度。
它具有自己的web任务管理界面,dag任务创建通过python代码,可以保证其灵活airflow性和适应性。
(4) Apache DolphinScheduler
Apache DolphinScheduler是一个分布式、去中心化、易扩展的可视化DG工作流任务调度系统,其致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
它很好与Spark和Flink整合集成,进行离线批处理任务和实时流计算调度与监控预警。
总体而言,海豚调度DolphinScheduler, 算是后起之秀。它因为出来得晚,自然就会集成了以往调度框架的优点,万千优点于一身。但是,不管如和去选择自己的调度框架,都是根据需求去综合分析的,比如我而言,对Airflow比较熟悉,所以项目中习惯用它。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











