




 本文详细解析ZooKeeper中的状态转换机制,包括CONNECTION_LOSS与SESSION_EXPIRED错误处理,会话过期机制及检测方法。同时介绍了ZooKeeper集群的升级与调整策略,以及在负载均衡器后面的集群运行情况。
本文详细解析ZooKeeper中的状态转换机制,包括CONNECTION_LOSS与SESSION_EXPIRED错误处理,会话过期机制及检测方法。同时介绍了ZooKeeper集群的升级与调整策略,以及在负载均衡器后面的集群运行情况。
Zookeeper状态转换是什么?
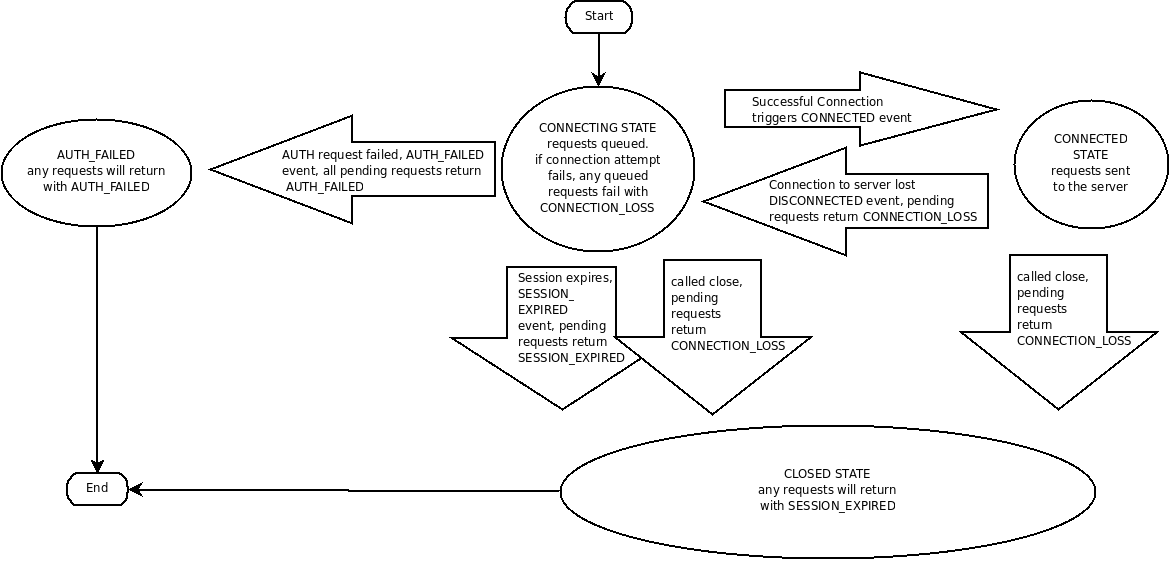
我应该如何处理CONNECTION_LOSS错误?
CONNECTION_LOSS 意味着客户端和服务端之间的连接中断了。但并不意味这客户端发到服务端的请求失败了。如果你正在完成一个请求,并且请求到达服务端之后,响应返回之前,创建的请求将会成功。如果请求数据包发出之前连接中断了,那么创建的请求会失败。不幸的是,没有办法让ZK客户端库知道这点,所以ZK客户端库会返回CONNECTION_LOSS。程序员必须考虑到请求是否成功或者需要重试。通常这是以特定于应用程序的方式完成的。成功检测的示例包括检查要创建的文件的存在或检查要修改的znode的值。
当客户端(会话)从ZK服务群集分区时,在会话创建期间,客户端将开始搜索指定过的服务器列表。最终,当客户端和服务器列表中的至少一个重新建立连接时,会话将会再转换到“已连接”状态(在会话没有超时会重新连接),或者会转换到“过期”状态(会话超时时重新连接)。ZK客户端库将会自动为你处理重连。特别是我们在客户端库中内置了一些启发式方法来处理“牧群效应”之类的事情,等等。。。只有在你被通知会话过期(强制)的时候,一个新的会话才创建。
我应该如何处理SESSION_EXPIRED?
SESSION_EXPIRED会自动关闭ZK句柄。在一个正确运行的集群里,你不应该看到SESSION_EXPIRED。这意味着客户端会因为更多的会话超时,从ZooKeeper服务分区,并且ZK认为客户端死亡。在更复杂的应用中,恢复意味着重建短暂的节点,争夺领导角色,重建已发布的状态。
ZK客户端库的编写者应该意识到过期会话的严重性,并且不要尝试去恢复。相反,ZK客户端库应该返回一个严重错误。即使ZK客户端库仅仅是简单地从Zookeeper中读取,库的用户也可能正在使用ZooKeeper做其他事情,需要更复杂的恢复。
会话过期是由Zookeeper集群管理的,不是由客户端管理的。当ZK客户端和ZK集群建立会话时,ZK集群会提供“timeout”的值。ZK集群使用这个值来决定客户端的会话时是否过期。在指定的会话超时期间内,如果集群听不到客户端,过期也会发生(i.e. 无心跳时)。在会话到期时,群集将删除该会话拥有的任何/所有短暂节点,并立即通知任何/所有连接的客户端该更改(以及监听这些znodes的监听者)。此时,过期会话的客户端仍然与群集断开连接,ZK客户端不会收到会话过期的通知,直到它能重连集群。直到ZK客户端与集群的TPC连接重连,否则客户端将保持断开状态,直到与群集重新建立TCP连接,此时过期会话的观察者将收到“会话过期”通知。
过期会话的观察者看到的过期会话的状态转换示例:
- ‘connected’:会话建立,客户端正在和集群交互(C/S 交互正在正常运行)
- …客户端从集群分区
- ‘disconnected’:客户端已丢失与群集的连接
- …time elapses,‘timeout’期限过后,集群使会话超时,客户端看不到任何内容,因为它与群集断开连接
- …time elapses:客户端重获和集群的网络级别的连接
- ‘expired’:最终客户端重连集群,收到过期通知
有没有简单的方法测试使session过期?
有的,Zookeeper句话持有一个session id和password。这个构造器被用于在完全应用程序失败后恢复会话。例如,一个应用可以连接ZK,保存session id和password到一个文件,重启,读取session id和密码,然后在没有丢失session和相应的节点情况下重连ZK。保证session id和密码不会被传到多个应用实例取决于程序员,否则会导致问题。
在测试用例中,我们想制造问题,所以显式地让连接到ZK的应用会话过期,保存session id和password,用之前的session id和password创建另一个ZK句柄,然后关闭新句柄。由于两个句柄都引用相同的会话,因此第二个句柄上的close将使会话无效,从而导致第一个句柄上出现SESSION_EXPIRED。
为什么NodeChildrenChanged和NodeDataChanged观察事件不会返回有关更改的更多信息?
当ZK服务器产生变化事件时,ZK服务器自己知道变化的是什么。在我们ZK的初始实现中,我们返回了变化事件的信息,但是它证明这不可能被正确地使用。可能有正确使用的方法,但是我们从来没见到过正确使用的案例。问题是观察被用于发现最新的变化。(不然,你需要周期性的获取)当程序员要求这个特性时,许多程序员似乎缺少的东西是观察是一次性触发器。观察以下数据改变的例子:一个进程在“/ a”上执行getData并将watch设置为“true”并获取“v1”,另一个进程将“/ a”更改为“v2”,并在将“/ a”更改为“v3”后立即执行。第一个过程会看到“/ a”被更改为“v2”,但不会知道“/ a”现在是“/ v3”。
升级Zookeeper的选择过程是什么?
有两种方法:1)完全重启或者2)滚动重启。
在完全重启的情况下,您可以暂存更新的代码/配置/等。。。停止整体中的所有服务器,切换代码/配置,然后重启ZK整体。如果你通过编程(一般的脚本,不是手动的)来完成重启,那么重启可以按秒的顺序完成。因此,在此期间客户端将失去与ZooKeeper集群的连接,但它看起来就像网络分区一样对客户端。所有存在的客户端会话会维护起来,并且只要ZK整体恢复回来就重新连接。很明显,这种方法的却待你是如果你遇到某个问题(在测试工具上测试/暂存这些更改总是一个好主意)集群可能停机时间超过预期。
第二个选择"rolling restart"更被多数用户偏好。在这种情况下,你在某个时间点升级ZK整体的一个服务器;关闭服务器,升级代码/配置/等,然后重启服务器。服务器将自动重新加入仲裁,使用当前ZK领导者更新其内部状态,并开始提供客户端会话。由于执行滚动重新启动而不是完全重启,管理员可以在升级过程中监视整体,如果遇到任何问题,可能会回滚。
如何调整ZooKeeper集合(集群)的大小?
通常,在确定要部署的ZooKeeper服务节点的数量(整体的大小)时,你需要从可靠性来考虑而不是性能。
可靠性:
单个ZooKeeper服务器(独立)本质上是一个没有可靠性的协调器(单个服务节点故障会导致ZK服务失效)。
3服务器集合(您需要跳转到3而不是2,因为ZK基于简单多数表决工作)允许单个服务器失败并且服务仍然可用。
因此,如果您希望可靠性至少达到3.我们通常建议在“在线”生产服务环境中使用5台服务器。 这允许您使1台服务器停止服务(比如计划维护),并且仍然能够在不中断服务的情况下维持其中一台服务器的意外中断。
性能:
添加ZK服务器时,写入性能实际上会降低,而读取性能会略有提高:zookeeperOver(Performance)
有关调查,请参阅此页面Patrick Hunt(http://twitter.com/phunt)查看了独立服务器和3号集合的操作延迟。您会注意到单个核心机器运行独立的ZK集合( 1台服务器)仍然能够每秒处理15k个请求。 这比大多数应用程序需要的数量级要大(如果他们正确使用ZooKeeper - 即作为协调服务,而不是数据库,文件存储,缓存等的替代…)
我可以在负载均衡器后面运行整体集群吗?
从套接字I / O角度看,分布式系统中有两种类型的服务器故障。
- 由于硬件故障和操作系统崩溃/挂起,Zookeeper守护程序挂起,临时/永久网络中断,网络交换机异常等导致服务器停机等等:由于没有响应实体,客户端无法立即找出故障。因此,zookeeper客户端必须依靠超时来识别故障。
- 死亡的zookeeper进程(守护进程):由于操作系统将响应关闭的TCP端口,客户端将在套接字连接时获得“连接拒绝”或在套接字I / O上获得“对等重置”。 客户能立即注意到另一端失败。
以下是ZK客户端在每种情况下对服务器的响应方式。
- 在这种情况下(前者),ZK客户端依赖于心跳算法。 ZK客户端在2/3的recv超时(Zookeeper_init)中检测到服务器故障,然后在每个recv超时周期重试相同的IP(如果只给出一个集合)。 如果给出两个以上的集合IP,ZK客户端将立即尝试下一个IP。
- 在这种情况下,ZK客户端将立即检测到故障,并且假设仅给出一个集合IP,则将每秒重试连接。 如果给出多个集合IP(大多数安装属于此类别),ZK客户端将立即重试下一个IP。
请注意,在这两种情况下,当指定了多个集合IP时,ZK客户端会立即重试下一个IP而没有延迟。
在某些安装中,最好在负载均衡器后面运行集合集群,例如硬件L4交换机,TCP反向代理或DNS循环,因为这样的设置允许用户简单地使用一个主机名或IP(或VIP)作为集合集群 ,有些还检测到服务器故障。
但是这些负载平衡器如何对服务器故障做出反应存在细微差别。
- 硬件L4负载均衡器:此设置涉及一个IP和一个主机名。 L4交换机通常会自行进行心跳检测,从而从其IP列表中删除不响应的主机。 但这也依赖于相同的故障检测超时方案。 L4可能会将您重定向到无响应的服务器。 如果硬件LB足够快地检测到服务器故障,则此设置将始终将您重定向到实时整体服务器。
- DNS循环:此设置涉及一个主机名和一个IP列表。 ZK客户端正确使用DNS查询返回的IP列表。 因此,此设置与zookeeper_init的多个主机名(IP)参数的工作方式相同。 缺点是当集合群集配置更改为服务器添加/删除时,可能需要一段时间来传播所有DNS服务器和DNS客户端缓存(例如,nscd)TTL问题中的DNS条目更改。
总之,DNS RR与集群IP参数列表一样好,除了集群重配置情况。
事实证明,DNS RR存在一个小问题。 如果您使用的是zktop.py之类的工具,则它不会处理DNS服务器返回的主机IP列表。
群集关闭时,ZK会话会发生什么?
想象一下,客户端以5秒的会话超时连接到ZK,管理员将整个ZK群集关闭以进行升级。 群集停机几分钟,然后重新启动。
在这种情况下,客户端能够重新连接并刷新其会话。 由于会话超时由领导者跟踪,因此当群集重新启动时,会话将以新的超时再次开始倒计时。 因此,只要客户端在选举领导者后的前5秒内连接,它将在没有到期的情况下重新连接,并且将保持其在停机之前具有的任何短暂节点。
当领导者崩溃并且选出新的领导者时,表现出同样的行为。 在极限情况下,如果领导者快速来回翻转,会话将永不过期,因为他们的计时器不断重置。

















 1801
1801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









