 Java集合框架:HashMap、HashTable、LinkedHashMap、TreeMap、Concurrenthashmap和SparseArray详解
Java集合框架:HashMap、HashTable、LinkedHashMap、TreeMap、Concurrenthashmap和SparseArray详解





 本文详细介绍了Java集合框架中的HashMap、HashTable、LinkedHashMap、TreeMap、Concurrenthashmap以及Android中的SparseArray,包括它们的数据结构、性能特点、实现原理以及适用场景。HashMap基于链表和数组实现,JDK1.8引入红黑树优化;HashTable线程安全但效率低;LinkedHashMap保持插入或访问顺序;TreeMap按键值排序;Concurrenthashmap适合多线程环境;SparseArray是Android优化过的轻量级HashMap,适用于<integer, object>键值对,节省内存。"
112479602,10322425,SAP Business One 安装常见问题及解决方案,"['ERP', 'SAP', '数据库管理', '系统安装', '企业资源规划']
本文详细介绍了Java集合框架中的HashMap、HashTable、LinkedHashMap、TreeMap、Concurrenthashmap以及Android中的SparseArray,包括它们的数据结构、性能特点、实现原理以及适用场景。HashMap基于链表和数组实现,JDK1.8引入红黑树优化;HashTable线程安全但效率低;LinkedHashMap保持插入或访问顺序;TreeMap按键值排序;Concurrenthashmap适合多线程环境;SparseArray是Android优化过的轻量级HashMap,适用于<integer, object>键值对,节省内存。"
112479602,10322425,SAP Business One 安装常见问题及解决方案,"['ERP', 'SAP', '数据库管理', '系统安装', '企业资源规划']
性能对比:https://www.jianshu.com/p/dd746074f390
数据结构之LinkedHashMap:https://www.jianshu.com/p/bbc8087bd9ce
一、HashMap:(无序 , 非并发类,不支持多线程访问, 链表的数组,拥有数组和链表的优点 允许设置空的key和value)
1、实现原理:链表+数组 + 红黑数(jdk1.8修改)(链地址法bucket)
2、HashMap 的核心算法-hash 函数的实现(高性能需要保证以下几点):
(1)hash 算法必须是高效的
(2)hash 值到内存地址(数组索引)的算法是快速的
(3)根据内存地址(数组索引)可以直接取得对应的值
**3、为什么数组大小为2的幂时hashmap访问的性能最高:**它的目的是让hashcode中过的“1”变的均匀一点,散列的本意就是要尽量均匀分布
4、HashMap 的 resize() 性能瓶颈:当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组(默认16)扩容;loadFactor的默认值为0.75;原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。哈希表每次扩容为原来的2倍。 JDK1.8对哈希碰撞后的拉链算法进行了优化, 当拉链上entry数量太多(超过8个)时,将链表重构为红黑树。
5、查询时间性能:HashMap的桶, 如果没有哈希碰撞, HashMap就是个数组,我说的是如果。 数组的查询时间复杂度是O(1),所以HashMap理想时间复杂度是O(1);如果所有数据都在同一个下标位置, 即N个数据组成链表,时间复杂度为O(n), 所以HashMap的最差时间复杂度为O(n)。如果链表达到8个元素时重构为红黑树,而红黑树的查询时间复杂度为O(logN), 所以这时HashMap的时间复杂度为O(logN)。
6、JDK1.8的修改:如果链表个数达到8个时,将链表修改为红黑树结构。使用的是数组+链表+红黑树的数据结构(当链表的深度达到8的时候,也就是默认阈值,就会自动扩容把链表转成红黑树的数据结构来把时间复杂度从O(N)变成O(logN)提高了效率)
7、hash碰撞:两个元素通过hash函数计算出的值是一样的,是同一个存储地址。当后面的元素要插入到这个地址时,发现已经被占用了,这时候就产生了hash冲突(Collision)。
解决hash冲突的方法主要有两种,
(1)开放寻址法(当一个Key通过hash函数获得对应的数组下标已被占用的时候,我们可以寻找下一个空档位置)
(2)链表法(hashmap使用这种方式)
两个key返回相同的hash值,定位到同一个数组下标位置,这时去判断当前下标是否有值,没有值就放在该位置,如果有值,依次遍历。如果是put,遍历到有相同的key,就替换掉原来的值,没有就将该值放入到链表头部(jdk1.8是放在头部);如果是get就依次遍历,遍历到有相同的key,就返回其值。否则返回空。
8、多线程并发下HashMap会发生死循环:
(1)put()操作的时候导致的多线程数据不一致
比如有两个线程A和B,首先A希望插入一个key-value对到HashMap中,首先计算记录所要落到的 hash桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的 hash桶索引和线程B要插入的记录计算出来的 hash桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为
(2)resize()而引起死循环
JDK1.8后,除了对hashmap增加红黑树结果外,对原有造成死锁的关键原因点(新table复制在头端添加元素)改进为依次在末端添加新的元素。虽然JDK1.8后添加红黑树改进了链表过长查询遍历慢问题和resize时出现导致put生成环形链表,get获取时死循环的bug,但还是非线性安全的,比如数据丢失等等。比较low的可以使用HashTable和调用Collections工具类的synchronizedMap()方法达到线程安全的目的。但由于synchronized是串行执行,在访问量很大的情况下效率很低,不推荐使用。因此多线程情况下还是建议使用concurrenthashmap。
HashMap 在高并发下引起的死循环
9、为什么String, Interger这样的wrapper类适合作为键?
String, Interger这样的wrapper类作为HashMap的键是再适合不过了,而且String最为常用。因为String是不可变的,也是final的,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不可变性还有其他的优点如线程安全。如果你可以仅仅通过将某个field声明成final就能保证hashCode是不变的,那么请这么做吧。因为获取对象的时候要用到equals()和hashCode()方法,那么键对象正确的重写这两个方法是非常重要的。如果两个不相等的对象返回不同的hashcode的话,那么碰撞的几率就会小些,这样就能提高HashMap的性能。
10、我们可以使用自定义的对象作为键吗?
这是前一个问题的延伸。当然你可能使用任何对象作为键,只要它遵守了equals()和hashCode()方法的定义规则,并且当对象插入到Map中之后将不会再改变了。如果这个自定义对象时不可变的,那么它已经满足了作为键的条件,因为当它创建之后就已经不能改变了。
二、HashTable:无序 ,并发类,支持多线程访问 不允许设置空的key和value
三、LinkedHashMap :有序,可设置按插入顺序或者按访问顺序 。 相当于在hashmap的基础上多增加一个链表记录顺序。提供了两种类型的顺序:元素插入的顺序 和 元素最近访问的顺序。可以通过下面构造函数指定排序方式。
/**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
四、TreeMap :有序,根据键值排序,默认升序,可实现comapre函数实现排序控制,使用红黑二叉树实现,不允许设置空的key和value。红黑树是一种平衡查找树,它的统计性能要由于平衡二叉树。有良好的最坏运行时间,可以在 O(log n) 时间内做查找、插入和删除,n 表示树中元素的个数。
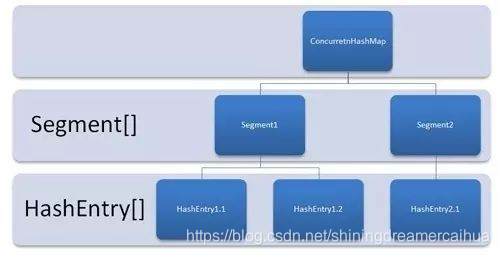
五、Concurrenthashmap:和 HashMap 非常类似,唯一的区别就是其中的核心数据如 value ,以及链表都是 volatile 修饰的,保证了获取时的可见性。原理上来说:ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。get不需要加锁,除非读取到空值才需要加锁重读。put方法只对定位到的 Segment 进行加锁。
HashMap?ConcurrentHashMap?相信看完这篇没人能难住你!
六、SparseArray
SparseArray是android里为<Interger,Object>这样的Hashmap而专门写的类,目的是提高内存效率,其核心是折半查找函数(binarySearch)
注意内存二字很重要,因为它仅仅提高内存效率,而不是提高执行效率,所以也决定它只适用于android系统(内存对android项目有多重要,地球人都知道)。
SparseArray有两个优点:
1.避免了自动装箱(auto-boxing)
2.数据结构不会依赖于外部对象映射。 我们知道HashMap 采用一种所谓的“Hash 算法”来决定每个元素的存储位置,存放的都是数组元素的引用,通过每个对象的
hash值来映射对象。而SparseArray则是用数组数据结构来保存映射,然后通过折半查找来找到对象。但其实一般来说,SparseArray执行效率比HashMap要慢一点,因为查找需要折半查找,而添加删除则需要在数组中执行,而HashMap都是通过外部映射。但相对来说影响不大,最主要是SparseArray不需要开辟内存空间来额外存储外部映射,从而节省内存。
3.总的看起来,SparseArray要比HashMap的数据结构简单的多。没有hashmap的node结点,也不需要迭代器来遍历。二分法查找在查找上更有优势。缺点就是它的key只支持int类型。显然在我们实际开发当中是不够的,因此也就有了ArrayMap了,ArrayMap的源码我们就不再分析了。实际上它的用法以及对数据的存储都和SparseArray一样,都是由两个数组来完成的,并且也是基于二分查找。不同的地方在于,ArrayMap的key可以是任意类型的。]
七、总结:
List特点:元素有放入顺序,元素可重复
Map特点:元素按键值对存储,无放入顺序
Set特点:元素无放入顺序,元素不可重复(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的)
List接口有三个实现类:LinkedList,ArrayList,Vector
LinkedList:底层基于链表实现,链表内存是散乱的,每一个元素存储本身内存地址的同时还存储下一个元素的地址。链表增删快,查找慢
ArrayList和Vector的区别:ArrayList是非线程安全的,效率高;Vector是基于线程安全的,效率低
Set接口有两个实现类:HashSet(底层由HashMap实现),LinkedHashSet
SortedSet接口有一个实现类:TreeSet(底层由平衡二叉树实现)
Query接口有一个实现类:LinkList
Map接口有三个实现类:HashMap,HashTable,LinkeHashMap
HashMap非线程安全,高效,支持null;HashTable线程安全,低效,不支持null
SortedMap有一个实现类:TreeMap
其实最主要的是,list是用来处理序列的,而set是用来处理集的。Map是知道的,存储的是键值对
set 一般无序不重复.map kv 结构 list 有序
参考:
HashMap原理分析(JDK1.8)
HashMap源码分析(JDK1.8)- 你该知道的都在这里了
jdk1.8 HashMap工作原理和扩容机制(源码解析)
Android中SparseArray,ArrayList,LinkedList,Set,HashMap,ArraySet
深入理解 hash 函数、HashMap、LinkedHashMap、TreeMap 【上】
深入理解 hash 函数、HashMap、LinkedHashMap、TreeMap 【中】
SparseArray 与 HashMap

















 378
378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









