







1.简介
长期以来,优化YOLO框架的网络架构一直是提升目标检测性能的关键,而以往的研究大多聚焦于基于卷积神经网络(CNN)的改进。这是因为基于注意力机制的模型通常难以达到与基于CNN的模型相媲美的速度。然而,本文提出了一种以注意力机制为核心的YOLO框架——YOLOv12。该框架不仅充分利用了注意力机制在性能上的优势,还在推理速度上与之前基于CNN的YOLO框架相当,从而在实时性与精度之间实现了更好的平衡。
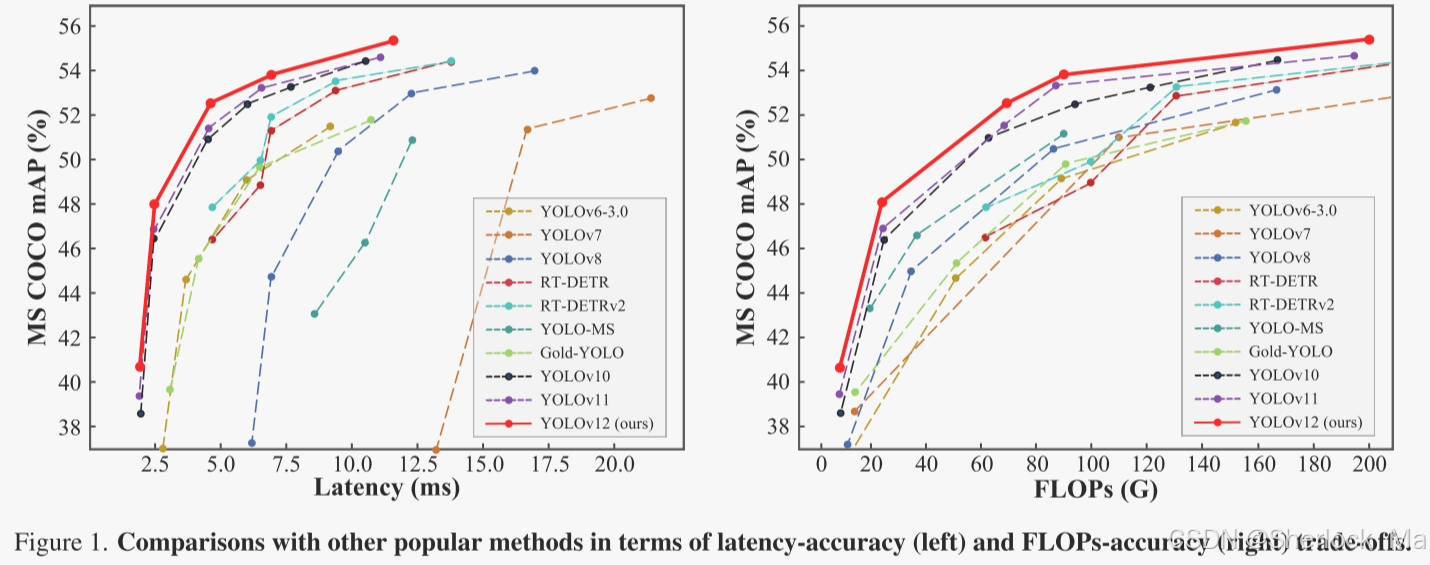
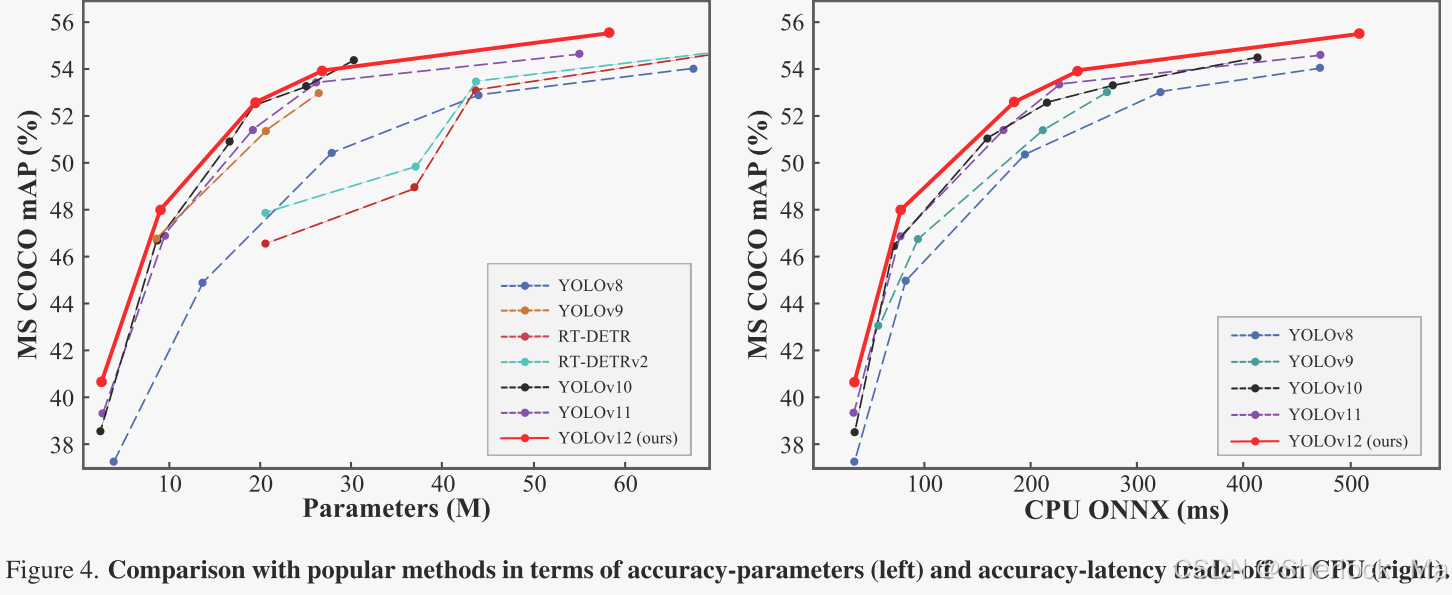
YOLOv12在准确性和速度方面超越了所有流行的实时对象检测器。例如,在T4 GPU上,YOLOv 12-N在推理延迟为1.64 ms的情况下实现了40.6%的mAP,在速度相当的情况下比高级YOLOv10-N /YOLOv11-N高出2.1%/1.2%的mAP。这一优势也适用于其他模型比例。YOLOv12还优于端到端实时检测器,如RT-DETR /RTDETRv2:YOLOv 12-S在仅使用36%的计算和45%的参数情况下比RT-DETR-R18 /RT-DETRv 2 R18快42%。
论文地址: [2502.12524] YOLOv12: Attention-Centric Real-Time Object Detectors
github地址:https://github.com/sunsmarterjie/yolov12
-
-
2.论文详解
摘要
实时目标检测由于其低延迟特性而一直吸引着人们的极大关注,其中,YOLO系列有效地在延迟和准确性之间建立了最佳平衡,从而主导了该领域。尽管以注意力为中心的视觉Transformer(ViT)架构已被证明具有更强的建模能力,即使在小模型中也是如此,但大多数架构设计仍然主要关注CNN。
这种情况的主要原因在于注意力机制的效率低下,这来自两个主要因素:二次计算复杂度和注意力机制的低效内存访问操作(后者是FlashAttention解决的主要问题)。因此,在类似的计算预算下,基于CNN的架构比基于注意力的架构的性能高出1.3 倍,这大大限制了YOLO系统中注意力机制的采用,其中高推理速度至关重要。
本文旨在解决这些挑战,并进一步建立一个以注意力为中心的YOLO框架,即YOLOv 12。
作者介绍了三项关键改进。
- 首先,作者提出了一个简单而有效的区域注意力模块(A2),它保持了一个大的感受野,同时以一种非常简单的方式降低了注意力的计算复杂度,从而提高了速度。
- 其次,作者引入剩余有效层聚合网络(R-ELAN)来解决注意力(主要是大规模模型)带来的优化挑战。R-ELAN在原始ELAN的基础上引入了两项改进:(i)采用缩放技术的块级残差设计和(ii)重新设计的特征聚合方法。
- 第三,作者做了一些架构上的改进,以适应YOLO系统。升级了传统的以注意力为中心的架构,包括:引入FlashAttention来克服注意力的内存访问问题,去除位置编码等设计,使模型快速干净,将MLP比率从4调整为1.2,以平衡注意力和前馈网络之间的计算,以获得更好的性能,减少堆叠块的深度,以便于优化,并且尽可能多地利用卷积算子来平衡它们的计算效率。
基于上述设计,作者开发了一个新的实时检测器系列,其具有5个模型尺度:YOLOv 12-N,S,M,L和X。作者进行了广泛的实验,证明YOLOv 12在这些尺度上的延迟-准确性和FLOPs-准确性权衡方面比以前流行的模型有了显着的改进
-
方法
效率分析
注意力机制虽然在捕获全局依赖性和促进诸如自然语言处理和计算机视觉之类的任务方面非常有效,但其固有地比卷积神经网络(CNN)慢。两个主要因素造成了这种速度上的差异。
- 复杂性
- 首先,自注意操作的计算复杂度与输入序列长度L成二次比例。具体地,对于具有长度L和特征维数d的输入序列,注意矩阵的计算需要
次运算,因为每个标记需要注意到每一个其它标记。相比之下,CNNs中卷积运算的复杂度相对于空间或时间维度线性缩放,即,
,其中k是内核大小,并且通常远小于L。结果,自注意在计算上变得复杂,尤其是对于诸如高分辨率图像或长序列的大输入。
- 此外,另一个重要因素是大多数基于注意力的视觉变换器,由于它们的复杂设计(例如,Swin Transformer中的窗口划分/反转)和引入附加模块(例如,位置编码),逐渐累积速度开销,导致总体速度低于CNN架构。本文设计的模块利用简单干净的操作来实现模型,最大限度地保证了效率。
- 首先,自注意操作的计算复杂度与输入序列长度L成二次比例。具体地,对于具有长度L和特征维数d的输入序列,注意矩阵的计算需要
- 计算效率。第二,在注意力计算处理中,存储器访问模式与CNN相比效率较低。具体地说,在自注意期间,需要将高速GPU SRAM中存储的中间图,例如注意图(
)和softmax图(L × L)转移到高带宽GPU存储器(HBM)中,并且在计算期间被检索,而前者的读取和写入速度是后者的10倍以上,从而导致显著的存储器访问开销。此外,与使用结构化和局部化的存储器访问的CNN相比,注意力中的不规则存储器访问模式引入了进一步的延迟。CNN受益于其固定的感受野和滑动窗口操作,能够实现高效的存储器缓存和减少的延迟。
这两个因素,二次计算复杂度和低效的存储器访问,一起使得注意力机制比CNNs慢,特别是在实时或资源受限的情况下。解决这些限制已经成为一个关键的研究领域,采用诸如稀疏注意机制和内存高效近似(例如,Linformer或Performer)。
Area Attention
降低普通注意力计算成本的一种简单方法是使用线性注意力机制,它将普通注意力的复杂性从二次降低到线性。然而,线性注意力受到全局依赖性退化,不稳定性和分布敏感性的影响。此外,由于低秩瓶颈,当应用于输入分辨率为640 × 640的YOLO时,它仅提供有限的速度优势。
有效降低复杂性的替代方法是局部注意力机制(例如,移位窗口,交叉注意力和轴向注意力),如图2所示,它将全局注意力转换为局部注意力,从而降低了计算成本。然而,将特征图划分为窗口可能会引入开销或减少感受野,从而影响速度和准确性。
在这项研究中,作者提出了简单而有效的区域注意力模块。如图2所示,分辨率为(H,W)的特征图被分成大小为(,W)或(H,
)的l个片段。这消除了显式窗口分区,只需要一个简单的整形操作,从而实现更快的速度。作者根据经验将l的默认值设置为4,将感受野减少到原始的1/4,但它仍然保持大的感受野。通过这种方法,注意机制的计算成本从
降低到
。有趣的是,作者发现这种修改对性能只有轻微的影响,但显著提高了速度。
简单来说:YOLOv12采用简单的水平或垂直划分方式,避免了复杂的窗口划分和反转操作。这种划分方式不仅简化了计算过程,还减少了内存开销。

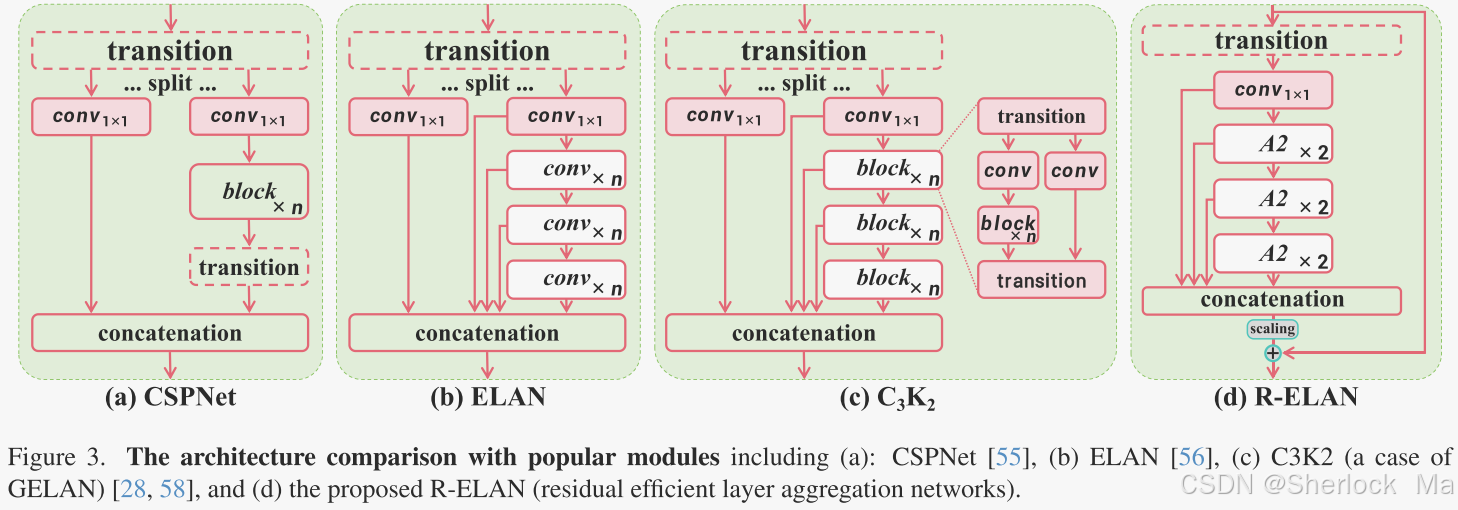
残差有效层聚合网络(R-ELAN)
高效层聚合网络(ELAN)旨在改善特征聚合。如图3(B)所示,ELAN分割过渡层的输出(1 × 1卷积),通过多个模块处理一个分割,然后连接所有输出,并应用另一个过渡层(1 × 1卷积)来对齐维度。然而,这种架构可能会引入不稳定性。作者认为,这样的设计会导致梯度阻塞,缺乏从输入到输出的剩余连接。
为了解决这个问题,作者提出了剩余有效层聚合网络(R-ELAN),图3(d)。相比之下,作者在整个块中引入了从输入到输出的残差快捷方式,其带有缩放因子(默认为0.01)。这种设计类似于层缩放,引入层缩放来构建深度视觉Transformer。然而,对每个区域的注意力应用层缩放将无法克服优化挑战,并会导致延迟减缓。
作者还设计了一种新的聚合方法,如图3(d)所示。最初的ELAN层处理模块的输入,首先将其通过过渡层,然后将其分为两部分。一个部分由后续块进一步处理,最后两个部分连接起来产生输出。相比之下,作者的设计应用了一个过渡层来调整通道尺寸,并产生一个单一的特征图。然后,通过随后的块处理该特征图,然后进行级联,形成瓶颈结构。这种方法不仅保留了原有的功能集成能力,但也减少了计算成本和参数/内存的使用。
-
-
实验
作者在表1中给出了YOLOv12和其他流行的实时检测器之间的性能比较。
- 对于N-尺寸模型,YOLOv 12-N在mAP方面的性能分别比YOLOv 6 -3.0-N、YOLOv 8-N、YOLOv 10-N和YOLOv 11高出3.6%、3.3%、2.1%和1.2%,同时保持相似或甚至更少的计算和参数,并实现了1.64 ms/图像的快速延迟。
- 对于S-尺寸模型,YOLOv 12-S具有21.4G FLOPs和9.3M参数,可实现48.0 mAP和2.61 ms/图像延迟。它比YOLOv 8-S,YOLOv 9-S,YOLOv 10-S和YOLOv 11-S分别高出3.0%,1.2%,1.7%和1.1%,同时保持相似或更少的计算。与端到端检测器RT-DETR-R18 /RT-DETRv 2 R18相比,YOLOv 12-S实现了更好的性能,但具有更好的推理速度、更低的计算成本和更少的参数。
- 对于M-尺寸模型,YOLOv 12-M采用67.5G FLOPs和20.2M参数,实现了52.5 mAP性能和4.86 ms/图像速度。YOLOv 12-S与Gold-YOLO-M、YOLOv 8-M、YOLOv 9-M、YOLOv 10、YOLOv 11 和RT-DETR-R34 /RT-DETRv 2-R34相比具有优势。
- 对于L-尺寸模型,YOLOv 12-L的FLOP数甚至比YOLOv 10-L少31.4G。YOLOv 12L在FLOP和参数相当的情况下,比YOLOv 11快0.4% mAP。此外,YOLOv 12-L的性能也优于RTDERT-R50 /RT-DERTv 2-R50 ,其速度更快,浮点数(FLOP)更少(34.6%),参数更少(37.1%)。
- 对于X-尺寸模型,YOLOv 12-X在速度、FLOPs和参数相当的情况下,分别显著优于YOLOv 10-X /YOLOv 11-X 0.8%和0.6%。YOLOv 12-X再次击败RT-DETR-R101 /RT-DETRv 2-R101,速度更快,浮点运算次数更少(23.4%),参数更少(22.2%)。
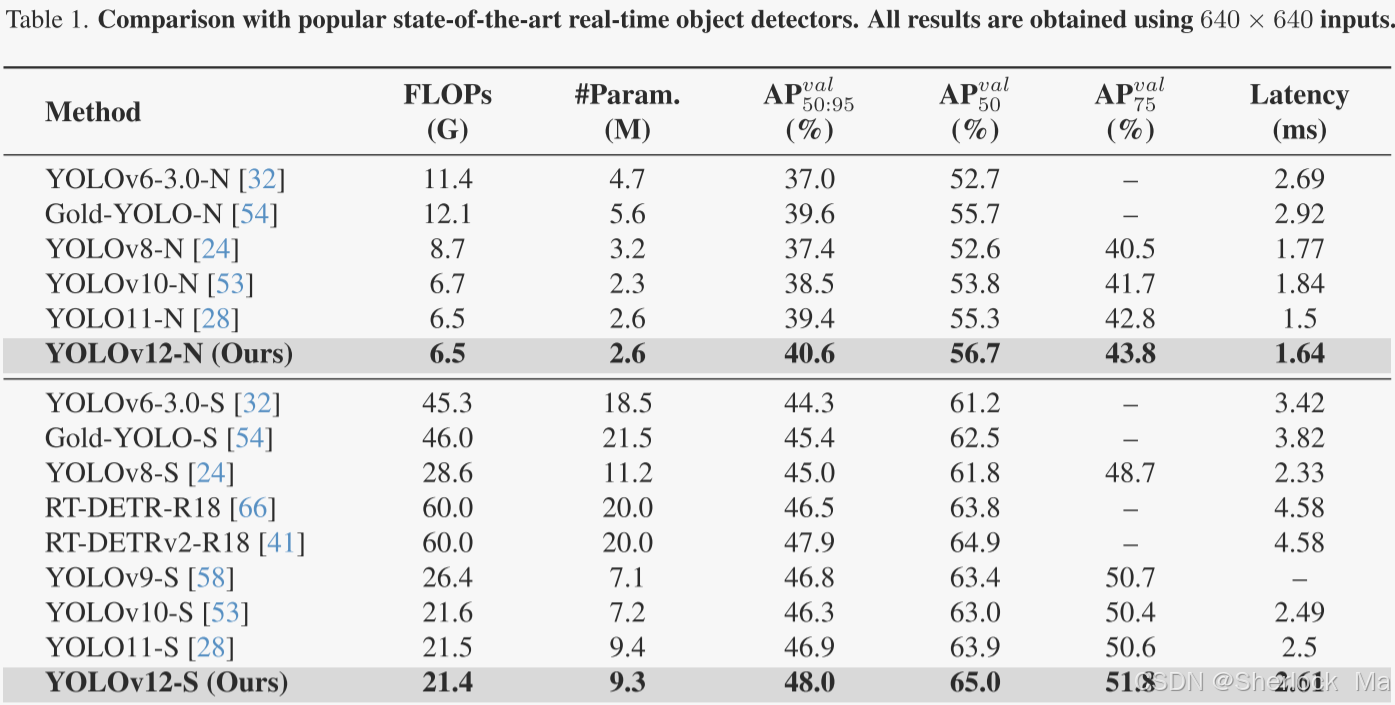
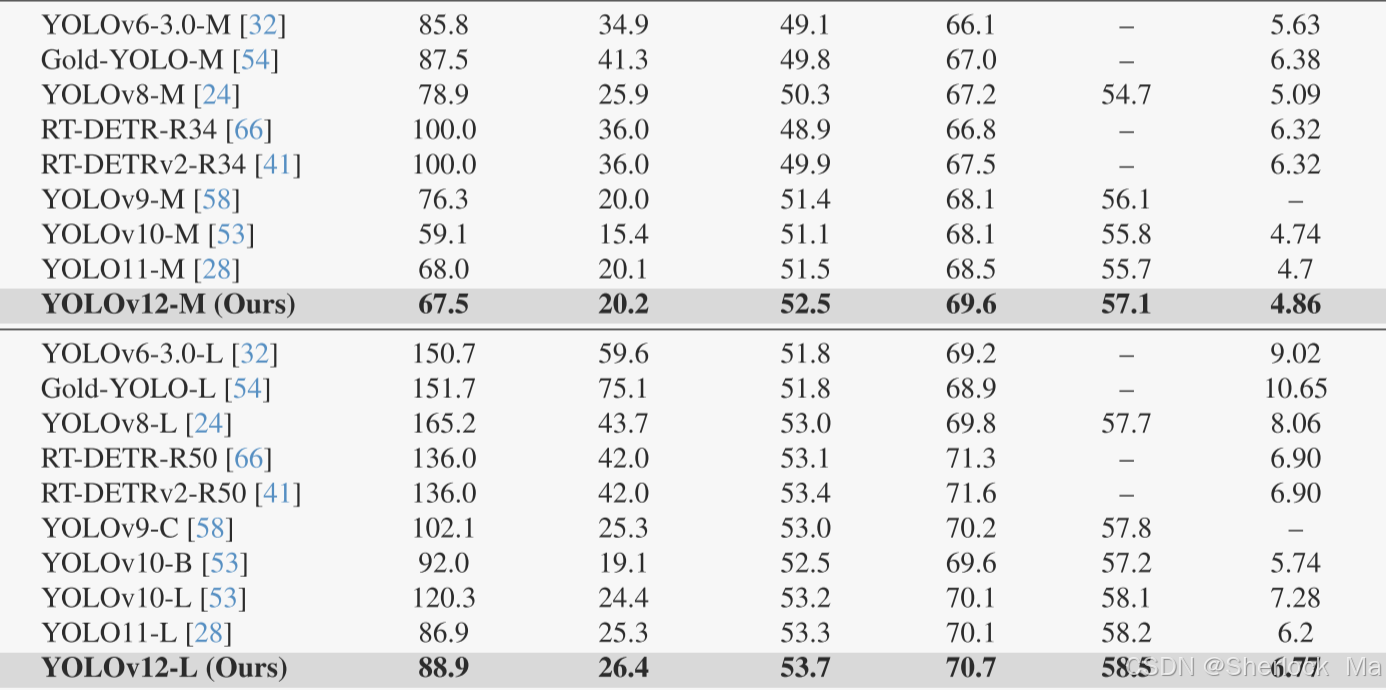

图4左侧子图显示了与常用方法的准确度-参数权衡比较,其中YOLOv 12建立了超过对应方法的优势边界,甚至超过了YOLOv 10,YOLOv 10的特征是参数明显较少,显示了YOLOv 12的有效性。作者在右侧子图中的CPU上比较了YOLOv 12与以前的YOLO版本的推理延迟(所有结果均在英特尔酷睿i7- 10700K@3.80GHz上测量)。如图所示,YOLOv 12超越了其他竞争对手,具有更大的优势,突出了其在不同硬件平台上的效率。
-
-
3.代码
环境配置
下载flash-attn,放在主目录下即可
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
配置虚拟环境,建议使用Python3.11
conda create -n yolov12 python=3.11
conda activate yolov12
安装所需库
pip install -r requirements.txt
pip install -e .下载权重,我这里以yolov12-X为例
| Model | size (pixels) | mAPval 50-95 | Speed T4 TensorRT10 | params (M) | FLOPs (G) |
|---|---|---|---|---|---|
| YOLO12n | 640 | 40.6 | 1.64 | 2.6 | 6.5 |
| YOLO12s | 640 | 48.0 | 2.61 | 9.3 | 21.4 |
| YOLO12m | 640 | 52.5 | 4.86 | 20.2 | 67.5 |
| YOLO12l | 640 | 53.7 | 6.77 | 26.4 | 88.9 |
| YOLO12x | 640 | 55.2 | 11.79 | 59.1 | 199.0 |
下载coco数据集,可以使用自己的,也可以运行以下代码自动下载
from ultralytics import YOLO
model = YOLO('yolov12x.pt')
results = model.val(data='coco.yaml', save_json=True)
print(results.box.map) # Print mAP50-95-
预测
from ultralytics import YOLO
model = YOLO('yolov12x.pt')
results = model.predict(source="path/to/image.jpg", conf=0.25)
for r in results:
print(r.boxes.data) # 打印边界框
results[0].show() # 显示结果-
训练
from ultralytics import YOLO
model = YOLO('yolov12x.yaml')
# Train the model
results = model.train(
data='coco.yaml',
epochs=600,
batch=256,
imgsz=640,
scale=0.5, # S:0.9; M:0.9; L:0.9; X:0.9
mosaic=1.0,
mixup=0.0, # S:0.05; M:0.15; L:0.15; X:0.2
copy_paste=0.1, # S:0.15; M:0.4; L:0.5; X:0.6
device="0",
)
# Evaluate model performance on the validation set
metrics = model.val()
# Perform object detection on an image
results = model("path/to/image.jpg")
results[0].show() # 显示结果-
模型
模型整体架构如下:
from n params module arguments
0 -1 1 2784 ultralytics.nn.modules.conv.Conv [3, 96, 3, 2]
1 -1 1 166272 ultralytics.nn.modules.conv.Conv [96, 192, 3, 2]
2 -1 2 389760 ultralytics.nn.modules.block.C3k2 [192, 384, 2, True, 0.25]
3 -1 1 1327872 ultralytics.nn.modules.conv.Conv [384, 384, 3, 2]
4 -1 2 1553664 ultralytics.nn.modules.block.C3k2 [384, 768, 2, True, 0.25]
5 -1 1 5309952 ultralytics.nn.modules.conv.Conv [768, 768, 3, 2]
6 -1 4 9512128 ultralytics.nn.modules.block.A2C2f [768, 768, 4, True, 4, True, 1.2]
7 -1 1 5309952 ultralytics.nn.modules.conv.Conv [768, 768, 3, 2]
8 -1 4 9512128 ultralytics.nn.modules.block.A2C2f [768, 768, 4, True, 1, True, 1.2]
9 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
10 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
11 -1 2 4727040 ultralytics.nn.modules.block.A2C2f [1536, 768, 2, False, -1, True, 1.2]
12 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
13 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
14 -1 2 1331328 ultralytics.nn.modules.block.A2C2f [1536, 384, 2, False, -1, True, 1.2]
15 -1 1 1327872 ultralytics.nn.modules.conv.Conv [384, 384, 3, 2]
16 [-1, 11] 1 0 ultralytics.nn.modules.conv.Concat [1]
17 -1 2 4579584 ultralytics.nn.modules.block.A2C2f [1152, 768, 2, False, -1, True, 1.2]
18 -1 1 5309952 ultralytics.nn.modules.conv.Conv [768, 768, 3, 2]
19 [-1, 8] 1 0 ultralytics.nn.modules.conv.Concat [1]
20 -1 2 5612544 ultralytics.nn.modules.block.C3k2 [1536, 768, 2, True]
21 [14, 17, 20] 1 3237952 ultralytics.nn.modules.head.Detect [80, [384, 768, 768]]
YOLOv12x summary: 831 layers, 59,210,784 parameters, 59,210,768 gradients, 200.3 GFLOPs其中,上面的各层参数含义如下:
层数 数据来源(-1表示来自上层) 有几个该模块 参数量 模块名称 传递的参数(具体含义需参考具体模块)
6 -1 4 9512128 ultralytics.nn.modules.block.A2C2f [768, 768, 4, True, 4, True, 1.2]-
整体框架如下: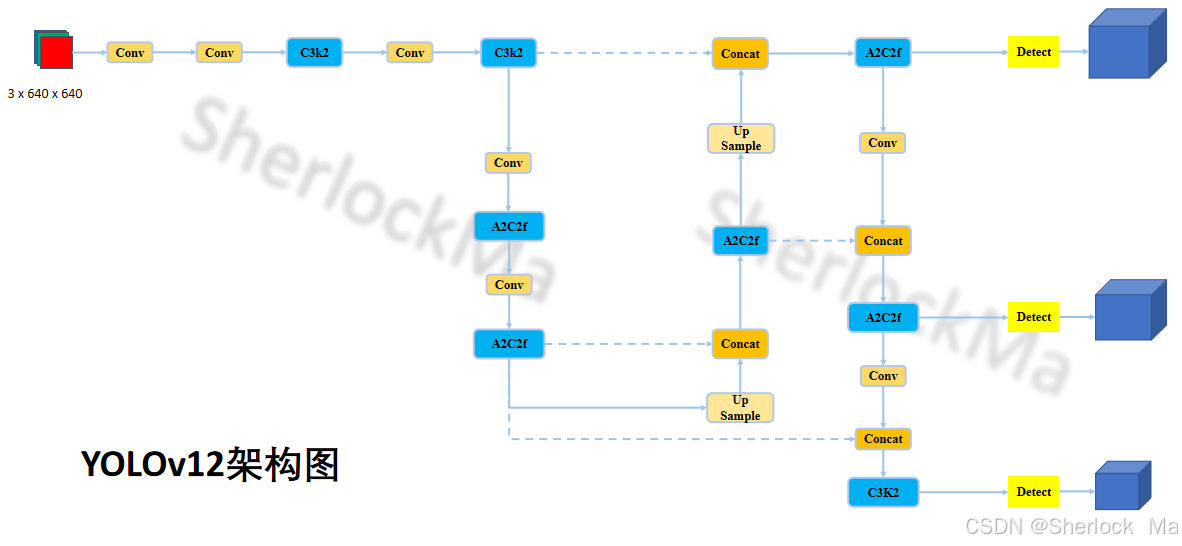
-
A2C2f 模块
使用带区域注意(Area Attn)的 ABlock 块进行残差增强特征提取。也称为 R-ELAN。该类扩展了 C2f 模块,纳入了用于快速注意机制和特征提取的 ABlock 块。
class A2C2f(nn.Module):
"""
A2C2f 模块,使用带区域注意的 ABlock 块进行残差增强特征提取。也称为 R-ELAN
该类扩展了 C2f 模块,纳入了用于快速注意机制和特征提取的 ABlock 块。
Attributes:
c1 (int): 输入通道数
c2 (int): 输出通道数
n (int, optional): 要堆叠的 2xABlock 模块数量。默认为 1;
a2 (bool, optional): 是否使用区域注意力。默认为 True;
area (int, optional): 特征地图划分的区域数。默认为 1;
residual (bool, optional): 是否使用残差(带图层比例)。默认为 “False”;
mlp_ratio (float, optional): MLP 扩展比(或 MLP 隐藏维度比)。默认为 1.2;
e (float, optional): R-ELAN 模块的扩展比率。默认为 0.5;
g (int, optional): 分组卷积的组数。默认为 1;
shortcut (bool, optional): 是否使用快捷连接。默认为 True;
Methods:
forward: 通过 A2C2f 模块执行前向传播。
Examples:
>>> import torch
>>> from ultralytics.nn.modules import A2C2f
>>> model = A2C2f(c1=64, c2=64, n=2, a2=True, area=4, residual=True, e=0.5)
>>> x = torch.randn(2, 64, 128, 128)
>>> output = model(x)
>>> print(output.shape)
"""
def __init__(self, c1, c2, n=1, a2=True, area=1, residual=False, mlp_ratio=2.0, e=0.5, g=1, shortcut=True):
super().__init__()
c_ = int(c2 * e) # hidden channels
assert c_ % 32 == 0, "Dimension of ABlock be a multiple of 32."
# num_heads = c_ // 64 if c_ // 64 >= 2 else c_ // 32
num_heads = c_ // 32
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv((1 + n) * c_, c2, 1) # optional act=FReLU(c2)
init_values = 0.01 # or smaller
self.gamma = nn.Parameter(init_values * torch.ones((c2)), requires_grad=True) if a2 and residual else None
self.m = nn.ModuleList( # 创建模块列表m,根据a2标志选择不同的块(ABlock或C3k)。
nn.Sequential(*(ABlock(c_, num_heads, mlp_ratio, area) for _ in range(2))) if a2 else C3k(c_, c_, 2, shortcut, g) for _ in range(n)
)
def forward(self, x):
"""Forward pass through R-ELAN layer."""
y = [self.cv1(x)]
y.extend(m(y[-1]) for m in self.m) # 遍历self.m中的模块,依次对y的最后一个元素进行处理并扩展到y中。
if self.gamma is not None: # 如果self.gamma存在,则将x与经过cv2层处理后的y连接结果加权相加返回
return x + self.gamma.view(1, -1, 1, 1) * self.cv2(torch.cat(y, 1))
return self.cv2(torch.cat(y, 1))下面这段代码定义了一个 R-ELAN 层的前向传播函数 forward,它是YOLOv12中骨干网络(Backbone)的核心模块。R-ELAN 是一种改进的残差模块,结合了残差连接和层间特征聚合,用于增强特征提取能力和模型的训练稳定性。
def forward(self, x):
"""Forward pass through R-ELAN layer."""
y = [self.cv1(x)]
y.extend(m(y[-1]) for m in self.m) # 遍历self.m中的模块,依次对y的最后一个元素进行处理并扩展到y中。
if self.gamma is not None: # 如果self.gamma存在,则将x与经过cv2层处理后的y连接结果加权相加返回
return x + self.gamma.view(1, -1, 1, 1) * self.cv2(torch.cat(y, 1))
return self.cv2(torch.cat(y, 1))其中:
-
y.extend(m(y[-1]) for m in self.m)-
self.m是一个模块列表,包含多个子模块(通常是卷积层或其他特征提取模块)。 -
这一行代码的作用是:依次取出
self.m中的每个模块m,对y的最后一个元素(即上一次处理的结果)进行处理,并将结果追加到y中。 -
通过这种方式,
y逐渐积累了多层特征,形成了一个特征金字塔结构。
-
-
torch.cat(y, 1)-
将列表
y中的所有特征张量沿着通道维度(dim=1)拼接起来。 -
这一步将不同层次的特征融合在一起,增强了特征的丰富性。
-
-
return x + self.gamma.view(1, -1, 1, 1) * self.cv2(torch.cat(y, 1))
-
这种加权残差连接有助于模型在训练过程中保持稳定,并且可以动态调整残差的贡献。
-
可以参考下图理解:

其中,ABlock如下:
class ABlock(nn.Module):
"""
ABlock 类实现了具有有效特征提取功能的区域注意力模块。
该类封装了应用多头注意力的功能,其特征图被划分为区域和前馈神经网络层。
Attributes:
dim (int): 隐藏通道数;
num_heads (int): 注意力机制分为多少个头;
mlp_ratio (float, optional): MLP 扩展比(或 MLP 隐藏维度比)。默认为 1.2;
area (int, optional): 特征地图划分的区域数。 默认为 1。
Methods:
forward: 通过 AB 块执行前向传递,应用区域注意和前馈层。
Examples:
Create a ABlock and perform a forward pass
>>> model = ABlock(dim=64, num_heads=2, mlp_ratio=1.2, area=4)
>>> x = torch.randn(2, 64, 128, 128)
>>> output = model(x)
>>> print(output.shape)
Notes:
建议 dim//num_heads 为 32 或 64 的倍数。
"""
def __init__(self, dim, num_heads, mlp_ratio=1.2, area=1):
"""用区域注意层和前馈层初始化 ABlock,以加快特征提取速度。"""
super().__init__()
self.attn = AAttn(dim, num_heads=num_heads, area=area)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = nn.Sequential(Conv(dim, mlp_hidden_dim, 1), Conv(mlp_hidden_dim, dim, 1, act=False))
self.apply(self._init_weights)
def _init_weights(self, m):
"""Initialize weights using a truncated normal distribution."""
if isinstance(m, nn.Conv2d):
nn.init.trunc_normal_(m.weight, std=0.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
"""Executes a forward pass through ABlock, applying area-attention and feed-forward layers to the input tensor."""
x = x + self.attn(x)
x = x + self.mlp(x)
return xclass AAttn(nn.Module):
"""
区域注意力模块,要求闪烁注意力。
Attributes:
dim (int): 隐藏通道数;
num_heads (int): 注意力机制分为多少个头;
area (int, optional): 特征图划分的区域数。默认为 1。
Methods:
forward: 执行Area Attn后,对输入张量进行前向处理并输出张量。
Examples:
>>> import torch
>>> from ultralytics.nn.modules import AAttn
>>> model = AAttn(dim=64, num_heads=2, area=4)
>>> x = torch.randn(2, 64, 128, 128)
>>> output = model(x)
>>> print(output.shape)
Notes:
建议 dim//num_heads 为 32 或 64 的倍数。
"""
def __init__(self, dim, num_heads, area=1):
"""Initializes the area-attention module, a simple yet efficient attention module for YOLO."""
super().__init__()
self.area = area
self.num_heads = num_heads
self.head_dim = head_dim = dim // num_heads
all_head_dim = head_dim * self.num_heads
self.qkv = Conv(dim, all_head_dim * 3, 1, act=False)
self.proj = Conv(all_head_dim, dim, 1, act=False)
self.pe = Conv(all_head_dim, dim, 7, 1, 3, g=dim, act=False)
def forward(self, x):
"""Processes the input tensor 'x' through the area-attention"""
B, C, H, W = x.shape
N = H * W
qkv = self.qkv(x).flatten(2).transpose(1, 2)
if self.area > 1: # 拆分窗口,调整 qkv 的形状。 ->[B*A,H*W//A,C*3]
qkv = qkv.reshape(B * self.area, N // self.area, C * 3)
B, N, _ = qkv.shape
q, k, v = qkv.view(B, N, self.num_heads, self.head_dim * 3).split( # 拆分QKV
[self.head_dim, self.head_dim, self.head_dim], dim=3
)
if x.is_cuda and USE_FLASH_ATTN: # 根据是否使用 CUDA 和 USE_FLASH_ATTN 选择不同的注意力计算方式。
x = flash_attn_func(
q.contiguous().half(),
k.contiguous().half(),
v.contiguous().half()
).to(q.dtype)
elif x.is_cuda and not USE_FLASH_ATTN:
x = sdpa(
q.permute(0, 2, 1, 3).contiguous(),
k.permute(0, 2, 1, 3).contiguous(),
v.permute(0, 2, 1, 3).contiguous(),
attn_mask=None,
dropout_p=0.0,
is_causal=False
)
x = x.permute(0, 2, 1, 3)
else:
q = q.permute(0, 2, 3, 1)
k = k.permute(0, 2, 3, 1)
v = v.permute(0, 2, 3, 1)
attn = (q.transpose(-2, -1) @ k) * (self.head_dim ** -0.5)
max_attn = attn.max(dim=-1, keepdim=True).values
exp_attn = torch.exp(attn - max_attn)
attn = exp_attn / exp_attn.sum(dim=-1, keepdim=True)
x = (v @ attn.transpose(-2, -1))
x = x.permute(0, 3, 1, 2)
v = v.permute(0, 3, 1, 2)
if self.area > 1:
x = x.reshape(B // self.area, N * self.area, C)
v = v.reshape(B // self.area, N * self.area, C)
B, N, _ = x.shape
x = x.reshape(B, H, W, C).permute(0, 3, 1, 2)
v = v.reshape(B, H, W, C).permute(0, 3, 1, 2)
x = x + self.pe(v) # 添加位置编码并进行投影。
x = self.proj(x)
return x其中,下面的代码是YOLOv12中Area Attention机制的核心操作之一,它展示了如何通过简单地重塑张量来实现区域划分。
-
self.area:区域数量,表示特征图被划分为多少个区域。例如,如果特征图被划分为4个区域,则self.area = 4。 -
N // self.area:每个区域包含的特征点数为N // self.area。这意味着特征图被均匀地划分为多个区域,每个区域处理一部分特征点。 -
B * self.area:将每个批次的数据划分为self.area个区域,因此总的区域数量为B * self.area。经过这样操作后,各个area的信息不互通,不会相互计算
qkv = qkv.reshape(B * self.area, N // self.area, C * 3)-
C3K2模块
可见其本质都是bottleneck模块,因此我们直接看bottleneck部分
class C3k2(C2f):
"""用 2 次卷积更快地实现 CSP bottleneck。"""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
"""初始化 C3k2 模块,这是一个速度更快的 CSP bottleneck模块,带有 2 个卷积和可选的 C3k 块。"""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n)
)
class C3k(C3):
"""C3k 是一个 CSP bottleneck模块,可定制内核大小,用于神经网络的特征提取。"""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3):
"""使用指定通道、层数和配置初始化 C3k 模块。"""
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
# self.m = nn.Sequential(*(RepBottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))这段代码定义了一个标准的 Bottleneck 模块,它是深度学习中常见的残差结构,广泛应用于卷积神经网络(如ResNet和YOLO系列)中。Bottleneck模块的核心思想是通过减少中间层的通道数来降低计算复杂度,同时保持网络的性能。其中:
-
cv1: 第一个卷积层,将输入通道数c1映射到中间通道数c_。 -
cv2: 第二个卷积层,将中间通道数c_映射到输出通道数c2。
class Bottleneck(nn.Module):
"""标准 bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""初始化标准bottleneck模块,可选快捷连接和可配置参数。"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""Applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))-
-
4.总结
YOLOv12 是一种以注意力机制为核心的实时目标检测模型,代表了YOLO系列在性能与效率平衡上的最新进展。它摒弃了传统的基于卷积神经网络(CNN)的架构,转而采用创新的注意力机制,显著提升了检测精度,同时保持了与前代版本相当的推理速度。在实验中,YOLOv12 在多个标准数据集上均取得了优异的性能,同时在延迟和精度之间实现了良好的平衡。
YOLOv12 的核心创新之一是引入了区域注意力(Area Attention)机制。这一机制通过将特征图划分为多个区域进行独立计算,大幅降低了计算复杂度,同时保留了全局感受野。与传统的全局注意力或窗口注意力不同,Area Attention 结合了简单高效的区域划分和 FlashAttention 技术,进一步优化了计算效率,使其在实时目标检测任务中表现出色。
在骨干网络方面,YOLOv12 采用了残差高效层聚合网络(R-ELAN),通过残差连接和层间特征聚合,增强了特征提取能力并提高了训练稳定性。R-ELAN 结构结合了多尺度特征融合和可学习的加权残差连接,使得模型能够更好地捕捉复杂场景中的目标信息。
总体而言,YOLOv12 通过引入注意力机制和优化网络架构,在实时目标检测领域实现了重大突破。它不仅提升了模型的检测精度,还保持了高效的推理速度,使其成为当前最先进的目标检测模型之一,尤其适用于对实时性和精度要求较高的应用场景。
如果你觉得我的内容对你有帮助,或者让你眼前一亮,不妨点个赞、收藏一下,甚至关注我哦!你的每一个点赞和关注都是对我最大的支持,也是我继续努力的动力!感谢你的陪伴,让我们一起进步,探索更多知识的奥秘!💖

















 197
197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









