







1.简介
正如计算机视觉和自然语言处理从两个独立的学科走向统一的学科一样,现在,大语言模型和扩散模型(或者说理解与生成)正在走向统一。
在过去的几年里,多模态智能的两个关键支柱--理解和生成--取得了显著的进步。对于多模态理解,可以使用像LLaVA已经在视觉语言任务(例如视觉问答(VQA))中表现出了卓越的能力。对于视觉生成的另一支柱,降噪扩散概率模型(DDPM)彻底改变了传统的生成范式,在文本到图像/视频生成方面实现了前所未有的性能。
最近的论文试图从这两个不同的领域组装模型,以形成一个统一的系统,可以处理多模态理解和生成。然而,现有的尝试主要是独立地处理每个域,并且通常涉及单独负责理解和生成的各个模型。这激发了一个研究问题:一个单一的Transformer可以处理多模态理解和生成?
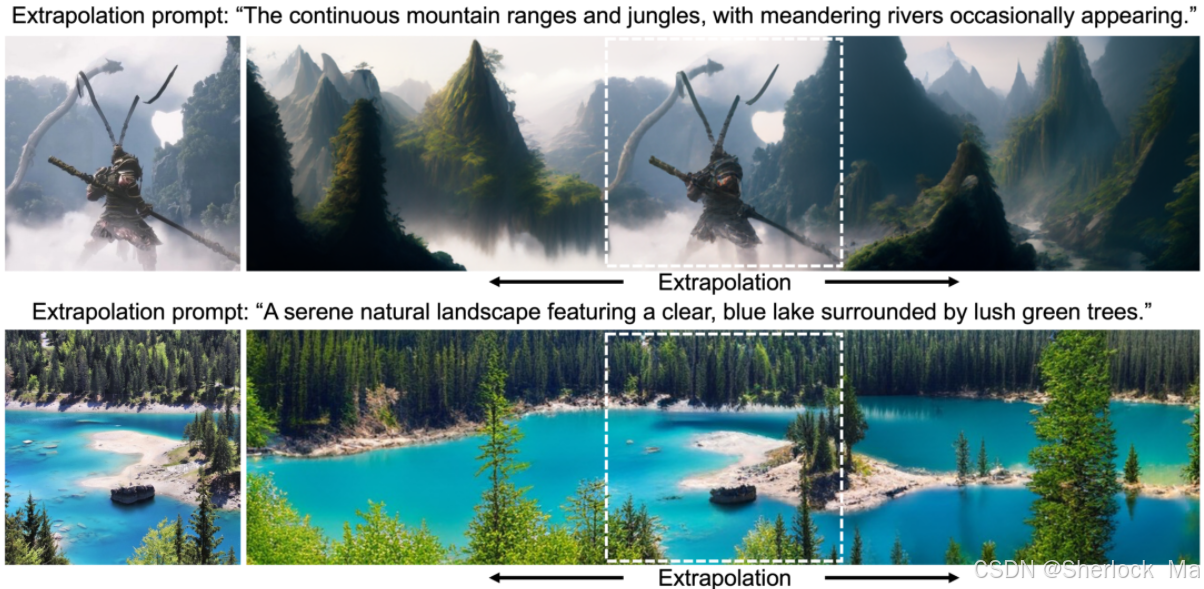
Show-o,统一了多模态理解和生成,既能完成多模态大模型的理解,又能完成生成模型的生成。与完全自回归模型不同,Show-o统一了自回归和(离散)扩散建模,以自适应地处理各种和混合模态的输入和输出。统一模型灵活地支持各种视觉语言任务,包括视觉问答,文本到图像生成,文本引导的修复/外推和混合模态生成。
show-o示例:

相关资源
代码:https://github.com/showlab/Show-o
论文:https://arxiv.org/pdf/2408.12528
demo:https://huggingface.co/spaces/showlab/Show-o
权重:https://huggingface.co/showlab
2.论文
整体架构
show-o的整体架构和其他多模态大模型区别不大,多模态理解时的操作和其他大模型一样,即自回归生成token。

最大的区别在于show-o生成时是先以自回归的形式预测所有token,然后按照diffusion的模式,每次只采纳几个token的预测结果,其他的依旧保持掩码状态,然后再输入到模型迭代多次,生成图片。(类似于diffusion的逐步去噪)
注意:生成过程中,Diffusion是加噪去噪的过程,而show-o是加掩码和去掩码的过程,这个过程使用的是Transformer模型(用transformer模型,使用diffusion的方法实现大一统)。见下图。

tokenization
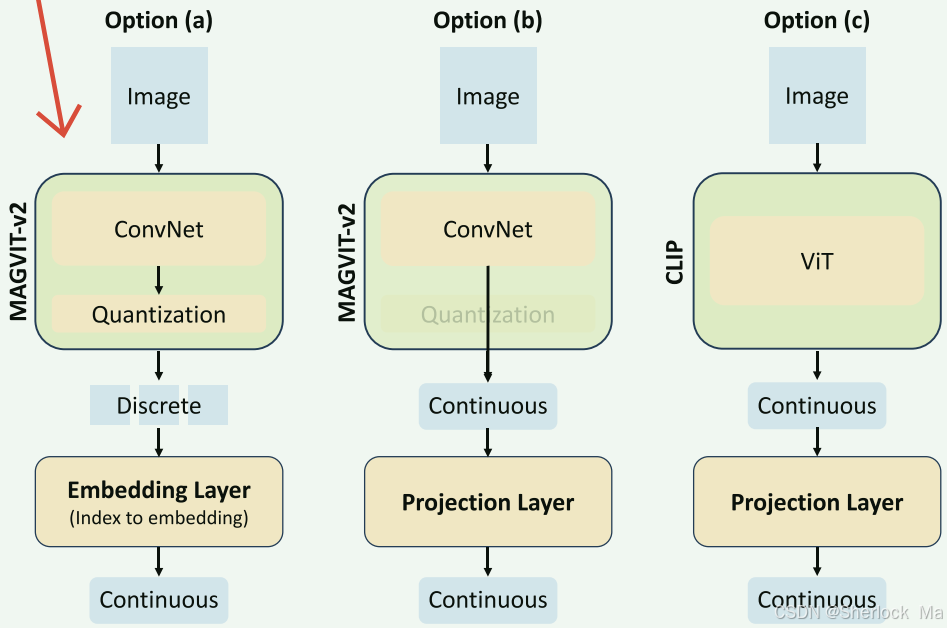
论文实验了三种方法,我们主要讲两种
第一种(option(a))是用离散的视觉Encoder处理图像,如magvit-v2,这个模型会把图像变成16*16的离散令牌,codebook大小在8192,其token id在文本token id的后面,即50000-58000左右
第三种(option(c))是用离散的视觉Encoder处理图像,如CLIP,和其他多模态大模型没什么区别。
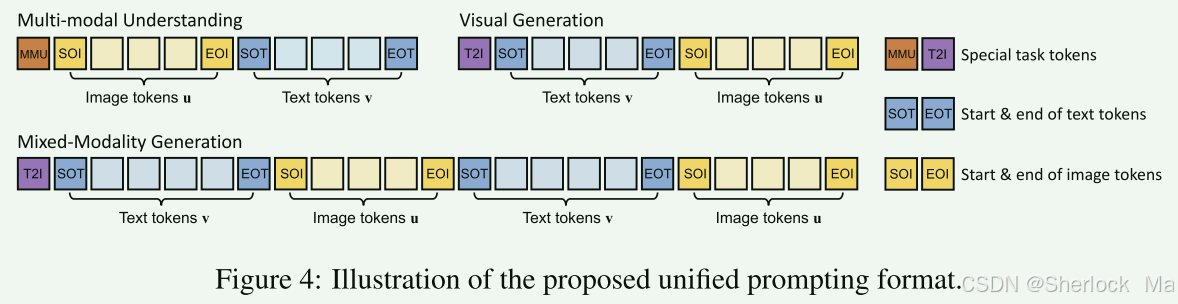
prompt
show-o的prompt以任务令牌为开头,包括<MMU>、<T2I>,接着跟上图像或文本token,图像的token以<SOI>和<EOI>为开头和结束,而文本的token以<SOT>和<EOT>为开头和结束。
注意力机制
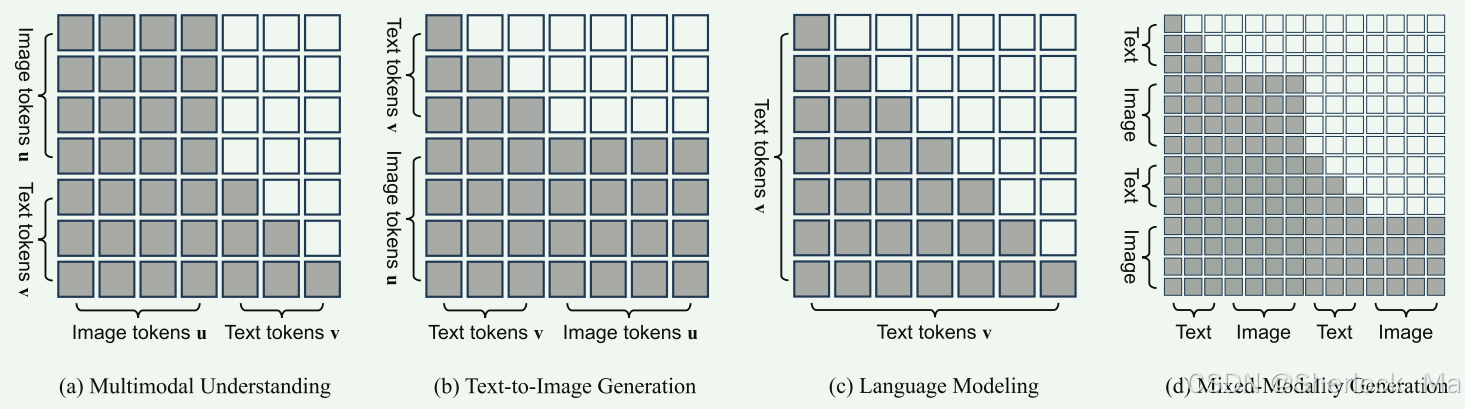
作者提出了一种全注意机制,使得Show-o能够以不同的方式对各种类型的信号进行建模。它是一种综合的注意机制,具有因果和完全注意,根据输入序列的格式自适应地混合和变化。
具体地说,Show-o通过因果注意对序列中的文本标记v进行建模。对于图像标记u,Show-o通过全注意力处理它们,允许每个标记与所有其他相关标记全面交互。给定一个格式化的输入序列,很明显,在多模态理解中(下图(a)),序列中的文本标记可以涉及所有先前的图像标记,而在文本到图像生成中(下图(B)),图像标记能够与所有先前的文本标记交互。全注意保持了预训练LLM的文本推理知识,减少了采样次数,提高了图像生成效率。此外,它自然支持各种下游应用,如图像修复和外推,而无需任何微调。当只给予文本标记时,它退化为因果注意(下图(c))。
损失函数
作者采用两个学习目标:i) Next Token Prediction (NTP,也就是自回归模型的损失) and ii) Mask Token Prediction (MTP,类似于扩散模型的损失).
NTP:给定用于多模态理解的具有M个图像标记u和N个文本标记v的序列,通过采用标准语言建模目标来最大化文本标记的可能性。
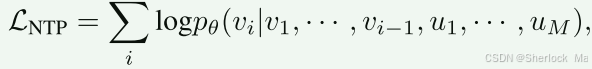
为了对输入序列内的图像标记u进行建模,我们首先以随机比率(由时间步长控制)用[MASK]标记随机替换图像标记,以创建掩码序列。接下来,我们的目标是通过未掩蔽区域为条件的掩蔽标记和之前的文本标记重建原始图像标记:
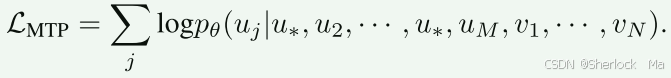
训练
- 第一阶段:采用RefinedWeb数据集来训练Show-o以保持语言建模能力。同时,ImageNet-1K数据集和图像-文本对分别用于训练Show-o进行类条件图像生成和图像字幕。这个阶段主要涉及学习离散图像标记的新的可学习嵌入,图像生成的像素依赖性,以及图像和文本之间的对齐。
- 第二阶段:基于预训练的权重,继续在图像-文本数据上进行文本到图像生成的训练。这个阶段主要集中在图像和文本对齐的图像字幕和文本到图像的生成。
- 第三阶段:最后,通过将过滤后的高质量图像-文本对用于文本到图像生成,以及用于多模态理解和混合模态生成的指导数据,进一步完善预训练的Show-o模型。
和transfusion的区别
处理图像的vision tower不同,transfusion是vae(连续),show-o是vq-vae(magvit,离散的),也就是说transfusion是编码成连续的向量,而show-o是编码成离散token,和文本的token合并后再转换为密集向量。
当然,show-o在图片理解的时候也有clip版本,不过生成时只有magvit(vq-vae,或者说离散)
3.代码
环境配置
pip3 install -r requirements.txt个人使用CogVideoX同款镜像源,安装几个库后就可以直接使用了。
另外,你还需要登录wandb,详细教程请参考其他博客,需要注意的是,这个库要梯子才能登录。
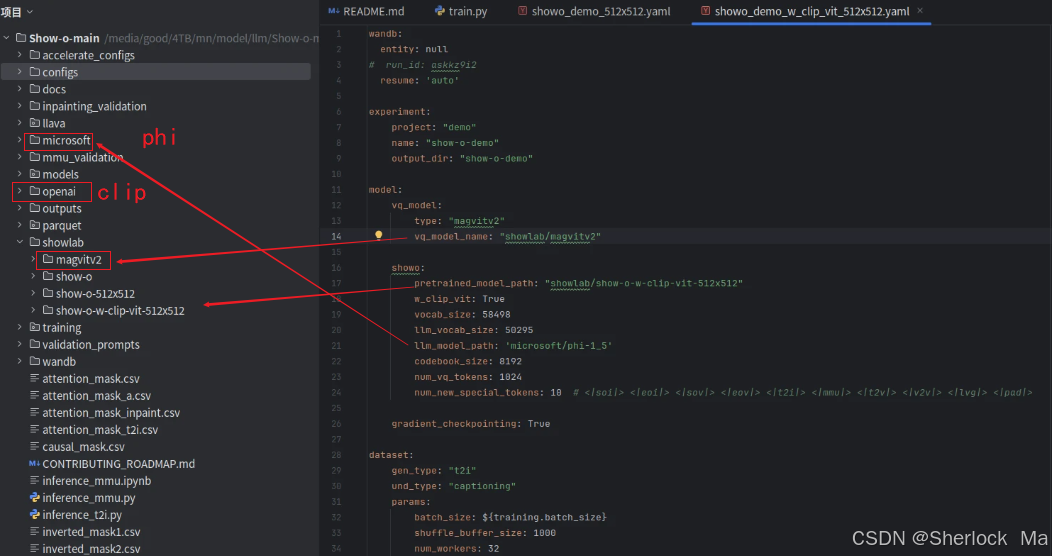
wandb login <your wandb keys>除了下载show-o自己的权重,你还需要下载phi-1_5和CLIP的权重,
phi-1_5:microsoft/phi-1_5 · HF Mirror
clip:openai/clip-vit-large-patch14-336 · HF Mirror
show-o仓库:showlab (Show Lab) (仓库地址,请根据所需,自选权重)
放置位置如下:
inference_mmu.py(图像QA)
基本使用
你可以选择clip模型作为视觉编码器,也就是论文4.1所说的option(c)
python3 inference_mmu.py config=configs/showo_demo_w_clip_vit_512x512.yaml \
max_new_tokens=100 \
mmu_image_root=./mmu_validation question='Please describe this image in detail. *** Do you think the image is unusual or not?'
或者选择magvitv2模型,也就是论文4.1所说的option(a)
python3 inference_mmu.py config=configs/showo_demo_512x512.yaml \
max_new_tokens=100 \
mmu_image_root=./mmu_validation question='Please describe this image in detail. *** Do you think the image is unusual or not?'初始化
运行起代码后,代码会首先进入初始化环节,这里大家只需要知道以下模型即可:
- tokenizer:phi-1_5
- vq_model:magvitv2
- model:showo
- vision_tower:clip-vit
以上四个模型都会调用,但如果选择的是option(c),代码只会使用vision_tower,相反,如果选择option(a),代码会只使用vq_model,相当于另一个调了不用。
整体逻辑
file_list = os.listdir(config.mmu_image_root) # 文件夹下的所有图片
responses = ['' for i in range(len(file_list))] # 返回值
images = []
config.question = config.question.split(' *** ') # 把n个问题拆分
for i, file_name in enumerate(tqdm(file_list)): # 每张图片遍历
图像预处理
for question in config.question: # 每个问题挨个处理
if clip:
1.
2.
3.
4.
else:
# 这里是使用magvitv2的部分图像预处理
这里其实是分了两步:
- 如果选择showo_demo_w_512x512_clip_vit.yaml,也就是option(c),其需要pixel_values作为输入,pixel_values是通过Image库读取,然后经过clip转化得到的
- 如果选择showo_demo_512x512.yaml,也就是option(a),首先通过Image库读取图片,然后用image_transform函数处理图片,具体来说,这个函数包括了尺寸缩放、转换为tensor、归一化等操作;最后通过magvitv2转换为离散令牌,需要注意的是,这里的图片令牌的序号是排在文本令牌的后面,这也就是下面代码倒数第二行在做的事情。
image_path = os.path.join(config.mmu_image_root, file_name)
image_ori = Image.open(image_path).convert("RGB")
image = image_transform(image_ori, resolution=config.dataset.params.resolution).to(device) # 变成正方形,变tensor,然后归一化
image = image.unsqueeze(0) # [1,3,512,512]
images.append(image)
# 如果config是showo_demo_w_512x512_clip_vit.yaml,下面代码用pixel_values
pixel_values = clip_image_processor.preprocess(image_ori, return_tensors="pt")["pixel_values"][0] # [3,336,336]
# 如果config是showo_demo_512x512.yaml,下面代码用image_tokens
image_tokens = vq_model.get_code(image) + len(uni_prompting.text_tokenizer) # 这里是计算图片的token编码,即图像原来的编码加上文本编码的总数 [1,1024]
batch_size = 1处理与模型生成
1.处理文本
我们以clip为例,首先会进入处理文本的步骤。具体来说,代码会使用text_tokenizer将system的信息、user的信息转换为token,接着把两部分并,结果为input_ids_llava。下面是input_ids_llava的详细介绍:
首先是一个说明问题类型的token<|mmu|>,然后是system的token,然后是表示图片开始的令牌<|soi|>,以及图片结束的令牌<|eoi|>,图片留到第二步再加上(这里只是注释),最后是user的token。这里会把以上提到的所有信息concat起来,最后的尺寸是[b,28+len+3],其中28是system令牌的长度,一般不会改;len是user令牌的长度,3是三个特殊令牌的长度。
if config.model.showo.w_clip_vit:
# 1.处理文本
conv = conversation_lib.default_conversation.copy()
conv.append_message(conv.roles[0], question) # 添加user
conv.append_message(conv.roles[1], None) # 添加assistant
prompt_question = conv.get_prompt() # prompt
question_input = []
question_input.append(prompt_question.strip())
input_ids_system = [uni_prompting.text_tokenizer(SYSTEM_PROMPT, return_tensors="pt", padding="longest").input_ids
for _ in range(batch_size)] # system_prompt的tokenization [1,28]
input_ids_system = torch.stack(input_ids_system, dim=0)
assert input_ids_system.shape[-1] == 28
input_ids_system = input_ids_system.to(device)
input_ids_system = input_ids_system[0]
input_ids = [uni_prompting.text_tokenizer(prompt, return_tensors="pt", padding="longest").input_ids
for prompt in question_input] # prompt的tokenization [1,len]
input_ids = torch.stack(input_ids)
input_ids = torch.nn.utils.rnn.pad_sequence( # 填充
input_ids, batch_first=True, padding_value=uni_prompting.text_tokenizer.pad_token_id
)
input_ids = torch.tensor(input_ids).to(device).squeeze(0)
# import pdb; pdb.set_trace()
input_ids_llava = torch.cat([
(torch.ones(input_ids.shape[0], 1) *uni_prompting.sptids_dict['<|mmu|>']).to(device),
input_ids_system,
(torch.ones(input_ids.shape[0], 1) * uni_prompting.sptids_dict['<|soi|>']).to(device),
# place your img embedding here
(torch.ones(input_ids.shape[0], 1) * uni_prompting.sptids_dict['<|eoi|>']).to(device),
input_ids,
], dim=1).long() # prompt的token进行拼接[1,28+len+3]2.图像处理
这里其实是通过CLIP对图片进行处理,然后通过线性层转换至大模型的理解空间,即转换为2048维的向量;text_embedding则是用show-o的embedding层将之前离散文本token转换为大模型的理解空间,即2048维的密集向量。
images_embeddings = vision_tower(pixel_values[None]) # CLIP [b,576,1024]
images_embeddings = model.mm_projector(images_embeddings) # show-o线性层 [b,576,2048]
text_embeddings = model.showo.model.embed_tokens(input_ids_llava) # embed [1,28+len+3,2048]3.拼接
具体来说,这个部分就是将图片填入之前prompt预留的位置。
attention_mask_llava则是论文中提到的Omni-Attention Mechanism(a)
# 3.Full input seq 拼接图片和文本
part1 = text_embeddings[:, :2 + SYSTEM_PROMPT_LEN, :]
part2 = text_embeddings[:, 2 + SYSTEM_PROMPT_LEN:, :]
input_embeddings = torch.cat((part1, images_embeddings, part2), dim=1) # [b,len,2048]
attention_mask_llava = create_attention_mask_for_mmu_vit(input_embeddings, # 注意力 [1,1,len,len]
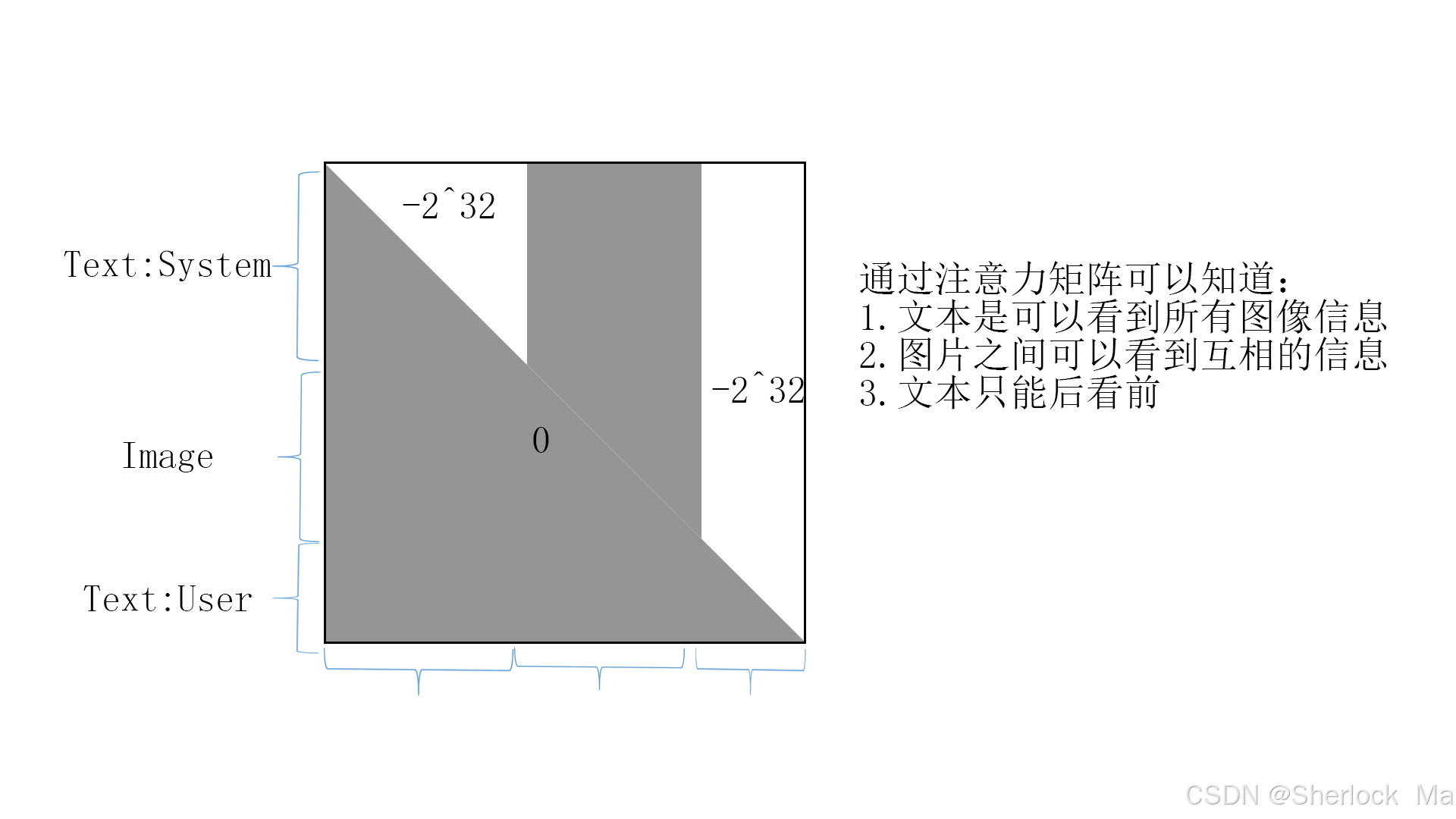
system_prompt_len=SYSTEM_PROMPT_LEN)在create_attention_mask_for_mmu_vit中,先通过tril函数生成一个下半三角为1的注意力矩阵,然后通过切片转换为(a)图所示的注意力矩阵。如果return_inverse_mask=True,代码会吧原本为1的部分变成0,原本为0的变成-2^32,供下一步计算。
def create_attention_mask_for_mmu_vit(
sequence,
return_inverse_mask=True,
system_prompt_len=0
):
N, L, H = sequence.shape
causal_mask = torch.tril(torch.ones((N, 1, L, L), dtype=torch.bool)).to(sequence.device) # 生成一个下三角的布尔张量,其中主对角线及以下的元素为True,以上的元素为False。
index = 1 + system_prompt_len + 1 + 576
# PART OF SYSTEM PROMPT SHOULD BE CAUSAL ALSO
# causal_mask[:, :, :, :index] = 1
causal_mask[:, :, :, 1+system_prompt_len+1:index] = 1
if return_inverse_mask:
inverted_mask = 1.0 - causal_mask.type(torch.int64)
inverted_mask = inverted_mask.masked_fill(
inverted_mask.to(torch.bool), torch.iinfo(torch.int64).min # 转换为布尔张量,这样 masked_fill 函数就可以根据这个布尔张量中的True值进行替换。
) # 原本的上三角部分(在 causal_mask 中为0)被替换为一个非常小的负数,而下三角部分(在 causal_mask 中为1)保持为0。
return inverted_mask
else:
return causal_mask这里的注意力矩阵如下:0代表能看见,-2^32表示看不见
4.show-o生成
这部分是模型的自回归生成过程,是核心代码
# 4.生成
cont_toks_list = model.mmu_generate(input_embeddings=input_embeddings,
attention_mask=attention_mask_llava[0].unsqueeze(0),
max_new_tokens=config.max_new_tokens,
top_k=top_k,
eot_token=tokenizer.eos_token_id
) # 返回的是列表,每个元素都是tensormmu_generate实际上就是模型进行自回归循环生成的过程,具体如下:
- 首先通过idx(如果是magvit)或input_embedding(如果是clip)以及掩码,生成下一个token的概率logits
- 更新掩码,掩码是每次行列尺寸各加1,添加方式是下半三角掩码的形式。
- 使用temperature控制随机性,然后通过top-k提取概率最大的k个,然后把其他的置为-inf
- 通过softmax和multinormal提取下一个token id
- 更新i
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









