




 本文详细比较了Redis和Memcache在数据类型、存储方式、可靠性、性能和应用场景等方面的区别,重点介绍了Redis在项目中的实际运用,包括缓存、session共享、购物车和排行榜等。同时讨论了Redis的持久化策略和集群部署,以及设计模式在软件开发中的重要性。
本文详细比较了Redis和Memcache在数据类型、存储方式、可靠性、性能和应用场景等方面的区别,重点介绍了Redis在项目中的实际运用,包括缓存、session共享、购物车和排行榜等。同时讨论了Redis的持久化策略和集群部署,以及设计模式在软件开发中的重要性。
你还用过其他的缓存吗?这些缓存有什么区别?都在什么场景下去用?
对于缓存了解过redis和memcache,redis我们在项目中用的比较多,memcache没用过,但是了解过一点;
Memcache和redis的区别:
数据支持的类型:
存储方式:redis不仅仅支持简单的k/v类型的数据,同时还支持list、set、zset、hash等数据结构的存储;memcache只支持简单的k/v类型的数据,key和value都是string类型
可靠性:memcache不支持数据持久化,断电或重启后数据消失,但其稳定性是有保证的;redis支持数据持久化和数据恢复,允许单点故障,但是同时也会付出性能的代价
性能上:对于存储大数据,memcache的性能要高于redis
应用场景:
Memcache:适合多读少写,大数据量的情况(一些官网的文章信息等)
Redis:适用于对读写效率要求高、数据处理业务复杂、安全性要求较高的系统
Redis在你们项目中是怎么用的?
-
门户系统中的首页内容信息的展示。(商品类目、广告、热门商品等信息)门户系统的首页是用户访问量最大的,而且这些数据一般不会经常修改,因此为了提高用户的体验,我们选择将这些内容放在缓存中;
-
单点登录系统中也用到了redis。因为我们是分布式系统,存在session之间的共享问题,因此在做单点登录的时候,我们利用redis来模拟了session的共享,来存储用户的信息,实现不同系统的session共享;
-
我们项目中同时也将购物车的信息设计存储在redis中,购物车在数据库中没有对应的表,用户登录之后将商品添加到购物车后存储到redis中,key是用户id,value是购物车对象;
-
因为针对评论这块,我们需要一个商品对应多个用户评论,并且按照时间顺序显示评论,为了提高查询效率,因此我们选择了redis的list类型将商品评论放在缓存中;
-
在统计模块中,我们有个功能是做商品销售的排行榜,因此选择redis的zset结构来实现;
还有一些其他的应用场景,主要就是用来作为缓存使用。
对redis的持久化了解不?
Redis是内存型数据库,同时它也可以持久化到硬盘中,redis的持久化方式有两种:
RDB(半持久化方式):
按照配置不定期的通过异步的方式、快照的形式直接把内存中的数据持久化到磁盘的一个dump.rdb文件(二进制文件)中;
这种方式是redis默认的持久化方式,它在配置文件(redis.conf)中的格式是:save N M,表示的是在N秒之内发生M次修改,则redis抓快照到磁盘中;
原理:当redis需要持久化的时候,redis会fork一个子进程,这个子进程会将数据写到一个临时文件中;当子进程完成写临时文件后,会将原来的.rdb文件替换掉,这样的好处是写时拷贝技术(copy-on-write),可以参考下面的流程图;

优点:只包含一个文件,对于文件备份、灾难恢复而言,比较实用。因为我们可以轻松的将一个单独的文件转移到其他存储媒介上;性能最大化,因为对于这种半持久化方式,使用的是写时拷贝技术,可以极大的避免服务进程执行IO操作;相对于AOF来说,如果数据集很大,RDB的启动效率就会很高
缺点:如果想保证数据的高可用(最大限度的包装数据丢失),那么RDB这种半持久化方式不是一个很好的选择,因为系统一旦在持久化策略之前出现宕机现象,此前没有来得及持久化的数据将会产生丢失;rdb是通过fork进程来协助完成持久化的,因此当数据集较大的时候,我们就需要等待服务器停止几百毫秒甚至一秒;
AOF(全持久化的方式)
把每一次数据变化都通过write()函数将你所执行的命令追加到一个appendonly.aof文件里面;
事实上,不会立即将命令写入硬盘文件中,而是写入硬盘缓存,可以配置策略,配置多久从硬盘缓存写入到硬盘文件中。
Appendfsync always
Appendfsync everysec 默认的
Appendfsync no 不主动,默认30秒一次
Redis默认是不支持这种全持久化方式的,需要将no改成yes

实现文件刷新的三种方式:

no:不会自动同步到磁盘上,需要依靠OS(操作系统)进行刷新,效率快,但是安全性就比较差;
always:每提交一个命令都调用fsync刷新到aof文件,非常慢,但是安全;
everysec:每秒钟都调用fsync刷新到aof文件中,很快,但是可能丢失一秒内的数据,推荐使用,兼顾了速度和安全;
原理:redis需要持久化的时候,fork出一个子进程,子进程根据内存中的数据库快照,往临时文件中写入重建数据库状态的命令;父进程会继续处理客户端的请求,除了把写命令写到原来的aof中,同时把收到的写命令缓存起来,这样包装如果子进程重写失败的话不会出问题;当子进程把快照内容以命令方式写入临时文件中后,子进程会发送信号给父进程,父进程会把缓存的写命令写入到临时文件中;接下来父进程可以使用临时的aof文件替换原来的aof文件,并重命名,后面收到的写命令也开始往新的aof文件中追加。下面的图为最简单的方式,其实也是利用写时复制原则。

优点:
数据安全性高
该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机问题,也不会破坏日志文件中已经存在的内容;
缺点:
对于数量相同的数据集来说,aof文件通常要比rdb文件大,因此rdb在恢复大数据集时的速度大于AOF;
根据同步策略的不同,AOF在运行效率上往往慢于RDB,每秒同步策略的效率是比较高的,同步禁用策略的效率和RDB一样高效;
针对以上两种不同的持久化方式,如果缓存数据安全性要求比较高的话,用aof这种持久化方式(比如项目中的购物车);如果对于大数据集要求效率高的话,就可以使用默认的。而且这两种持久化方式可以同时使用。
做过redis的集群吗?你们做集群的时候搭建了几台,都是怎么搭建的?
针对这类问题,我们首先考虑的是为什么要搭建集群?(这个需要针对我们的项目来说)
Redis的数据是存放在内存中的,这就意味着redis不适合存储大数据,大数据存储一般公司常用hadoop中的Hbase或者MogoDB。因此redis主要用来处理高并发的,用我们的项目来说,电商项目如果并发大的话,一台单独的redis是不能足够支持我们的并发,这就需要我们扩展多台设备协同合作,即用到集群。
Redis搭建集群的方式有多种,例如:客户端分片、Twemproxy、Codis等,但是redis3.0之后就支持redis-cluster集群,这种方式采用的是无中心结构,每个节点保存数据和整个集群的状态,每个节点都和其他所有节点连接。如果使用的话就用redis-cluster集群。
集群这块直接说是公司运维搭建的,小公司的话也有可能由我们自己搭建,开发环境我们也可以直接用单机版的。但是可以了解一下redis的集群版。搭建redis集群的时候,对于用到多少台服务器,每家公司都不一样,大家针对自己项目的大小去衡量。举个简单的例子:
我们项目中redis集群主要搭建了6台,3主(为了保证redis的投票机制)3从(高可用),每个主服务器都有一个从服务器,作为备份机。
架构图如下:

-
所有的节点都通过PING-PONG机制彼此互相连接;
-
每个节点的fail是通过集群中超过半数的节点检测失效时才生效;
-
客户端与redis集群连接,只需要连接集群中的任何一个节点即可;
-
Redis-cluster把所有的物理节点映射到【0-16383】slot上,负责维护
2、容错机制(投票机制)
(1)选举过程是集群中的所有master都参与,如果半数以上master节点与故障节点连接超过时间,则认为该节点故障,自动会触发故障转移操作;
(2)集群不可用?
a:如果集群任意master挂掉,并且当前的master没有slave,集群就会fail;
b:如果集群超过半数以上master挂掉,无论是否有slave,整个集群都会fail;
6、redis有事务吗?
Redis是有事务的,redis中的事务是一组命令的集合,这组命令要么都执行,要不都不执行,redis事务的实现,需要用到MULTI(事务的开始)和EXEC(事务的结束)命令 ;
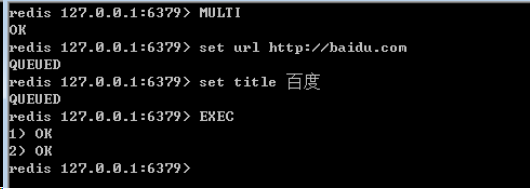
当输入MULTI命令后,服务器返回OK表示事务开始成功,然后依次输入需要在本次事务中执行的所有命令,每次输入一个命令服务器并不会马上执行,而是返回”QUEUED”,这表示命令已经被服务器接受并且暂时保存起来,最后输入EXEC命令后,本次事务中的所有命令才会被依次执行,可以看到最后服务器一次性返回了两个OK,这里返回的结果与发送的命令是按顺序一一对应的,这说明这次事务中的命令全都执行成功了。
Redis的事务除了保证所有命令要不全部执行,要不全部不执行外,还能保证一个事务中的命令依次执行而不被其他命令插入。同时,redis的事务是不支持回滚操作的。
【扩展】
Redis的事务中存在一个问题,如果一个事务中的B命令依赖上一个命令A怎么办?
这会涉及到redis中的WATCH命令:可以监控一个或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行,监控一直持续到EXEC命令(事务中的命令是在EXEC之后才执行的,EXEC命令执行完之后被监控的键会自动被UNWATCH)。
应用场景:待定
【扩展】
- redis的安全机制(你们公司redis的安全这方面怎么考虑的?)
漏洞介绍:redis默认情况下,会绑定在bind 0.0.0.0:6379,这样就会将redis的服务暴露到公网上,如果在没有开启认证的情况下,可以导致任意用户在访问目标服务器的情况下未授权访问redis以及读取redis的数据,攻击者就可以在未授权访问redis的情况下可以利用redis的相关方法,成功在redis服务器上写入公钥,进而可以直接使用私钥进行直接登录目标主机;
比如:可以使用FLUSHALL方法,整个redis数据库将被清空
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

言尽于此,完结
无论是一个初级的 coder,高级的程序员,还是顶级的系统架构师,应该都有深刻的领会到设计模式的重要性。
- 第一,设计模式能让专业人之间交流方便,如下:
程序员A:这里我用了XXX设计模式
程序员B:那我大致了解你程序的设计思路了
- 第二,易维护
项目经理:今天客户有这样一个需求…
程序员:明白了,这里我使用了XXX设计模式,所以改起来很快
- 第三,设计模式是编程经验的总结
程序员A:B,你怎么想到要这样去构建你的代码
程序员B:在我学习了XXX设计模式之后,好像自然而然就感觉这样写能避免一些问题
- 第四,学习设计模式并不是必须的
程序员A:B,你这段代码使用的是XXX设计模式对吗?
程序员B:不好意思,我没有学习过设计模式,但是我的经验告诉我是这样写的
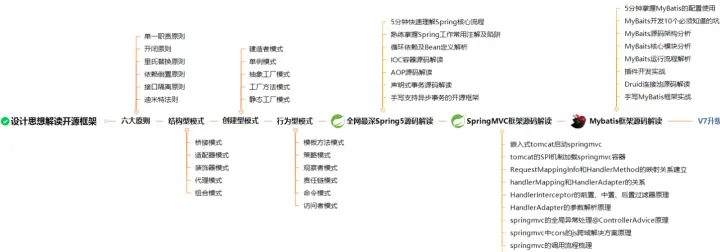
从设计思想解读开源框架,一步一步到Spring、Spring5、SpringMVC、MyBatis等源码解读,我都已收集整理全套,篇幅有限,这块只是详细的解说了23种设计模式,整理的文件如下图一览无余!
搜集费时费力,能看到此处的都是真爱!
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
模式,但是我的经验告诉我是这样写的
[外链图片转存中…(img-Xj9x3tw8-1713279304228)]
从设计思想解读开源框架,一步一步到Spring、Spring5、SpringMVC、MyBatis等源码解读,我都已收集整理全套,篇幅有限,这块只是详细的解说了23种设计模式,整理的文件如下图一览无余!
[外链图片转存中…(img-bjLAx1vH-1713279304228)]
搜集费时费力,能看到此处的都是真爱!
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









