




In continuation of the previous text 第5章:并发与竞态条件-13:Fine- Versus Coarse-Grained Locking, let's GO ahead.
Alternatives to Locking
The Linux kernel provides a number of powerful locking primitives that can be used to keep the kernel from tripping over its own feet. But, as we have seen, the design and implementation of a locking scheme is not without its pitfalls. Often there is no alternative to semaphores and spinlocks; they may be the only way to get the job done properly. There are situations, however, where atomic access can be set up without the need for full locking. This section looks at other ways of doing things.
Linux 内核提供了多种强大的锁原语,可防止内核因并发访问出现异常。但正如我们所见,锁机制的设计与实现并非毫无陷阱。多数情况下,信号量和自旋锁是实现正确并发控制的唯一选择;但在某些场景下,无需完整的锁机制也能实现原子性访问。本节将介绍其他实现并发安全的方式。
Lock-Free Algorithms
Sometimes, you can recast your algorithms to avoid the need for locking altogether. A number of reader/writer situations—if there is only one writer—can often workin this manner. If the writer takes care that the view of the data structure, as seen by the reader, is always consistent, it may be possible to create a lock-free data structure.
有时,你可以重构算法以完全避免锁的使用。许多 “单写多读” 的场景都能通过这种方式实现并发安全:只要写线程确保读线程看到的数据结构始终保持一致,就可以设计出无锁数据结构。
A data structure that can often be useful for lockless producer/consumer tasks is the circular buffer. This algorithm involves a producer placing data into one end of an array, while the consumer removes data from the other. When the end of the array is reached, the producer wraps backaround to the beginning. So a circular buffer requires an array and two index values to trackwhere the next new value goes and which value should be removed from the buffer next.
无锁的生产者 / 消费者场景中,环形缓冲区是一种常用的数据结构。该算法的核心逻辑是:生产者将数据写入数组的一端,消费者从另一端取出数据;当写操作到达数组末尾时,生产者会绕回数组起始位置继续写入。因此,环形缓冲区需要一个数组,以及两个索引值 —— 分别跟踪 “下一个待写入位置” 和 “下一个待读取位置”。
When carefully implemented, a circular buffer requires no locking in the absence of multiple producers or consumers. The producer is the only thread that is allowed to modify the write index and the array location it points to. As long as the writer stores a new value into the buffer before updating the write index, the reader will always see a consistent view. The reader, in turn, is the only thread that can access the read index and the value it points to. With a bit of care to ensure that the two pointers do not overrun each other, the producer and the consumer can access the buffer concurrently with no race conditions.
若实现得当,单生产者 + 单消费者 场景下的环形缓冲区无需任何锁:
-
生产者是唯一允许修改 “写索引” 及其指向的数组位置的线程;只要生产者先将新值写入缓冲区,再更新写索引,读线程看到的始终是一致的数据视图;
-
消费者是唯一允许访问 “读索引” 及其指向的值的线程;
-
只需稍加处理确保两个指针不会相互越界,生产者和消费者即可并发访问缓冲区,且不会产生竞争条件。
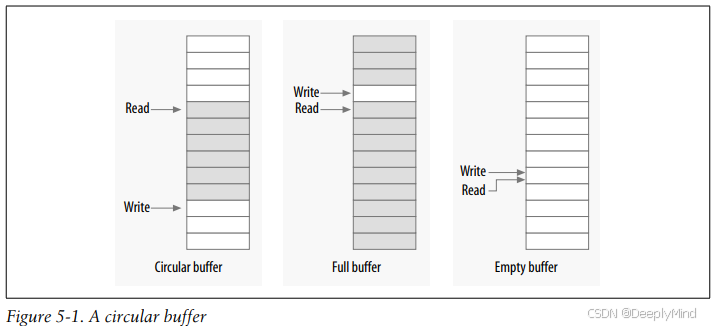
Figure 5-1 shows circular buffer in several states of fill. This buffer has been defined such that an empty condition is indicated by the read and write pointers being equal, while a full condition happens whenever the write pointer is immediately behind the read pointer (being careful to account for a wrap!). When carefully programmed, this buffer can be used without locks.
图 5-1 展示了环形缓冲区在不同填充状态下的形态。该缓冲区的状态规则定义为:
-
空缓冲区:读索引与写索引相等;
-
满缓冲区:写索引紧跟在读索引之后(需处理数组绕回的情况)。
只要编程实现时严格遵循该规则,这个缓冲区就可以无锁使用。
Circular buffers show up reasonably often in device drivers. Networking adaptors, in particular, often use circular buffers to exchange data (packets) with the processor. Note that, as of 2.6.10, there is a generic circular buffer implementation available in the kernel; see for information on how to use it.
环形缓冲区在设备驱动中十分常见,尤其是网络适配器(网卡)—— 这类设备常通过环形缓冲区与处理器交换数据(数据包)。需注意的是,从 2.6.10 版本开始,内核中已提供通用的环形缓冲区实现;可参考内核文档了解其使用方法。
补充说明:
-
无锁算法的核心前提
环形缓冲区的无锁特性仅适用于 “单生产者 + 单消费者” 场景:若存在多个生产者 / 消费者,仍需锁或原子操作保护索引的修改,否则会出现索引竞争。这个适用场景是否准确,请大家求证。这里我不太确定。
-
环形缓冲区的空 / 满判断细节
为避免 “空” 和 “满” 状态混淆(均可能表现为读写索引相等),实际实现中通常有两种处理方式:
-
额外维护一个 “数据长度” 计数器(原子类型),通过长度判断空 / 满。
-
预留一个数组位置不存储数据(满状态时写索引与读索引间隔一个位置);
-
-
内核通用环形缓冲区接口2.6.10+
内核的通用环形缓冲区实现位于
<linux/circ_buf.h>,核心接口包括:-
-
circ_buf:环形缓冲区结构体(包含数组指针、读写索引); -
CIRC_SPACE_TO_WRITE:计算可写入的空闲空间; -
CIRC_SPACE_TO_READ:计算可读取的数据长度;该实现已封装好索引绕回、空 / 满判断逻辑,驱动可直接复用。
-
-
-
无锁算法的适用边界
无锁设计仅适用于逻辑简单的场景(如单生产者 / 消费者、数据结构单一);复杂场景(如多写多读、嵌套数据结构)下,无锁算法的实现复杂度远高于锁机制,且易引入难以调试的并发 bug,此时优先使用锁更稳妥。
-
原子操作的辅助作用
无锁算法常依赖内核原子操作(如
atomic_t、cmpxchg)保证索引修改的原子性,例如:写索引的更新需通过atomic_inc实现,避免多线程同时修改导致索引错乱。


















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











