




1. 什么是统一内存/统一寻址
统一内存是可从系统中的任何处理器访问的单个内存地址空间。例如,CUDA 设备可与主机共享统一地址空间,在此模式下:设备指针与主机指针无区别,同一指针值可同时被主机程序和设备内核访问(部分例外情况除外)。
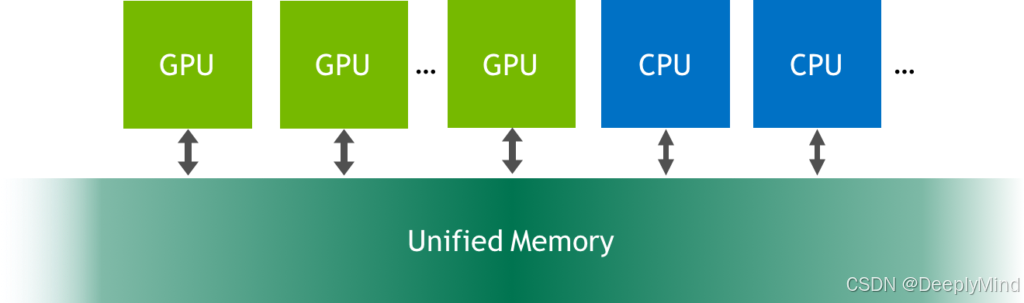
UM带来了UA,UA直接简化了编程。分配统一内存只需要用 cudaMallocManaged() 替换对 malloc() 或 new 的调用。这是一个分配函数,它返回一个可从任何处理器访问的指针(下文中的 data)。示例如下:
1 //UA编程示例:data指针可以同时被GPU和CPU访问。省去了来回拷贝的代码调用
2
3 char * data = nullptr;
4 cudaMallocManaged(&data, N) //分配内存
5 fill_data(data);
6 qsort<<<...>>>(data); //GPU process
7 cudaDeviceSynchronize();
8 use_data(data); //CPU process
9 cudaFree(data);
这直接带来了生产力的提升。例如,支持统一寻址的设备可直接使用cuMemcpy()进行任意类型的内存拷贝,无需区分:
cuMemcpyHtoD()cuMemcpyDtoD()cuMemcpyDtoH()
2. 调用cudaMallocManaged()时发生了什么
简化应用层的代码编写,自然需要底层新的机制和新的驱动实现。UA需要软件驱动和硬件的支持,可通过cuDeviceGetAttribute(CU_DEVICE_ATTRIBUTE_UNIFIED_ADDRESSING)查询设备是否支持。
调用cudaMallocManaged()时发生了什么,不同版本的GPU有不同实现,但原理上基本相同:页面迁移(page migration)。以上面的编程示例为例,具体实现过程如下:
- 调用
cudaMallocManaged()会在调用时处于活动状态的 GPU 设备上分配size字节的托管内存。驱动程序还为分配覆盖的所有页面设置页表条目,以便系统知道这些页面驻留在该 GPU 上; - 当执行第五行:fill_data(data)时, 由于页面最初驻留在设备内存中,因此对于它写入的每个数组页面,CPU 都会发生页面错误(page fault),在page fault的处理中,GPU 驱动程序会将页面从设备内存迁移到 CPU 内存;
- 当执行第6行:qsort<<<...>>>(data)时,在启动内核时,CUDA 运行时必须将之前迁移到主机内存或另一个 GPU 的所有页面迁移回运行内核的设备的设备内存。
3. 生产力的进一步提升
在64位地址的机器上会自动启用统一寻址,这意味着:
-
主机内存自动映射
使用以下函数分配的主机内存可被所有支持统一寻址的设备直接访问:cuMemAllocHost()cuMemHostAlloc()(无论是否指定CU_MEMHOSTALLOC_PORTABLE或CU_MEMHOSTALLOC_DEVICEMAP标志)
关键点:
- 内核中使用的指针值与主机端完全相同
- 无需调用
cuMemHostGetDevicePointer()获取设备侧指针
-
对等内存自动注册
当通过cuCtxEnablePeerAccess()启用对等访问后:- 对等上下文中使用
cuMemAlloc()和cuMemAllocPitch()分配的内存可被当前上下文直接访问 - 设备指针值在所有支持统一寻址的上下文中保持一致。
- 对等上下文中使用
64位地址空间为统一内存功能提供了足够大的空间划分能力。当前Nvidia GPU通过使用 49 位虚拟寻址和按需页面迁移就能令性能得到显着改进。 49 位虚拟地址足以让 GPU 访问整个系统内存以及系统中所有 GPU 的内存。页面迁移引擎允许 GPU 线程在非驻留内存访问时出错,因此系统可以根据需要将页面从系统中的任何位置迁移到 GPU 的内存,以进行高效处理。
换句话说,统一内存透明地启用了超额订阅 GPU 内存,为任何使用统一内存进行分配的代码启用了核外计算(例如 cudaMallocManaged())。无论是在一个 GPU 上还是在多个 GPU 上运行,它都可以“正常工作”而无需对应用程序进行任何修改。
4. 最佳实践
-
优先使用统一寻址
- 简化内存管理,减少显式数据传输
- 提高代码可移植性
-
避免不必要的指针转换
- 大多数情况下,主机指针可直接用于设备端
-
谨慎使用 WRITECOMBINED 标志
- 仅在写密集型场景使用,且需显式获取设备指针。
5. 性能优化提示
-
减少显式内存拷贝
利用统一寻址的零拷贝特性,避免冗余数据传输。 -
使用托管内存(Managed Memory)
结合cuMemAllocManaged()进一步简化内存管理,自动处理数据迁移。 -
内存预取(Prefetching)
通过cuMemPrefetchAsync()提前将数据迁移到目标设备。
6. 总结
统一寻址的核心价值在于消除主机 - 设备数据拷贝的显式管理,尤其适用于:
- 数据频繁在 CPU/GPU 间流动的场景
- 多 GPU 协同处理大规模数据集
- 追求代码简洁性的快速开发场景
开发者应充分利用这一特性,同时注意例外情况的特殊处理。
Unified Addressing在AMD体系里称为System Unified Address,构成了异构计算的基石,例如OpenCL的SVM特性的支持。因为通过统一寻址,大幅简化了异构内存管理,降低了编程复杂度,同时保持了高性能数据访问能力。无路是Nidia的CUDA还是AMD的ROCm都基于该机制做存储的管理和编程。
统一寻址背后的原理和驱动层的实现是很多技术从业者喜欢讨论和探究的,接下来我们一起探讨背后的原理。




















 990
990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











