




 本文介绍了如何在伪分布式环境中部署Yarn,包括配置mapred-site.xml和yarn-site.xml,以及部署后的ResourceManager和NodeManager角色。此外,还提到了日志文件的位置和查看日志的三种方法。
本文介绍了如何在伪分布式环境中部署Yarn,包括配置mapred-site.xml和yarn-site.xml,以及部署后的ResourceManager和NodeManager角色。此外,还提到了日志文件的位置和查看日志的三种方法。
MapReduce用来计算的,是jar包提交到Yarn上的,本身不需要部署;
Yarn是用来资源和作业调度的,需要部署
MapReduce on Yarn
部署过程:
1. 配置mapred-site.xml
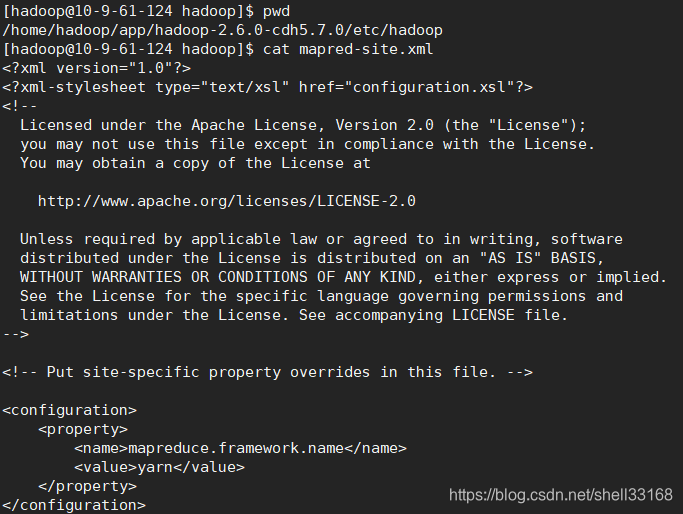
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>2.配置yarn-site.xml
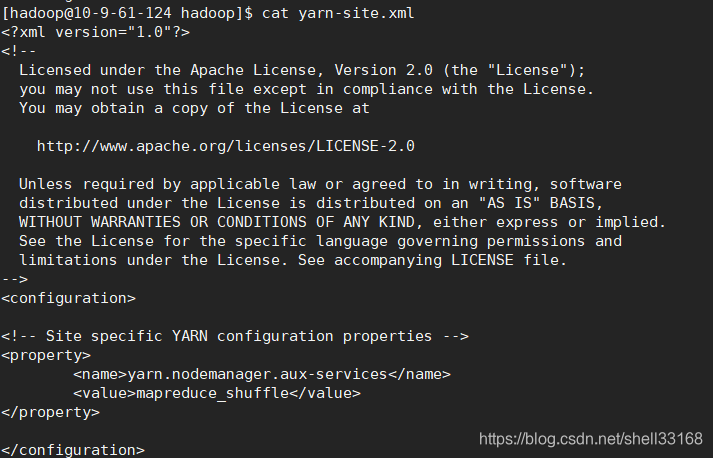
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>ResourceManager daemon 老大 资源管理者
NodeManager daemon
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









