




1.前言
最近刚刚完成了一个基于paddleocr的文字识别项目,使用了python和qtC++两个语言进行编写软件,最终得到的想要的效果,在这个过程中遇到了许多问题,解决之后也获得了许多经验。为此,特将个人经验所得记录于此,尽可能的写出所遇到的奇奇怪怪的问题以及奇奇怪怪的解决方式,该文章涉及到了python,C++,qt,linux等方面的林林总总的问题,且在之后若有更多的想法,将会进行增改。
2.python+paddleocr实现文字识别
2.1主要流程
paddleocr是paddlepaddle的一个文字识别模型,可以直接通过pip来进行paddleocr的包下载,最好加上清华源或者其它镜像源,更容易下载成功。执行如下指令
pip install paddleocr -i 镜像源网址这里我用的是anaconda在环境里进行安装。如下图所示。
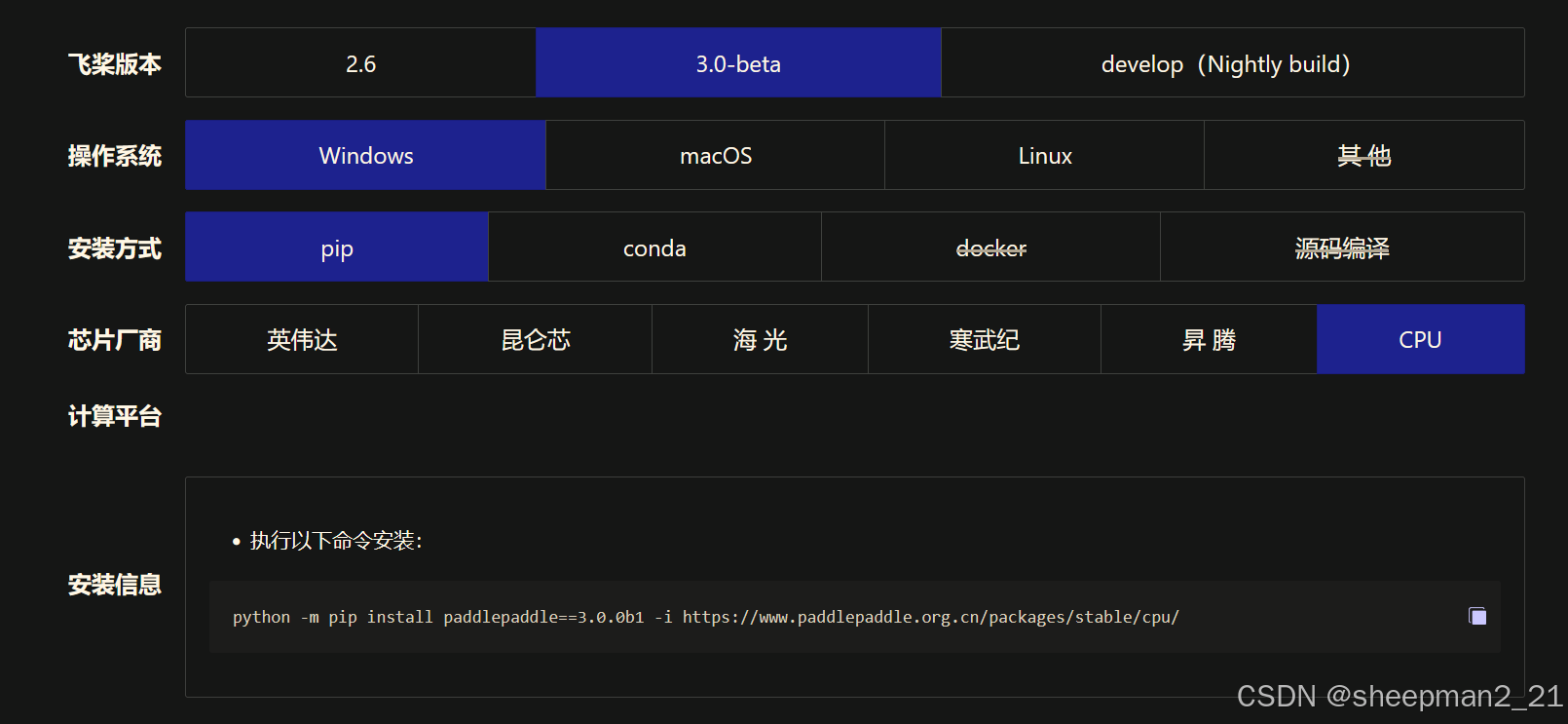
 注意:paddleocr还需要下载依赖库paddlepaddle-gpu(cpu版本也可以但是代码内要注意使用cpu)。下载gpu版本需要在paddlepaddle官网选择相应的版本进行下载,选择完成后会产生pip下载指令如下图所示。
注意:paddleocr还需要下载依赖库paddlepaddle-gpu(cpu版本也可以但是代码内要注意使用cpu)。下载gpu版本需要在paddlepaddle官网选择相应的版本进行下载,选择完成后会产生pip下载指令如下图所示。
下载好之后,即可以import使用paddleocr了。如下代码所示。
import cv2
import numpy as np
import paddleocr这里还使用了cv2和numpy进行了图像分割,有助于paddleocr进行识别。
在之后通过定义一个paddleocr变量来进行识别操作如下代码所示。
ocr = paddleocr.PaddleOCR(use_angle_cls=True,lang='en',gpu_use=False)
//gpu_use = False是为了不使用gpu,增加可移植性。
word = ocr.ocr(r'.\crop.jpg')
//对路径图片进行文字识别,返回列表。这样,就实现了文字识别,具体结果可以自己设置一个白色背景文字照片将路径输入实验。
2.2注意事项
对于注意事项以及更加详细的使用过程,可以参考我这篇文章。
关于paddleocr的一些使用注意事项:安装,使用和提高准确度_如何看paddleocr是否正确装好-优快云博客
分割图像注意事项:在该文章我提到了可以通过将存在大量文字的图像进行块分割,可以减少模型识别工作量,提高精度和准确度。并提供了对于表格类图片进行快速分割的便捷方法和注意事项。
3.qtC++和python的结合
其实python可以通过pip安装pyqt或pyside的,然后使用pyinstaller库生成exe文件。但是有时候会被要求使用qtc++进行UI编程,这时就不得不C++里调用python了,事实上,paddleocr也有C++库,但是使用方式是通过cmake进行构建编译生成exe文件,再使用C++调用,若要在代码层面上使用paddleocr,费很长时间,配置难度也很高,所以此项目不选用调用C++版本paddleocr。
C++调用python,我尝试了三种方法,三种方法亲测有效,根据实际情况可以选择不同的
3.1三种方法
思路就是通过C++内部的代码调用python的程序,分别是通过调用python生成的exe,通过python自带的C++调用python文件和用代码通过cmd运行python文件。
3.1.1调用python生成的exe文件
其实除了第二种方法,第一种和第三种方法都用到了qtC++中的一个名为QProcess的类,通过该类来调用python,如下代码所示。
//头文件下
//类外
#include <QProcess>
//类内
QProcess process;
//C文件下
process.start(QString("%1/python生成的exe文件名字.exe").arg(work_path));
该方法需要将python程序打包成exe文件,这里需要安装pyinstaller库,通过pip下载即可。其它作者还没有使用过,所以也不知道是否可行,对于pyinstaller库,有一些注意事项我认为需要提出。
使用pyinstaller时,按照一般方法在终端可以使用指令来进行打包,如以下指令。
pyinstaller 你的文件名.py --noconsole这样,就会产生一个spec文件和一个dist文件夹,spec文件类似于负责为pyinstaller文件提供打包要求,--noconsole意思是运行exe程序时,无需打开控制终端界面,使用该命令后,spec文件的 console=False,如以下代码所示。
exe = EXE(
pyz,
a.scripts,
[],
exclude_binaries=True,
name='word_scan',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
console=False,
disable_windowed_traceback=False,
argv_emulation=False,
target_arch=None,
codesign_identity=None,
entitlements_file=None,
)但是对于paddleocr这种第三方库,运行exe文件时,会产生报错。
由于几个月前用的这个方法,现在已经放弃不用了,所以具体报错什么没法展示,但是缺少paddleocr的一些dll文件,在linux是缺少so文件,所以,要将spec改成如下内容。
# -*- mode: python ; coding: utf-8 -*-
a = Analysis(
['word_scan.py'],
pathex=['D:\\software\\anaconda\\envs\\P312\\Lib\\site-packages\\paddleocr','D:\\software\\anaconda\\envs\\P312\\Lib\\site-packages\\paddle\\libs'],
binaries=[('D:\\software\\anaconda\\envs\\P312\\Lib\\site-package 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3446
3446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









