




 本文介绍了拉链表在数据仓库中的应用,常见于处理大量记录且存在更新操作的场景。通过全量数据采集、增量数据识别、历史数据更新等步骤,实现对特定时间点历史快照的查看。具体样例展示了如何实现拉链表,用于存储和查询历史状态变化。
本文介绍了拉链表在数据仓库中的应用,常见于处理大量记录且存在更新操作的场景。通过全量数据采集、增量数据识别、历史数据更新等步骤,实现对特定时间点历史快照的查看。具体样例展示了如何实现拉链表,用于存储和查询历史状态变化。
一、拉链表的使用场景
在数据仓库的数据模型设计过程中,经常会遇到下面这种表的设计:
1、 有一些表的数据量很大,比如一张用户表,大约10亿条记录,50个字段,这种表,即使使用ORC压缩,单张表的存储也会超过100G,在HDFS使用双备份或者三备份的话就更大一些。
2、 表中的部分字段会被update更新操作,如用户联系方式,产品的描述信息,订单的状态等等。
3、 需要查看某一个时间点或者时间段的历史快照信息,比如,查看某一个订单在历史某一个时间点的状态。
4、表中的记录变化的比例和频率不是很大,比如,总共有10亿的用户,每天新增和发生变化的有200万左右,变化的比例占的很小。
二、拉链表的步骤分析
1、采集当日全量数据到ND(NewDay)表;
2、可从历史表中取出昨日全量数据存储到OD(OldDay)表;
3、(NDOD)就是当日新增和变化的数据,也就是当天的增量,用W_I表示;
4、(ODND)为状态到此结束需要封链的数据,用W_U表示;
5、将W_I表的内容全部插入到历史表中,这些是新增记录,start_date为当天,而end_date为max值;
6、对历史表进行W_U部份的更新操作,start_date保持不变,而end_date改为当天,也就是关链操作
三、拉链表的具体样例
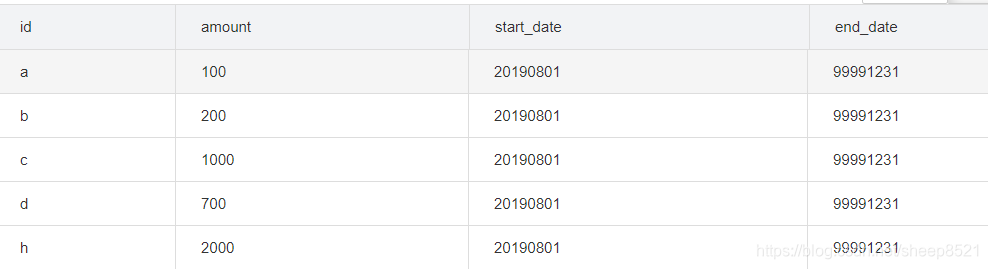
1、创建从历史表查询昨天的表OD(OldDay)
CREATE TABLE temp.temp_test_array_user_his as
select * from
(select 'a' id,'100' amount,'20190801' start_date,'99991231' end_date
union all
select 'b' id,'200' amount,'20190801' start_date,'99991231' end_date
union all
select 'c' id,'1000' amount,'20190801' start_date,'99991231' end_date
union all
select 'd' id,'700' amount,'20190801' start_date,'99991231' end_date
union all
select 'h' id,'2000' amount,'20190801' start_date,'99991231' end_date
) t
;
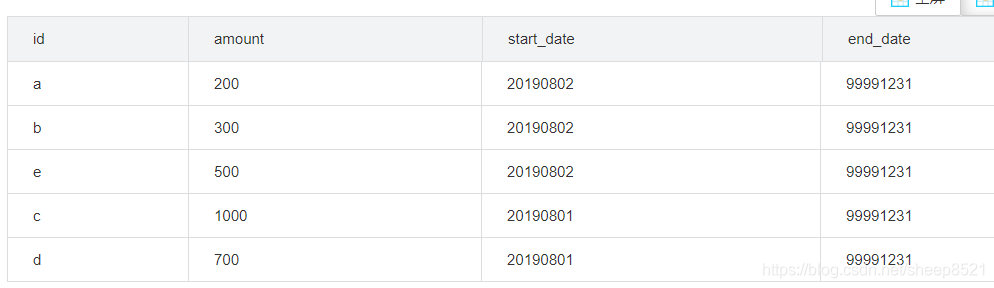
2、创建当日全量数据表ND(NewDay) 从数据库抽取的20190802的日全量快照数据。
CREATE TABLE temp.temp_test_array_user_today as
select * from
(select 'a' id,'200' amount,'20190802' start_date,'99991231' end_date --A账户新增100,余额变200
union all
select 'b' id,'300' amount,'20190802' start_date,'99991231' end_date
--B账户新增100,余额变300
union all
select 'e' id,'500' amount,'20190802' start_date,'99991231' end_date
--新增e账户500,余额变500
union all
select 'c' id,'1000' amount,'20190801' start_date,'99991231' end_date
--C账户没有变化
union all
select 'd' id,'700' amount,'20190801' start_date,'99991231' end_date
--D账户没有变化
--H账户进行了销户
) t
;
--当日新增和变化的数据 W_I
CREATE TABLE temp.temp_test_array_user_new as
select t1.id,t1.amount,'20190802' start_date,t1.end_date end_date
from temp.temp_test_array_user_today t1
left join temp.temp_test_array_user_his t2
on t1.id=t2.id and t1.amount=t2.amount
where t2.id is null
;
--一般数据发生变化时关闭旧数据链,然后开新数据链
--历史和当天的交集:W_U
CREATE TABLE temp.temp_test_array_user_old2new as --旧数据更新为新的数据链
select t1.id,t1.amount,t1.start_date,'20190802' end_date
from temp.temp_test_array_user_his t1
left join temp.temp_test_array_user_today t2
on t1.id=t2.id
where t2.id is not null
;
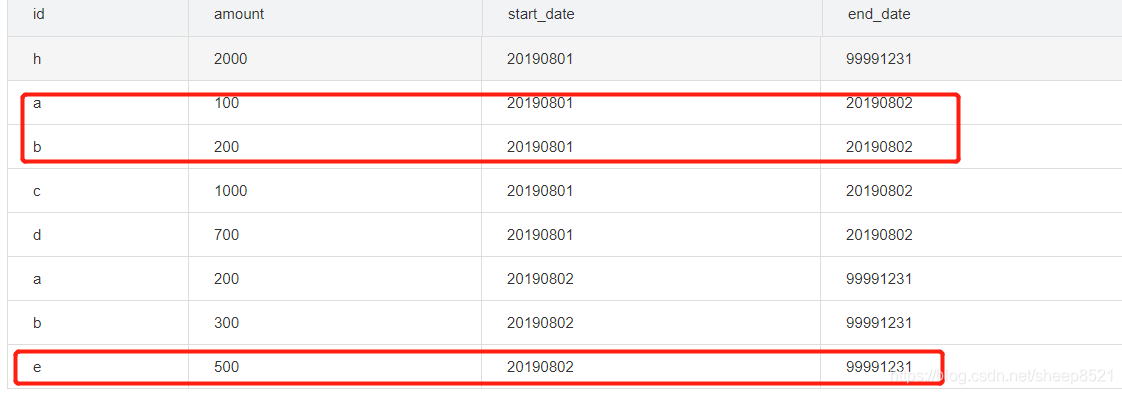
最后拉链表的数据:
select * from
(select a.id,a.amount,a.start_date,a.end_date 从历史表删除当天变化的数据
from(select id,amount,start_date,end_date from temp.temp_test_array_user_his) a
left join temp.temp_test_array_user_join b on a.id=b.id
where b.id is null
union all
select id,amount,start_date,end_date from temp.temp_test_array_user_new --当天新增数据
union all
select id,amount,start_date,end_date from temp.temp_test_array_user_old2new --当天变化的数据,在历史表匹配到的的旧数据链,做了部分更新
) t
最后拉链表的数据:

















 7922
7922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









