



题目描述
设计并实现一个满足 LRU (最近最少使用) 缓存约束的数据结构。
要实现 LRUCache 类:
LRUCache(int capacity)初始化 LRU 缓存int get(int key)若 key 存在返回对应值,否则返回 -1void put(int key, int value)若 key 存在更新值,不存在则插入。若缓存满则删除最久未使用的项
要求:get 和 put 操作时间复杂度均为 O(1)
示例:
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
解题思路
数据结构选择
要实现 O(1) 的 get 和 put 操作,需要两种数据结构协作:
- 哈希表:提供 O(1) 时间的键值查找
- 双向链表:维护访问顺序(最近访问的节点在头部,最久未访问的在尾部)
为什么是双向链表?
- 单链表删除节点需要遍历查找前驱节点
- 双向链表可以直接获取前后节点,删除效率 O(1)
- 移动节点操作更高效(先删除后插入头部)
算法设计图解
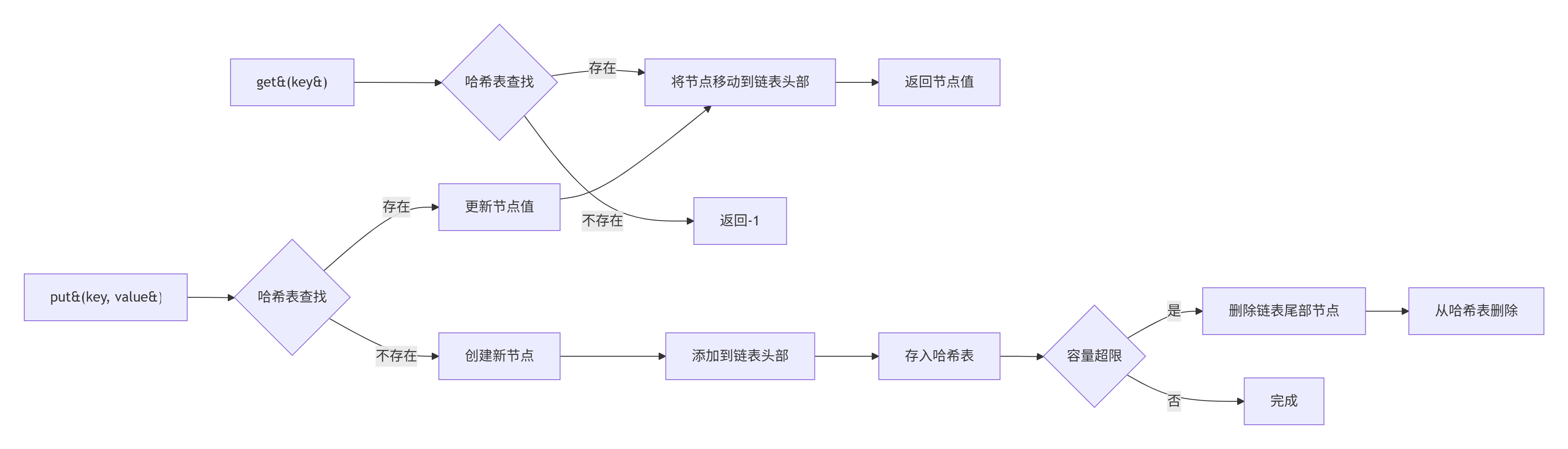
Java实现
import java.util.HashMap;
import java.util.Map;
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {}
public DLinkedNode(int key, int value) {
this.key = key;
this.value = value;
}
}
public class LRUCache {
private Map cache = new HashMap<>();
private int size; // 当前缓存数量
private int capacity; // 缓存容量
private DLinkedNode head, tail; // 双向链表的头尾虚节点
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
// 使用伪头节点和伪尾节点简化操作
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
// 访问节点后移动到链表头部
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
// 新建节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加到双向链表头部
addToHead(newNode);
size++;
if (size > capacity) {
// 删除链表尾部节点
DLinkedNode tailNode = removeTail();
// 从哈希表中删除
cache.remove(tailNode.key);
size--;
}
} else {
// 更新值并移动到头部
node.value = value;
moveToHead(node);
}
}
// 辅助方法:添加节点到头部
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
// 辅助方法:删除节点
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
// 辅助方法:移动节点到头部
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
// 辅助方法:移除尾部节点
private DLinkedNode removeTail() {
DLinkedNode tailNode = tail.prev;
removeNode(tailNode);
return tailNode;
}
}
代码解析
数据结构设计
- 双向链表节点 DLinkedNode
key:存储键值对的键value:存储键值对的值prev/next:维护前后节点关系
- 缓存结构成员
cache:HashMap 存储键到节点的映射head/tail:双向链表的虚节点(简化边界处理)size/capacity:记录当前缓存大小和容量限制
关键操作
- 访问操作
get()
- 在哈希表中查找节点
- 若存在则移动到链表头部(表示最近使用)
- 返回对应值或 -1
- 插入操作
put()
- 存在:更新值并移动到头部
- 不存在:
- 新建节点并添加到链表头部
- 存入哈希表
- 若超过容量则删除尾部节点(最久未使用)
设计亮点
- 虚头/尾节点
- 避免链表头尾特殊情况的判断
- 简化节点插入和删除逻辑
- 模块化辅助方法
addToHead():标准化的节点添加操作removeNode():节点删除的原子操作moveToHead():组合使用实现节点移动removeTail():容量控制的核心
复杂度分析
- 时间复杂度:所有操作 O(1)
- 哈希表操作:O(1)
- 链表操作:O(1)
- 空间复杂度:O(capacity)
- 哈希表存储所有节点
- 链表存储所有节点指针
实际应用场景
- 数据库缓存:MySQL Query Cache 缓存最近执行的查询结果
- 页面置换:操作系统内存管理中常用的缓存淘汰策略
- Web缓存:Nginx 反向代理服务器缓存最近访问的资源
- 微服务缓存:Redis 使用近似 LRU 策略进行缓存淘汰
- 前端资源缓存:浏览器缓存最近访问的静态资源
经典变体与扩展
- LFU (最不经常使用)缓存
- 记录访问频率而非访问时间
- 实现难度更高(需要两个哈希表+双链表)
- Redis 改进算法
- Approximated LRU:随机抽选淘汰项
- LFU (Least Frequently Used):频率淘汰
- 分布式LRU缓存
- 一致性哈希实现分布式缓存
- 批量操作减少网络请求
总结
LRU 缓存设计完美展现了 数据结构组合 的艺术:
- 哈希表:提供闪电般的键值查找能力
- 双向链表:优雅维护访问时间序列
- 虚节点:巧妙处理边界情况
这种设计模式在系统开发中广泛应用,掌握它不仅提升算法能力,更能加深对实际系统设计的理解。
算法如艺术,好的数据结构组合如同优美的建筑结构。LRU缓存设计的精妙之处在于其简单的结构达成了高效的操作,这正是计算机科学的魅力所在。

















 1180
1180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









