




 本文介绍了如何利用Praat脚本绘制元音分布图。在提取共振峰数据后,可通过脚本将数据以散点图呈现,并画出椭圆表示中心位置。还说明了脚本的运行方法,包括设置输入路径、组织共振峰数据文本等,同时列举了不同情况的操作示例。
本文介绍了如何利用Praat脚本绘制元音分布图。在提取共振峰数据后,可通过脚本将数据以散点图呈现,并画出椭圆表示中心位置。还说明了脚本的运行方法,包括设置输入路径、组织共振峰数据文本等,同时列举了不同情况的操作示例。
引题
学习了如何提取共振峰(Praat脚本-010 | 提取时长和共振峰)之后,有一个很重要的步骤就是如何将这些数据呈现出来,以表达你的观点或者说明问题。在提取共振峰这一篇文章中,我们已经知道可以简单的根据平均值画出声学元音图,知道你所研究的样本在元音区间内,是如何分布的。
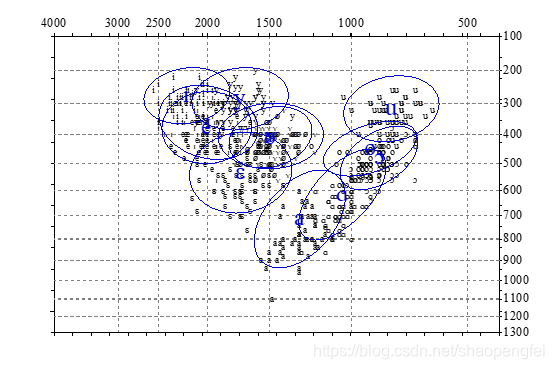
本篇会介绍另外一个操作,就是如何绘制元音分布图。元音分布图是利用提取的共振峰数据F1和F2,在坐标图上绘制出所有样本的点,也算是一种散点图,再利用Praat的一个Discriminant功能,能够得到同一系列散点图的中心位置,并画出来一个椭圆出来,如下图所示。不过由于数据比较多,可能数据样本的选择也要更有代表性,所以正象我这个图上所展示的,很多点都混在一块了,看不到明显的区别边界,这可能并不算是太好的数据样本集。
运行脚本
本文的代码下载地址见下文(获取脚本部分)是11-draw_vowel_map/Draw_Vowel_Map.Praat。脚本里有我的邮箱,有任何问题都可以来信咨询。
打开Praat之后,选择Praat,Open Praat Script...,打开这个脚本,然后在脚本窗口选择Run,Run,或者直接使用快捷键Ctrl+R,在弹出来的对话框里,设置一个输入路径就好了。这个脚本使用非常简单,它的难点可能在于你怎么组织你的共振峰数据文本。
- 设置你的
输入数据所在的路径;
设置完毕,点击OK,运行脚本,就可以直接在Praat Picture窗口里看到这个分布图。
这个输入文件input_formant.txt的文件是怎么样的呢?
| label | F1 | F2 |
|---|---|---|
| u | 320 | 630 |
| a | 780 | 1300 |
| o | 500 | 940 |
| \as | 720 | 1060 |
第一列是提取共振峰的元音名称,第二列和第三列分别是F1, F2,具体可参考脚本同目录下的例子。这里由于使用了Praat的转义字符,即\as这样的会显示成为IPA的符号。具体可查阅Praat说明。
情况一
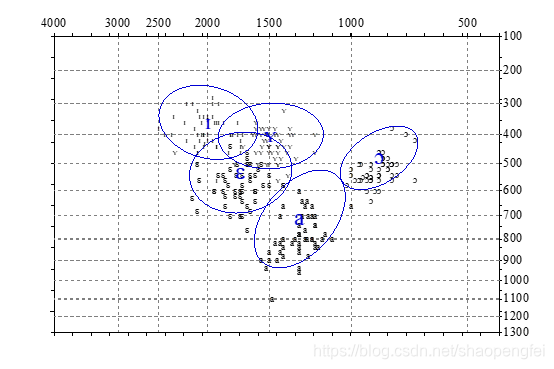
我们对于刚才的数据稍微选择几个分类比较明显的类别,再运行程序,
情况二
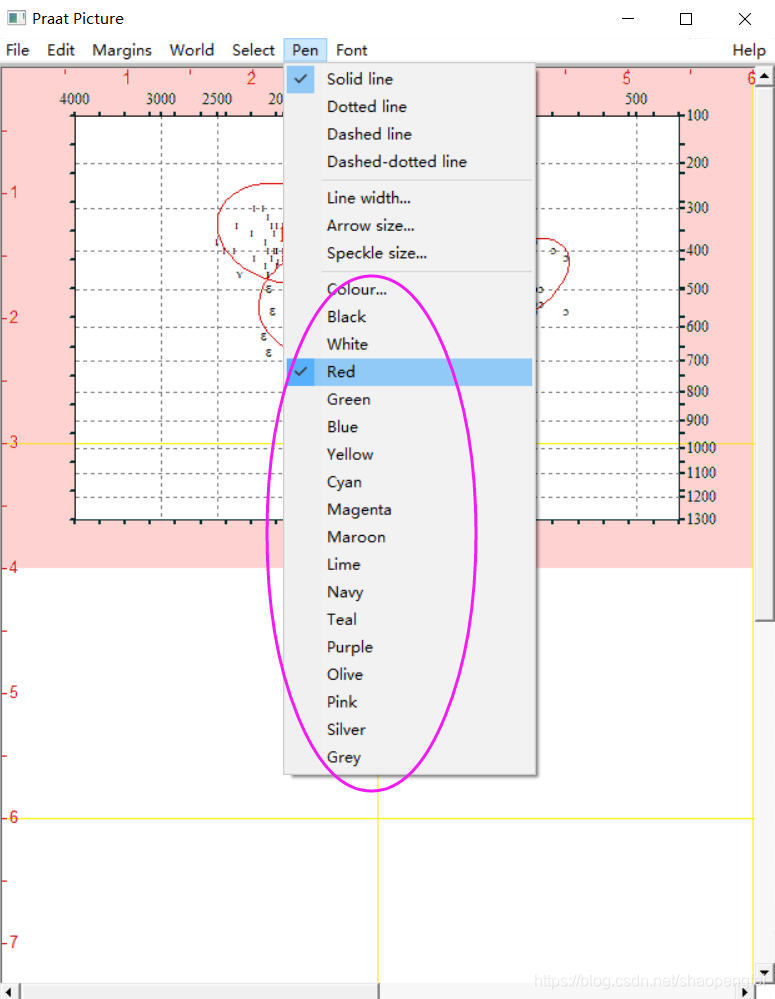
在脚本的倒数第4行,把Blue改成Red,可以将图上的蓝色椭圆线改成红色。
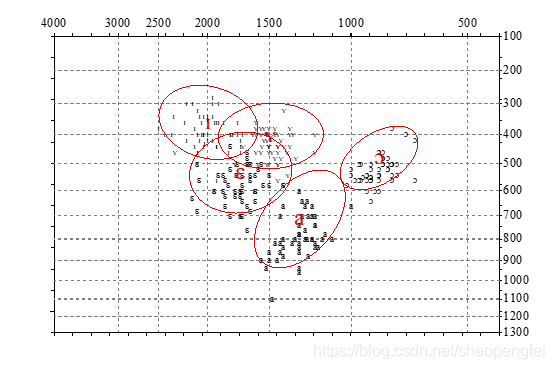
同理,可以支持其它颜色,见Praat Picture窗口里的Pen菜单里。
情况三
我们以biaobei开源数据为例,该数据可以从我的公众号里文章里查到,里面提供了250句标注好的TextGrid和开源wav。首先利用提取共振峰的脚本提取共振峰。我们选择单韵母,a, e, i, u这四个画图看一下。提取的数据如下:
fileName name duration F1 F2 F3
000001.TextGrid a2 0.110 998 1587 2535
000001.TextGrid u3 0.157 413 984 3334
000001.TextGrid i1 0.203 322 2244 3039
000003.TextGrid a3 0.178 864 1439 2328
000003.TextGrid a4 0.239 1070 1607 2767
000004.TextGrid a4 0.140 913 1907 2931
000004.TextGrid u4 0.207 366 920 3202
000005.TextGrid u3 0.124 393 1632 3227
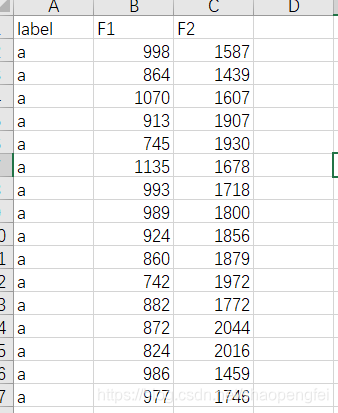
把它们拷贝到Excel中进行整理,删除不需要的列:
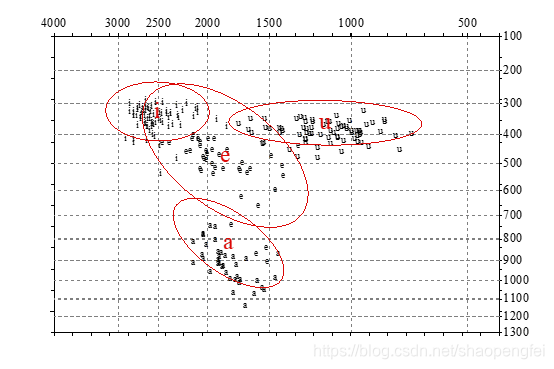
再把这些数据拷贝回本篇使用的输入文本中input_formant.txt。运行脚本,我们得到以下结果,这就得到了这个普通话中文数据a,e,i,u这四个单韵母的元音分布图。
获取脚本
https://github.com/feelins/Praat_Scripts
本站所有Praat脚本都可以在上述github的项目目录里找到,如果日常对代码、脚本操作比较熟练的可通过下载、安装、配置github for windows在自己的电脑上通过git clone将代码下载到本机,这样的好处是可以跟主站及时更新代码。
不想费如此脑筋,可以通过点击如下图Code位置所示,下载整站的代码,可直接使用。

关注
关于对本站脚本的使用咨询,以及功能修改,增加等,都可以扫QQ咨询群,私信群主。

版权说明
1、版权归本公众号“极地语音工作室”,原名“语音处理小站”所有;
2、未经本站或者作者允许, 不得任意转载本文内容,否则将视为侵权;
3、转载或者引用本文内容请注明来源及原作者;
4、对于不遵守此声明或者其他违法使用本站内容者,本人依法保留追究权等。



















 2412
2412






 到【灌水乐园】发言
到【灌水乐园】发言









