



 本文详细介绍了Linux中处理文本的几个常用命令,包括sort(排序)、uniq(去重)、tr(字符替换)、cut(截取字段)、split(拆分文件)和eval(命令解析)。每个命令都包含了基本用法、选项和实例操作,特别讨论了如何利用这些命令统计日志文件中访问量最大的IP地址。
本文详细介绍了Linux中处理文本的几个常用命令,包括sort(排序)、uniq(去重)、tr(字符替换)、cut(截取字段)、split(拆分文件)和eval(命令解析)。每个命令都包含了基本用法、选项和实例操作,特别讨论了如何利用这些命令统计日志文件中访问量最大的IP地址。
目录
1.sort命令
2.uniq命令
3.tr命令
4.cut命令
5.split命令
6. eval命令
7.统计日志文件中访问量最大的十个IP地址
1.sort命令
1.作用:
以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序,比较原则是从首字符向后,依次按AscII码值进行比较,最后将他们按升序输出。
2.格式:
sort [选项] 参数
cat file | sort 选项
| 选项 | 作用 |
| -f | 忽略大小写,会将小写字母都转换为大写字母来比较进行比较; |
| -b | 忽略每行前面的空格; |
| -n | 按照数字进行排序; |
| -r | 反向排序; |
| -u | 等同于unip,表示相同的数据仅显示一行; |
| -t | 指定字段分隔符,默认使用【Tab】键分隔; |
| -k | 指定排序字段; |
| -o <输出文件> | 将排序后的结果转存至指定文件。 |
3.实例操作
(1)对数字进行排序:按照第一列数字顺序进行排序,而不是按照数字大小。

(2)对字母进行排序:默认是按照首字母进行排序,且小写字母放前面,大写字母放后面。

(3)-f:忽略大小写,会将小写字母都转换为大写字母来进行比较。

(4)sort -n: 按照数字进行排序;sort -r:反向排序。

(5)sort -u:等同于uniq,表示相同的数据仅显示一行;去除重复的。

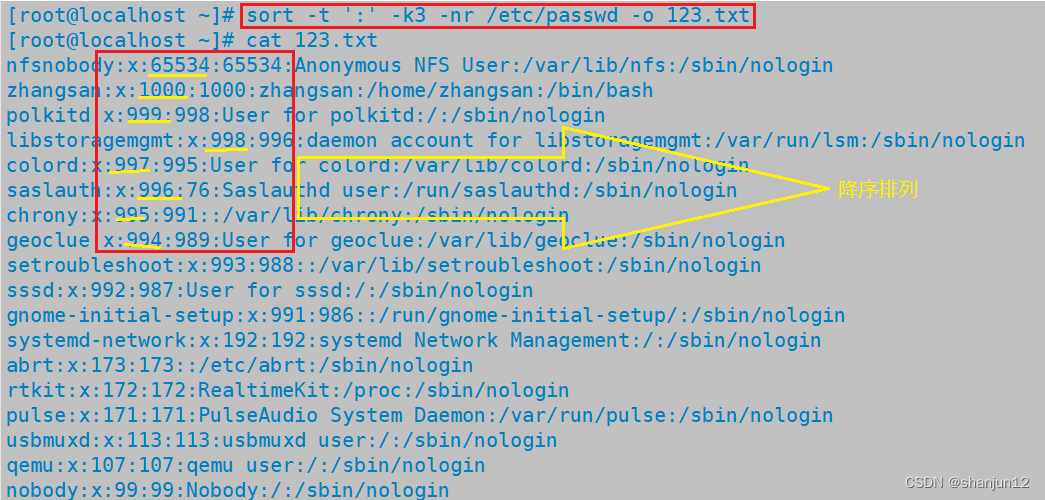
(6)按照/etc/passwd内的UID进行从大到小反向排序,并将排序结果输出到123.txt文件中。
sort -t ':' -k3 -nr /etc/passwd -o 123.txt
cat /etc/passwd | sort -t ':' -nr -o 123.txt
-t∶ 指定字段分隔符,默认使用 【Tab】键分隔;-k∶指定排序字段;-o <输出文件>∶ 将排序后的结果转存至指定文件
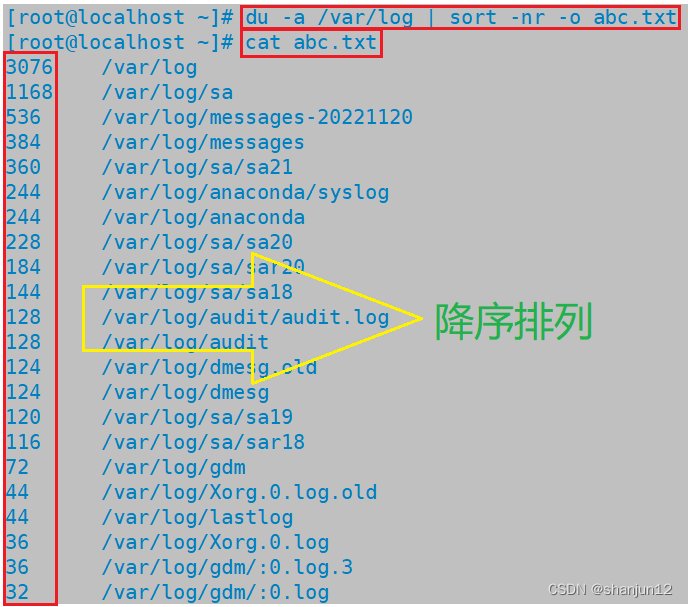
(7)对/var/log目录下的文件所占磁盘大小进行降序排列,并将排序结果输出到abc.txt文件中
du -a /var/log | sort -nr -o abc.txt
2.uniq命令
1.用于报告或者忽略文件中连续的重复行,常与 sort命令结合使用
2.格式:
uniq [选项] 参数
cat file | uniq 选项
3.常用选项
| 选项 | 作用 |
| -c | 进行计数,并删除文件中重复出现的行 |
| -d | 仅显示连续的重复行 |
| -u | 仅显示出现一次的行 |
4.实列操作
(1)去除重复内容,uniq+文件名

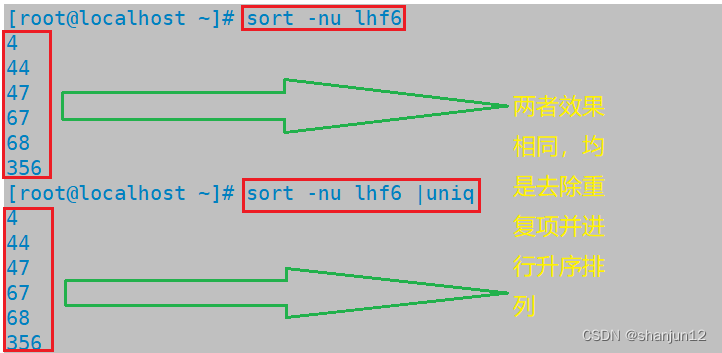
(2)uniq 结合sort -n 使用,去除重复项,并进行升序排列
sort -nu lhf6
sort -n lhf6 |uniq
(3)uniq -c∶ 进行计数,并删除文件中重复出现的行;
sort -n lhf6 |uniq -c

(4) uniq-d∶ 仅显示连续的重复行;
cat lhf5 | uniq -d
uniq -d lhf5
sort -n lhf5 | uniq -d

(5) uniq -u∶ 仅显示出现一次的行
cat lhf5 | uniq -u
uniq -u lhf5
sort -n lhf5 | uniq -u

3.tr命令
1.作用:常用来对来自标准输入的字符进行替换、压缩和删除。
2.格式:
tr [选项] [参数]
3.常用选项
| 选项 | 作用 |
| -c | 保留字符集1的字符,其他的字符(包括换行符\n)用字符集2替换 |
| -d | 删除所有属于字符集1的字符 |
| -s | 将重复出现的字符串压缩为一个字符串;用字符集2替换字符集1 |
| -t | 字符集2替换字符集1,与不加选项-t结果相同 |
4.参数
作用 :
(1)字符集1:指定要转换或删除的原字符集,当执行转换操作时,必须使用参数“字符集2”指定转换的目标字符集,但是执行删除操作时,不需要参数“字符集2”;
(2)字符集2:指定要转换成的目标字符集。
5. 实例操作
(1)tr与tr -t 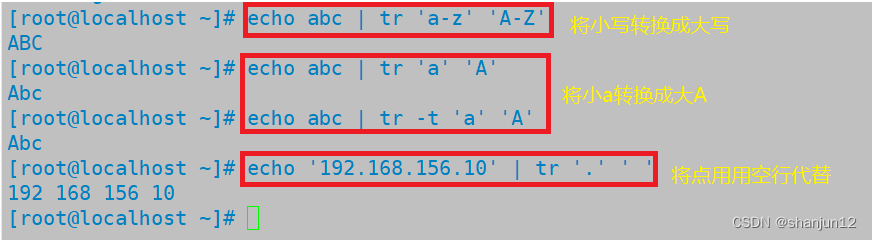
(2)tr -c
echo -e "abc\n123" | tr -c "a\n" "d"
echo -e "abc\n123" | tr -c "a" "d"
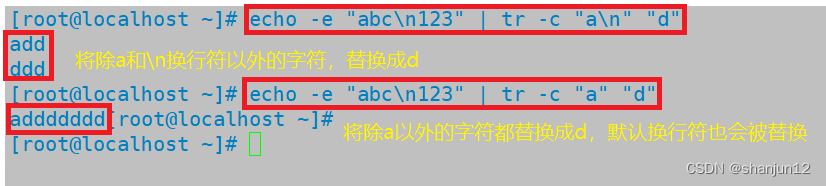
(3)tr -d

(4)tr -s

(5) 删除空行

4.cut命令
1.作用
显示行中的指定部分,删除文件中指定字段
(1)cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。
(2)如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
2.格式
cut [选项] 参数
3.常用选项
| 选项 | 作用 |
| -f | 显示指定字段的内容 , 与-d一起使用 ( -指定连续字段 ,指定不连续字段) |
| -d | 自定义分隔符,默认为制表符”TAB” |
| -b | 以字节为单位进行分割 ,仅显示行中指定直接范围的内容 |
| -n | 取消分割多字节字符 |
| -complement | 排除所指定的字段 |
| -output-delimiter | 更改输出内容的分隔符 |
4.实例操作
cut -d -f

截取字符串
${i:0: 3} :下标从0开始:截取的字符长度
echo $i l cut -b 1-3 :下标从1开始起始位置-终止位置
expr substr $i 1 3 :下标从1开始 1代表起始位置3代表截取的字符长度

5.split命令
Linux下将一个大的文件拆分成若干个小文件
格式:
split 选项 参数 原始文件 拆分后文件名前缀
常用选项
| 选项 | 作用 |
| -l | 以行数拆分 |
| -b | 以大小拆分 |

6. eval命令
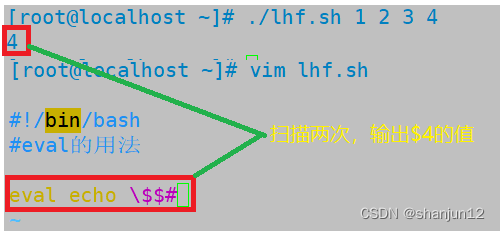
命令字前加上eval时,shell会在执行命令之前扫描它两次。eval命令将首先会先扫描命令行进行所有的置换,然后再执行该命令。该命令适用于那些一次扫描无法实现其功能的变量。该命令对变量进行两次扫描。

7.统计日志文件中访问量最大的十个IP地址
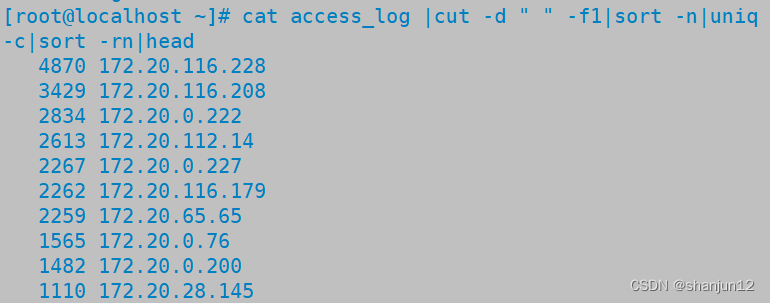
cat access_log |cut -d " " -f1|sort -n|uniq -c|sort -rn|head- 先在日志文件中将IP地址提取出来(cut -d)
- 按数字排序,将相同地址整理在一起(sort -n)
- 去掉重复的地址,并统计重复地址出现的重复次数(uniq -c)
- 排序(sort -rn)后查看前十个(head)
cat :查看日志文件。
日志文件 :access_log。
cut -d " " -f1 :以'' "作为分隔的条件,取文件的第一列。
sort -n :按数字大小整理排序。
uniq -c :统计相邻的行的重复数量。
sort -rn :反方向(由上至下)按数字大小整理排序。
head :默认查看开头十行。

















 143
143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









