




 探讨了在并发环境下HashMap扩容操作可能导致的死链问题,分析了死链产生的具体过程及原因,涉及到线程安全、数据结构及内存管理等方面。
探讨了在并发环境下HashMap扩容操作可能导致的死链问题,分析了死链产生的具体过程及原因,涉及到线程安全、数据结构及内存管理等方面。
死链主要出现在并发执行resize()方法中的转移方法中,假设两个线程同时扩容,都生成自己的局部变量newTable[],并开始转移当前table[]元素。此时虽然newTable是局部变量线程独立的,但是table以及其中的Entry是线程共享的。
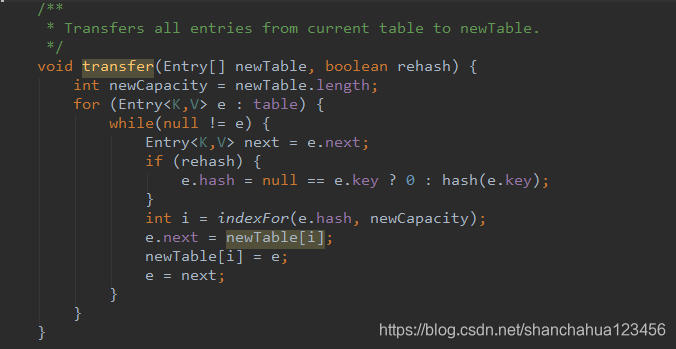
newTable是局部变量,但是原table上的Entry都是共享的。扩容转移节点时是把原链表节点倒序放入新table。
例如:原Table[i]=1->2->3,先转移1在转移2以此类推。转移完成后变成newTable[i]=3->2->1 。
其过程是先从原Table[i]中取出1,放入newTable[i]位置。然后将1.next也就是2,直接放入newTable[i]位置,将newTable[i]已有等节点链作为2.next处理。即后转移的节点永远放在头的位置,已转移的节点做他的next链。
假如有两个线程P1、P2,以及链表 a=》b=》null
1、线程P1先执行,执行完"Entry<K,V> next = e.next;"代码后线程P1停滞或者其他情况不再执行下去,此时线程P1 e=a,next=b
2、此时P2执行完整段代码,于是当前的p2的新链表newTable[i]为b=》a=》null(HashMap转移链表后是逆序)。且此时共享Entry b的next已经指向a,a.next=null。
3、此时P1又继续执行"Entry<K,V> next = e.next;"之后的代码,此时线程P1的e=a,next=b,则执行完"e=next;"后,P1的newTable[i]为a《=》b,则造成回路,while(e!=null)一直死循环

















 4758
4758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









