




对JVM的简单理解
java内存模型
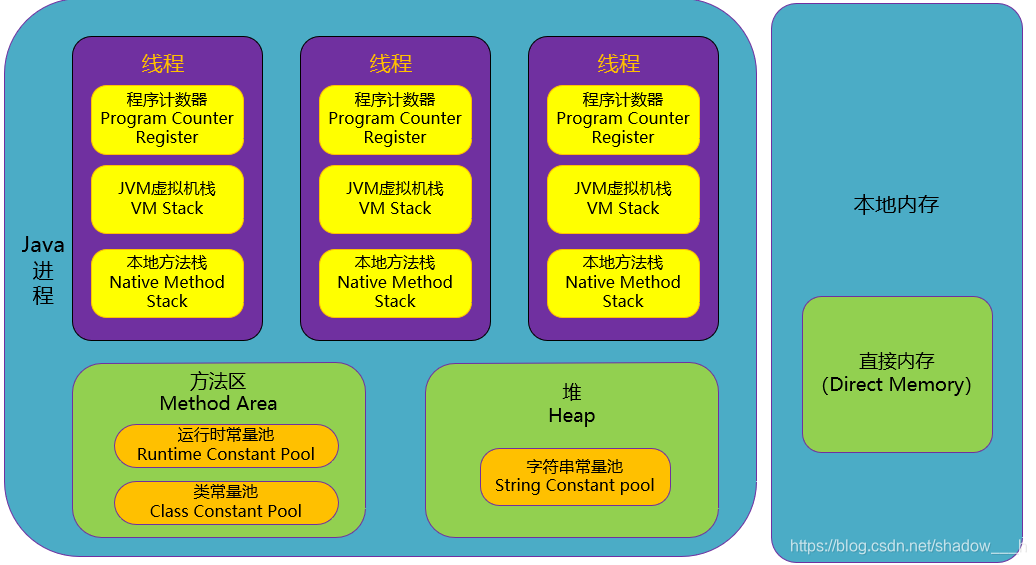
- 程序计数器 (线程私有)
- JVM的虚拟机是通过多线程轮转流切换并分配处理器执行时间的方式来实现,也就是在同一个时间一个cpu只会处理一个线程,而当一个线程被切换出去的时候,要想下次被切换回来的时候还在执行的那个位置,其实程序计数器中就记录了每一个线程执行到了那个位置。也就是记录了当前线程的上下文,线程具体的当前执行到了那个位置。每条线程都有自己独有的线程计数器。程序的上下文切换。
- 不会出现Out0fMemoryError ,它存储的是字节码文件的行号,这样的话内存就是可知的,而这个在开始分配内存的时候就会分配一个绝对不可能溢出的行号。
- 执行native本地方法的时候,计数器的值为空。
- 虚拟机栈(线程私有)
- 简单来说这个就是用来描述JAVA方法执行的内存模型,我们执行一个方法的时候,就会把这个方法的栈帧压入虚拟机栈中,方法执行完之后出栈。
- 存储了局部变量表(8大基本数据类型)和对象引用,局部变量表在所需的内存空间在编译的时候确定
- 本地方法栈 (线程私有)
- 为native方法服务
- java堆 (线程共享)
- 所有的实例对象都在堆上分配
- 是垃圾回收器管理的主要区域
- 字符串常量池是java堆的一部分
- 方法区 (线程共享)
- 存储在已经被虚拟机加载的类信息,常量,静态变量。
- 运行时常量池是方法区的一部分,用于存储字面量和符号引用
内存溢出和内存泄露
- 内存泄露 : 泄露对象无法被GC,简单来说就是一个对象创建之后,这个对象已经不被使用,但是有因为某种原因未被回收,未成为垃圾对象,而导致被分配的内存空间不能再被使用。也可以说我们向系统申请分配内存进行使用,可是使用完了以后却不归还,结果申请到的那块内存你自己也不能再访问,而系统也不能再次将它分配给需要的程序。
- 长生命周期持有短生命周期对象的引用
- 资源数据连接对象不关闭
- 一些对象产生后不会自动释放,只有完全执行
- 内存溢出 : OutOfMemory 我们写代码的时候要求分配的内存超过了系统分配的内存的时候
- 内存泄露不多时没有太大影响, 但积累得多了就会导致应用运动缓慢, 到最后就会内存溢出
类加载
-
一个java代码执行的流程就是
java文件 被执行javac编译成class字节码文件 然后进行java运行执行类加载的过程,最后到运行
class文件中存放着所有类的版本,接口信息,字段和方法,还有一个常量池里面存放着编译阶段所有的符号引用和字面常量,类加载之后符号引用转化成直接引用,这部分信息将会存放与方法区的运行时常量池中存放。
- 符号引用 : 符号引用和虚拟机的实现无关,引用的目标并不一定全部都加载到内存中
- 直接引用 :直接引用是虚拟机实现内存布局相关的,如果有了直接引用,那引用的目标必定已经在内存中存在
-
而类加载的过程一般分为 加载,验证, 准备, 解析, 初始化。解析阶段在某些情况下在初始化之后再开始
-
加载一般有三个事情去做
- 通过一个类的全限定名来获取定义此类的二进制字节流
- 将这个字节流所代表的静态存储结构转化成方法区的运行时数据结构
- 在内存中生成一个代表这个类的Class对象,作为方法区这个类的各种数据的访问入口
-
验证
- 确保Class字节流对象符合虚拟机的规范
-
准备
-
为类变量分配内存并为类变量分配初始值,这些类所需要的内存在方法区中进行分配
假设一个类变量定义为 public static int value = 123; public static String ss = "java";那木在准备阶段的时候 value的值为0 ss的值为null
-
-
解析
- 就是将常量池中符号引用转化成直接引用的过程
-
初始化
- 在准备阶段的时候,变量已经赋过一次系统要求的初始值,而在初始化阶段,就是我们通过程序去初始化类变量和其他资源。
-
类加载机制
类加载器
- 启动类加载器 这个类将器负责将存放在<JAVA_HOME\>\lib目录中的,或者被-Xbootclasspath参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如rt.jar,名字不符合的类库即使放在lib目录中也不会被加载)类库加载到虚拟机内存中。
- 扩展类加载器 它负责加载<JAVA_HOME>\lib\ext目录中的,或者被java.ext.dirs系统变量所指定的路径中的所有类库
- 应用程序类加载器 由于这个类加载器是ClassLoader中的getSystemClassLoader()方法的返回值,所以一般也称它为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库
- 自定义类加载器 (自己写的类加载器)
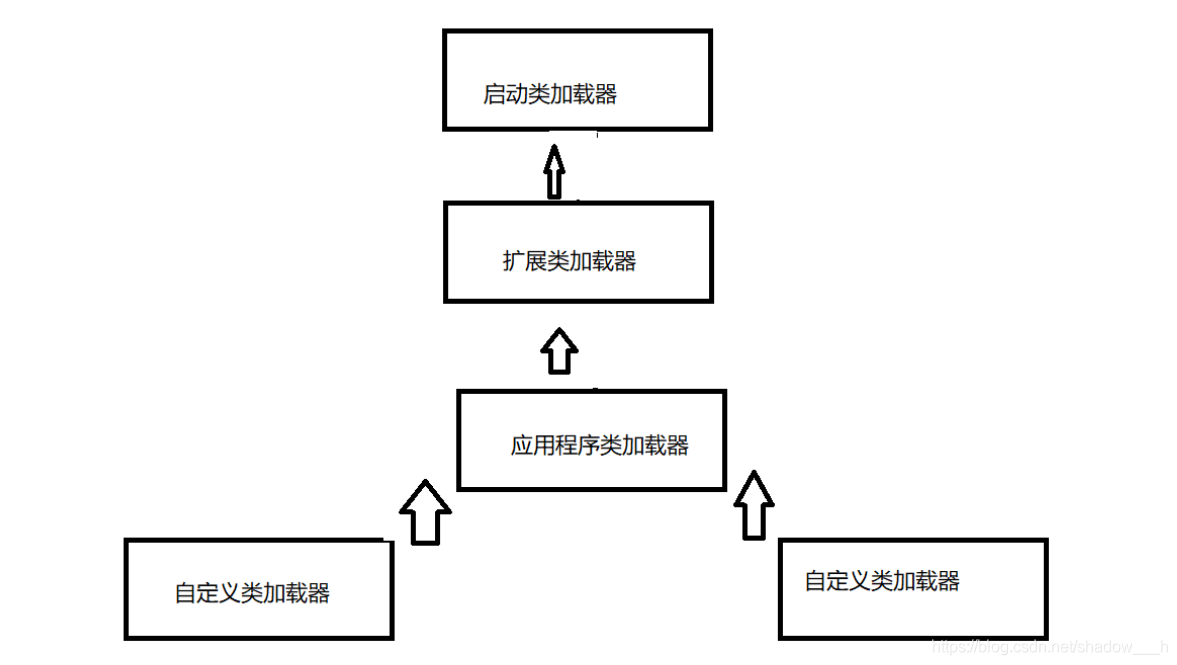
双亲委派模型
-
过程 : 一个类加载收到了类加载的请求,他们首先不会自己去尝试加载这个类,而是会把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该回到启动类加载器中,只有当父类加载器反馈自己无法完成这个加载请求时,子加载器才会尝试自己去加载。
-
优点 :保证了java程序的运行的稳定性。比如如果我们自己写了一个Object类,使用了自己的类加载器去加载,那木导致系统中出现了多个Object类。反之如果使用双亲委派模型的话,启动类加载器已经直接从目录中加载了这个Object对象,那木就不会允许我们写出以 java开头的类比如 : java.lang.String。
-
缺点 无法满足灵活的类加载机制。
- 我们可以通过破坏双亲委派模型来达到这个目的 比如SPI
-
我们通过idea看一下ClassLoader中loadClass方法
第一种
public Class<?> loadClass(String name) throws ClassNotFoundException { return loadClass(name, false); } // 默认为false的加载类第二种
//它第2个 boolean参数,表示目标对象是否进行链接,false表示不进行链接, //不链接包括不进行初始化的一系列操作。 那木静态代码块和静态对象就不会进行执行 protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { // First, check if the class has already been loaded // 首先检查是否加载了该类 Class<?> c = findLoadedClass(name); if (c == null) { long t0 = System.nanoTime(); try { // 如果父类加载器为空,那木由启动类加载器加载此类 if (parent != null) { c = parent.loadClass(name, false); } else { // 启动类加载器加载 c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { // // ClassNotFoundException thrown if class not found // from the non-null parent class loader } if (c == null) { // If still not found, then invoke findClass in order // to find the class. // 如果以上的步骤还没有加载此类,那木使用我们重写的findClass方法加载类 // 我们可以通过重写findClass来进行加载我们自己的写的类 // 前提是我们的父类加载器未加载过这个类 long t1 = System.nanoTime(); c = findClass(name); // this is the defining class loader; record the stats sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0); sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1); sun.misc.PerfCounter.getFindClasses().increment(); } } // 上面传上来的参数 if (resolve) { resolveClass(c); } return c; } } //findClass protected Class<?> findClass(String name) throws ClassNotFoundException { throw new ClassNotFoundException(name); } -
破坏双亲委派模型
- 重写findClass()方法就是我们自定义类加载器
- 想要破坏双亲委派模型,我们可以通过重写LoadClass()方法,比如SPI机制。
-
类的比较
比较两个类相等的前提就是:必须是由同一个类加载器加载的前提下才有意义,否则,即使两个类来源于一个Class文件,被同一个虚拟机加载,只要两个类被加载的类加载器不同,那木这两个类注定不相等。

















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









