



 文章讲述了作者遇到的一个Python爬虫在抓取网页时遇到的停滞问题,发现原因是urllib.request.urlopen()的超时设置。作者通过添加异常处理和设定请求重试策略,优化了代码,使其在请求两次无响应后自动放弃该URL,提高了爬虫的稳定性。
文章讲述了作者遇到的一个Python爬虫在抓取网页时遇到的停滞问题,发现原因是urllib.request.urlopen()的超时设置。作者通过添加异常处理和设定请求重试策略,优化了代码,使其在请求两次无响应后自动放弃该URL,提高了爬虫的稳定性。
写了一个百度通用爬虫,需要对很多的url进行循环处理,获取url的html,程序逻辑没有问题,但是程序经常跑着跑着就停止不动,不报错,所以一句句加输出,最终发现原来是:
pagetext = urllib.request.urlopen(request,data=None,timeout=15).read()
停止都是在这句 查找资料得知,urlopen()有一个超时参数,当长时间获取不到响应时,则报错,所以结合python异常处理,更改代码如下:
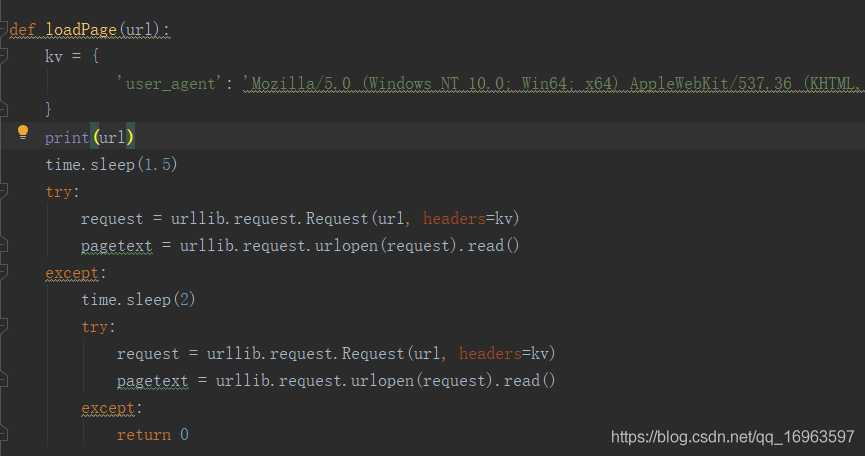
由于url数量较多,在请求了两次无响应则舍弃。


















 964
964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









