




 本文探讨了递归函数的工作原理,指出每次递归调用都会创建新的变量,并占用额外内存。递归可能导致执行速度变慢,消耗大量内存资源,且不易于理解和维护。递归在解决特定问题时虽强大,但需谨慎使用,考虑其性能和内存影响。
本文探讨了递归函数的工作原理,指出每次递归调用都会创建新的变量,并占用额外内存。递归可能导致执行速度变慢,消耗大量内存资源,且不易于理解和维护。递归在解决特定问题时虽强大,但需谨慎使用,考虑其性能和内存影响。
#include <stdio.h>
void up_and_down(int);
int main(void)
{
up_and_down(1);
return 0;
}
void up_and_down(int n)
{
printf("Level %d: n location %p\n", n, &n);
if (n < 4)
up_and_down(n + 1);
printf("LEVEL %d: n location %p\n", n, &n);
}
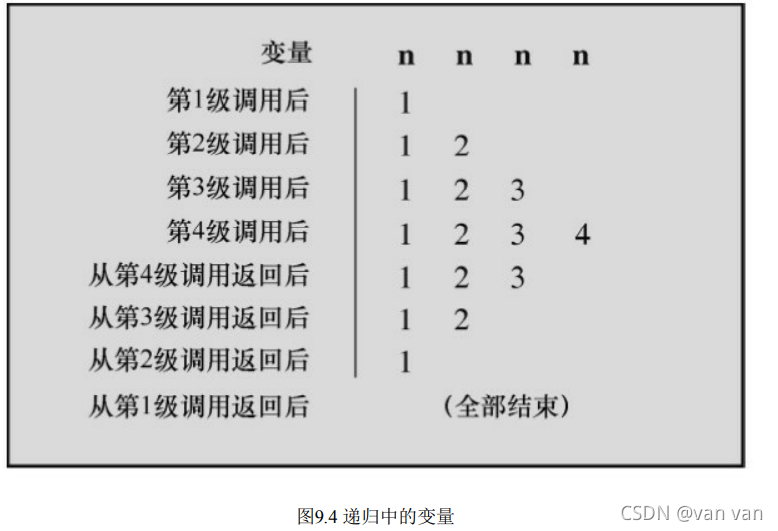
- 每级函数调用都有自己的变量。
第1级的n和第2级的n不同,所以程序创建了4个单独的变量,每个变量名都是n,但是它们的值各
不相同。 - 每次函数调用都会返回一次。
当函数执行完毕后,控制权将被传回上一级递归 - 递归函数中位于递归调用之前的语句,均按被调函数的顺序执行;递归函数中位于递归调用之后的语句,均按被调函数相反的顺序执行。
- 虽然每级递归都有自己的变量,但是并没有拷贝函数的代码。
程序按顺序执行函数中的代码,而递归调用就相当于又从头开始执行函数的代码。
递归缺点
-
每次递归都会创建一组变量,所以递归使用的内存更多,而且每次递归调用都会把创建的一组新变量放在栈中。
-
由于每次函数调用要花费一定的时间,所以递归的执行速度较慢。
-
递归算法会快速消耗计算机的内存资源
-
递归不方便阅读和维护

















 453
453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









