



TCP是面向连接的运输层协议。
众所周知TCP连接的两端都设有发送缓存和接收缓存,用来临时存放双向通信的数据。
TCP不保证接收方应用程序所收到的数据块和发送方应用程序所发出的数据块具有对应大小的关系(这也是TCP粘包现象的由来)。例如发送方一次发送了十个数据块,接收方在接收时可能接收了四个数据块就交付给上层应用程序,导致出现粘包(数据多了)和包缺(数据少了)现象。
在发送时,应用程序在把数据传送给TCP缓存后,TCP在合适的时候把数据发送出去。
在接收时,TCP缓存在接收到数据之后,TCP在合适的时候把数据交给上层应用程序。
注意:这里合适的时候是指综合权衡TCP段的大小、链路利用率以及网卡的繁忙时间等等,例如考虑到效率问题,对积累足够多的字节进行发送/交付。
当然TCP头部中也有着属于自己的"类UDP"属性,即"PSH"字段,全称"Push"。
该字段可以总结为:
当TCP头部字段PSH置位"0"时,该字段功能未启用。
当TCP头部字段PSH置位"1"时,立即尽最大努力快速创建一个TCP报文并发送出去,接收方收到TCP报文并发现其中"PSH"字段置位"1"时,立即尽最大努力快速向上层应用进程交付。
以上操作可以近似理解为立刻发送该数据,不用再等待”合适的时候"。
当两个应用进程进行交互式通信时,有时在一端的通信进程希望在键入一个命令后立即就能够收到对方的响应。如远程登陆Telnet,在这种情况下,TCP头部"PSH"字段就可置位为"1“,即启用Push操作。Telnet服务的TCP头部字段"PSH"是置"1"的,可以理解为默认就是"1"。
我们使用ENSP模拟器抓包查看:
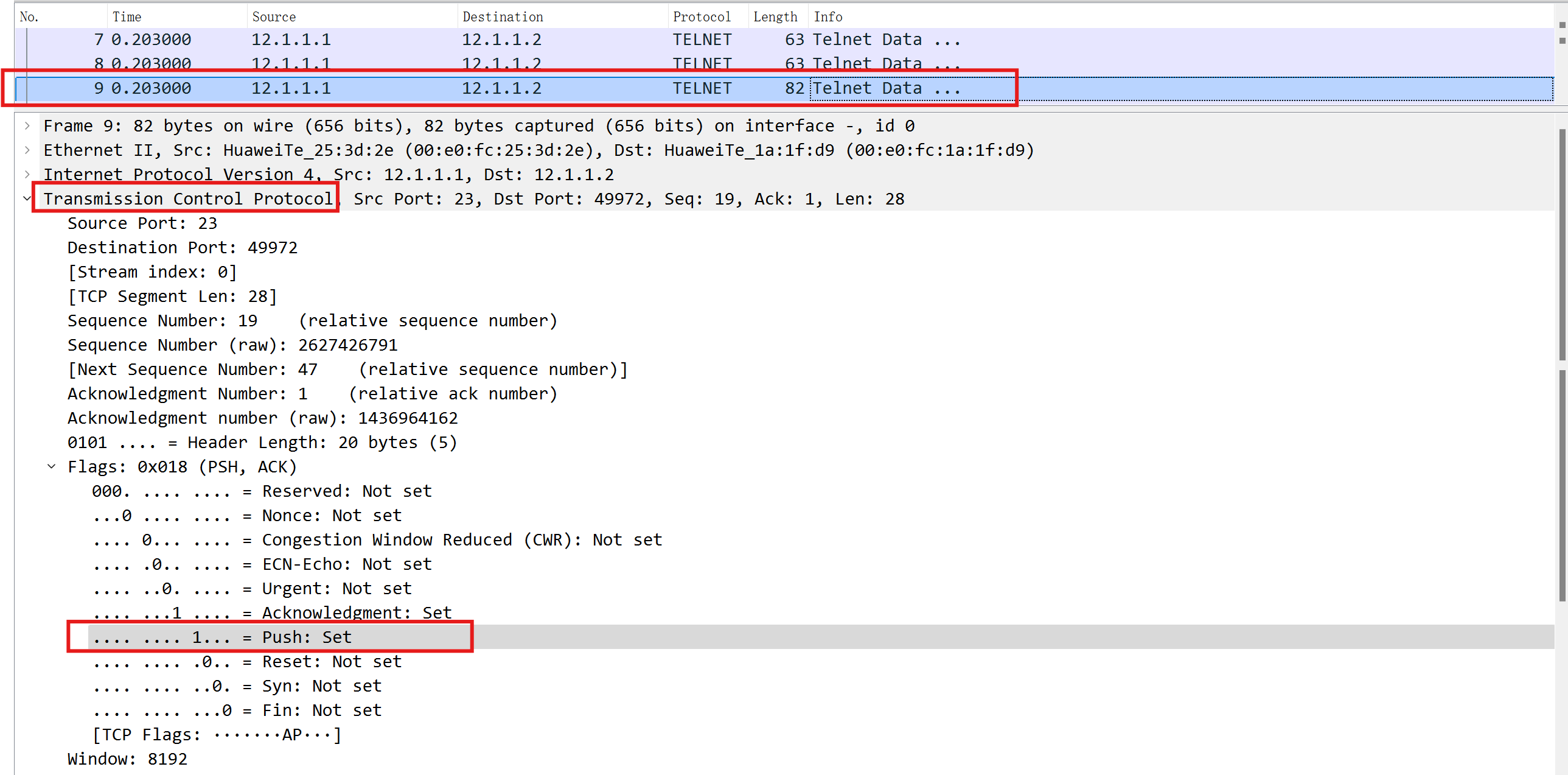
从图中可以看见Telnet应用的TCP头部中的字段"Push"即"PSH"字段置位"1"
以上是小编在学习的过程中一步一步探究仔细思考和发现哒,如果有不合理的地方请指正,谢谢!

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









