






 该博客介绍了一个运行在校园网环境下的程序,使用Python自带库,通过读取邮箱邮件,判断邮件主题,若为“paper download”则读取邮件中的URL,下载知网论文,最后打包附件通过邮件发回。还展示了程序运行各阶段的结果图。
该博客介绍了一个运行在校园网环境下的程序,使用Python自带库,通过读取邮箱邮件,判断邮件主题,若为“paper download”则读取邮件中的URL,下载知网论文,最后打包附件通过邮件发回。还展示了程序运行各阶段的结果图。
1 前言
上次实践课做的一个小东西,程序运行在校园网环境下,运行后不停的读取邮箱里的邮件,每当有新邮件的时候通过判断邮件主题来决定是否执行下载程序,如果主题为paper download就读取邮件中的URL并下载知网论文,完成后再通过邮件发回来。主要用到的是python自带的发送邮件和接收邮件的库,相关知识参考了廖雪峰官方网站的SMTP发邮件和POP3收邮件。
2 读取邮件
while True:
# 输入邮件地址, 口令和POP3服务器地址:
email = 'xxxxxxxx@qq.com'
password = 'xxxxxxxxx' # 邮箱授权码
pop3_server = 'pop.qq.com'
# 连接到POP3服务器:
server = poplib.POP3(pop3_server)
# 可以打开或关闭调试信息:
# server.set_debuglevel(1)
# 可选:打印POP3服务器的欢迎文字:
print(server.getwelcome())
# 身份认证:
server.user(email)
server.pass_(password)
# stat()返回邮件数量和占用空间:
email_num = server.stat()
if os.path.exists('check.txt'):
with open('check.txt', 'r') as fr:
old_index = fr.read()
print(old_index)
if int(old_index) != email_num[0]:
with open('check.txt', 'w') as fw:
fw.write(str(email_num[0]))
resp, mails, octets = server.list()
index = len(mails)
resp, lines, octets = server.retr(index)
lines_str = map(lambda x: x.decode('utf-8'), lines)
msg_content = '\n'.join(lines_str)
# 稍后解析出邮件:
msg = Parser().parsestr(msg_content)
print_info(msg)
# paper_down()调用程序下载paper
else:
print("没有新邮件")
else:
with open('check.txt', 'w') as fw:
fw.write(str(email_num[0]))
server.quit()
time.sleep(30)
3 解析邮件,获取论文地址
def decode_str(s):
value, charset = decode_header(s)[0]
if charset:
value = value.decode(charset)
return value
def guess_charset(msg):
# 先从msg对象获取编码:
charset = msg.get_charset()
if charset is None:
# 如果获取不到,再从Content-Type字段获取:
content_type = msg.get('Content-Type', '').lower()
pos = content_type.find('charset=')
if pos >= 0:
charset = content_type[pos + 8:].strip()
return charset
def print_info(msg, indent=0):
if indent == 0:
# 邮件的From, To, Subject存在于根对象上:
for header in ['From', 'To', 'Subject']:
value = msg.get(header, '')
if value:
if header=='Subject':
# 需要解码Subject字符串:
value = decode_str(value)
global subject
subject = value
global flag_1
flag_1 = 0
elif header=='From':
# 需要解码Email地址:
hdr, addr = parseaddr(value)
name = decode_str(hdr)
value = u'%s <%s>' % (name, addr)
global To
To = value
else:
# 需要解码Email地址:
hdr, addr = parseaddr(value)
name = decode_str(hdr)
value = u'%s <%s>' % (name, addr)
print('%s%s: %s' % (' ' * indent, header, value))
if (msg.is_multipart()):
# 如果邮件对象是一个MIMEMultipart,
# get_payload()返回list,包含所有的子对象:
parts = msg.get_payload()
for n, part in enumerate(parts):
print('%spart %s' % (' ' * indent, n))
print('%s--------------------' % (' ' * indent))
# 递归打印每一个子对象:
print_info(part, indent + 1)
else:
# 邮件对象不是一个MIMEMultipart,
# 就根据content_type判断:
content_type = msg.get_content_type()
if content_type=='text/plain' or content_type=='text/html':
# 纯文本或HTML内容:
content = msg.get_payload(decode=True)
# 要检测文本编码:
charset = guess_charset(msg)
if charset:
content = content.decode(charset)
print('%sText: %s' % (' ' * indent, content))
global Text
Text = content
else:
# 不是文本,作为附件处理:
print('%sAttachment: %s' % (' ' * indent, content_type))
if subject == 'paper download' and flag_1 == 0:
paper_down()
flag_1 = 1
4 分析网页并下载论文
def paper_down():
url = Text.replace("\n", "")
print(url)
down_url = 'http://kns.cnki.net'
header = {
'user-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER"}
res = requests.get(url, headers=header).content.decode('utf-8')
# print(res)
soup_1 = bs4.BeautifulSoup(res, 'lxml')
title = soup_1.select('.title')[0].get_text()
try:
download_url = down_url + soup_1.select('#pdfDown')[0]['href']
filename = title + '.pdf'
except:
pattern = re.compile(r'href="/kns/download(.*?)">整本下载')
result = pattern.findall(res)[0]
download_url = down_url + '/kns/download' + result
filename = title + '.caj'
print(download_url)
with open(filename, 'wb') as f:
response = requests.get(url=download_url, stream=True, headers=header)
total_length = response.headers.get('content-length')
if total_length is None:
f.write(response.content)
else:
dl = 0
total_length = int(total_length)
fsize = total_length / 1024
print(u"文件大小:{}k,正在下载...".format(fsize))
for data in response.iter_content(chunk_size=4096):
dl += len(data)
f.write(data)
done = int(100 * dl / total_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (100 - done)))
sys.stdout.write(u"已下载:{}k\r".format(dl / 1024))
sys.stdout.flush()
print('下载完成!')
print('ok')
send_email(filename)
4 打包附件发送邮件
def send_email(filename):
# 2 发送文件
# 2.1 格式化一个邮件地址和邮箱信息
def _format_addr(s):
name, addr = parseaddr(s)
return formataddr((Header(name, 'utf-8').encode(), addr))
# 2.3 连接服务器
from_addr = "xxxx@foxmail.com" # 发件人邮箱
password = "xxxx" # 发件人邮箱授权码(不是密码)
to_addr = "xxx@foxmail.com" # 收件人邮箱
smtp_server = "smtp.qq.com" # SMTP服务器地址
# 邮件发件人和收件人名字、主题
msg = MIMEMultipart()
msg['From'] = _format_addr('xxx<%s>' % from_addr)
msg['To'] = _format_addr(To)
msg['Subject'] = Header('paper download', 'utf-8').encode()
print(To)
# 传入邮件正文MIMEText
msg.attach(MIMEText('your downloading paper is coming.', 'plain', 'utf-8'))
# 添加附件,附件就是浏览器的历史记录解析后的文件了(一个txt文件),MIMEBase,从本地读取一个txt文件
# 设置附件的MIME和文件名,这里是py类型
mime = MIMEBase('temp', 'html', filename=filename)
# 加上必要的头信息
mime.add_header('Content-Disposition', 'attachment', filename=filename)
mime.add_header('Content-ID', '<0>')
mime.add_header('X-Attachment-Id', '0')
mimestr = open(filename, 'rb')
# 把附件内容读进来
mime.set_payload(mimestr.read())
# 用Base64编码
encoders.encode_base64(mime)
# 添加到MIMEMultipart
msg.attach(mime)
mimestr.close()
# 2.4 通过SMTP发送出去
server = smtplib.SMTP(smtp_server, 25)
server.set_debuglevel(1)
server.ehlo()
server.starttls()
server.login(from_addr, password)
server.sendmail(from_addr, [To], msg.as_string())
server.quit()
return
5 程序运行结果
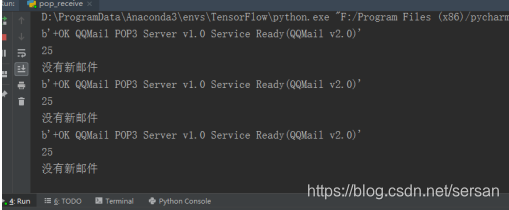
图1 读取邮件过程
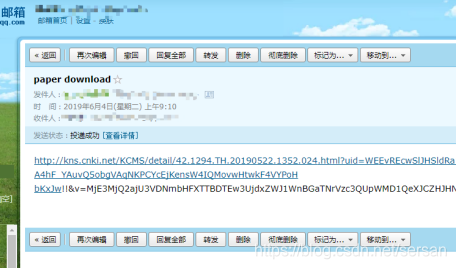
图2 发送请求邮件
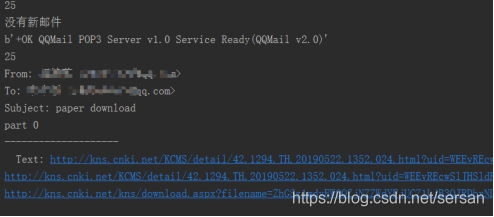
图3 解析邮件
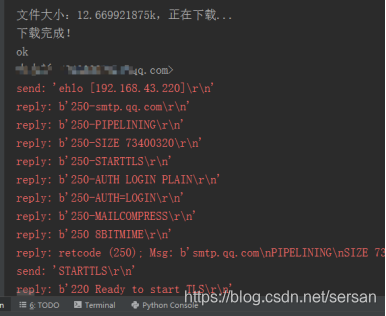
图4 下载论文
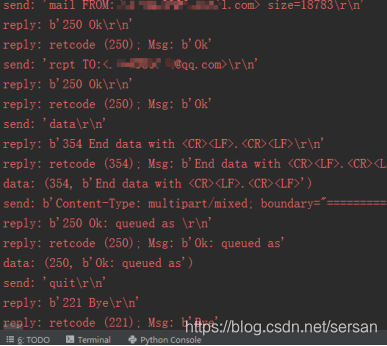
图5 发送带论文的邮件
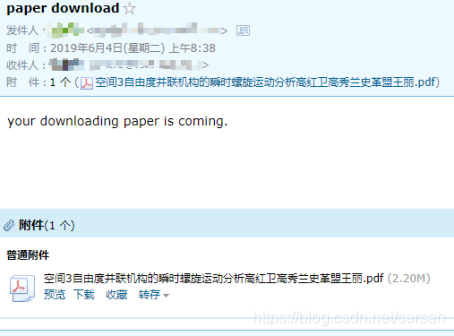
图6 接收到的论文邮件

















 2990
2990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









