



本文为您介绍如何通过日志服务的直接投递功能迁移日志数据至MaxCompute。
前提条件
-
执行本操作的账号为主账号。
-
已开通日志服务,详情请参见开通日志服务。
背景信息
日志服务提供将实时采集的日志数据投递至MaxCompute的功能。如果启用该功能,日志服务后台会定时把写入到该日志库内的日志数据投递到MaxCompute对应的表中,方便您对数据进行后续加工。
操作步骤
-
在MaxCompute客户端(odpscmd)执行如下语句创建表loghub,用于接收日志服务投递数据。
CREATE TABLE loghub ( id BIGINT, name STRING, salenum BIGINT ) PARTITIONED BY (ds string); -
在日志服务中创建Project和Logstore。
-
登录日志服务控制台,在Project列表区域,单击右上角创建Project,填写配置信息创建新的Project。配置参数说明请参见创建Project。
-
单击已经创建的Project,进入日志管理页面。
-
单击日志库后的

新建Logstore,并填写配置参数。配置参数说明请参见创建Logstore。
-
单击Logstore的名称,即可查看Logstore的日志数据。
-
-
在日志存储>日志库页签中,单击目标Logstore左侧的>,选择数据处理 > 导出 > MaxCompute(原ODPS)。
-
单击MaxCompute(原ODPS)后的+,在MaxCompute数据投递对话框页面配置相关参数。
配置参数说明如下。
参数
语义
投递名称
自定义一个投递的名称,方便后续管理。
项目名
MaxCompute表所在的项目名称,该项默认为新创建的Project,对于已经创建的Project,可以在下拉框中选择。
MaxCompute表名
MaxCompute表名称,请输入自定义新建的MaxCompute表名称或者选择已有的MaxCompute表。
说明
MaxCompute表至少包含一个数据列和一个分区列。
MaxCompute普通列
按顺序左边填写与MaxCompute表数据列映射的日志服务字段名称,右边填写或者选择MaxCompute表的普通字段名称及字段类型。
说明
日志服务数据的一个字段最多允许映射到一个MaxCompute表的列(数据列或分区列),不支持字段冗余,同一个字段名第二次使用时其投递的值为null,如果null出现在分区列会导致数据无法被投递。
MaxCompute分区列
按顺序左边填写与MaxCompute表分区列映射的日志服务字段名称,右边填写或者选择MaxCompute表的普通字段名称及字段类型。
重要
-
投递MaxCompute是批量任务,需谨慎设置分区列及其类型。保证一个同步任务内处理的数据分区数小于512个。用作分区列的字段值不能为空或包括正斜线(/)等MaxCompute保留字段。
-
MaxCompute单表有分区数目6万的限制,分区数超出后无法再写入数据,所以日志服务导入MaxCompute表至多支持3个分区列。需谨慎选择自定义字段作为分区列,保证其值可枚举。
时间分区格式
__partition_time__输出的日期格式。例如yyyy-MM-dd。导入时间间隔
MaxCompute数据投递间隔,默认1800,单位:秒(s)。
说明
-
不同Logstore的数据不能导入到同一个MaxCompute表中,否则会造成分区冲突或丢失数据。
-
海外Region不支持通过LogHub将数据投递至MaxCompute,可以使用DataWorks进行数据投递。详情请参见通过DataWorks数据集成迁移日志数据至MaxCompute。
-
MaxCompute投递新版说明请参见创建MaxCompute投递任务(新版)。
-
-
配置完成后,单击确定,启动投递。
启动投递功能后,日志服务后台会定期启动离线投递任务。
-
在提示对话框,单击确定,返回日志服务控制台查看投递运行状态。

-
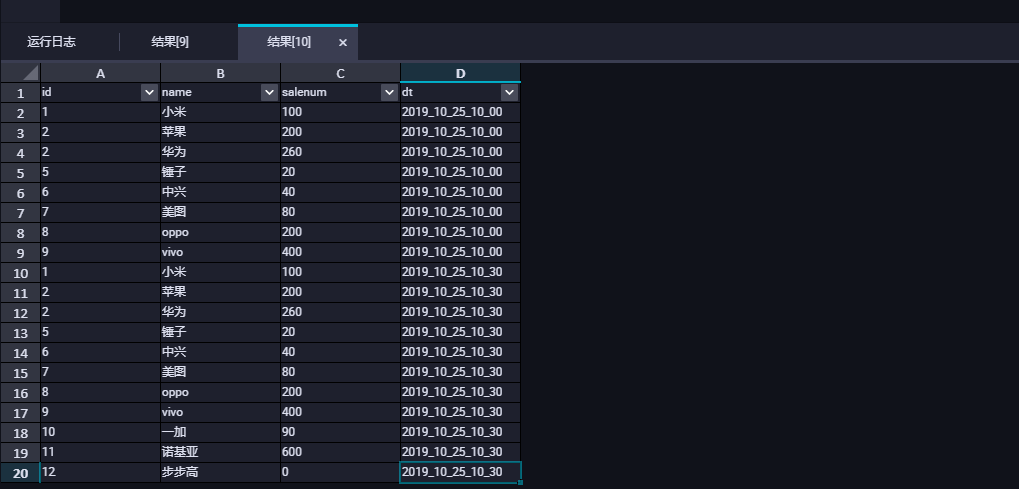
执行如下语句在MaxCompute中查询表数据,检查日志投递结果。
SELECT id,name,salenum,dt FROM loghub WHERE substr(dt,1,18) = '2019_10_25';返回结果如下,说明投递成功。

















 1291
1291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









