




 本文深入解析逻辑回归算法,从背景到模型构建,详细介绍了信号函数及其应用,损益函数的定义与计算,以及如何通过梯度下降法优化模型参数。同时,文章探讨了高级优化算法的应用及多分类问题的解决方案。
本文深入解析逻辑回归算法,从背景到模型构建,详细介绍了信号函数及其应用,损益函数的定义与计算,以及如何通过梯度下降法优化模型参数。同时,文章探讨了高级优化算法的应用及多分类问题的解决方案。
向Andrew Ng的机器学习课程致敬
逻辑回归(分类算法)
背景
邮件中有垃圾邮件和正常邮件,如何过分辨垃圾邮件和正常邮件,从而过滤掉垃圾邮件。将正常与非正常分别用0,1来表示,则需要预测值为{0,1}这个集合中。
模型
模型公式为:
这其实是一个信号函数,模型的曲线为下图的右下角:
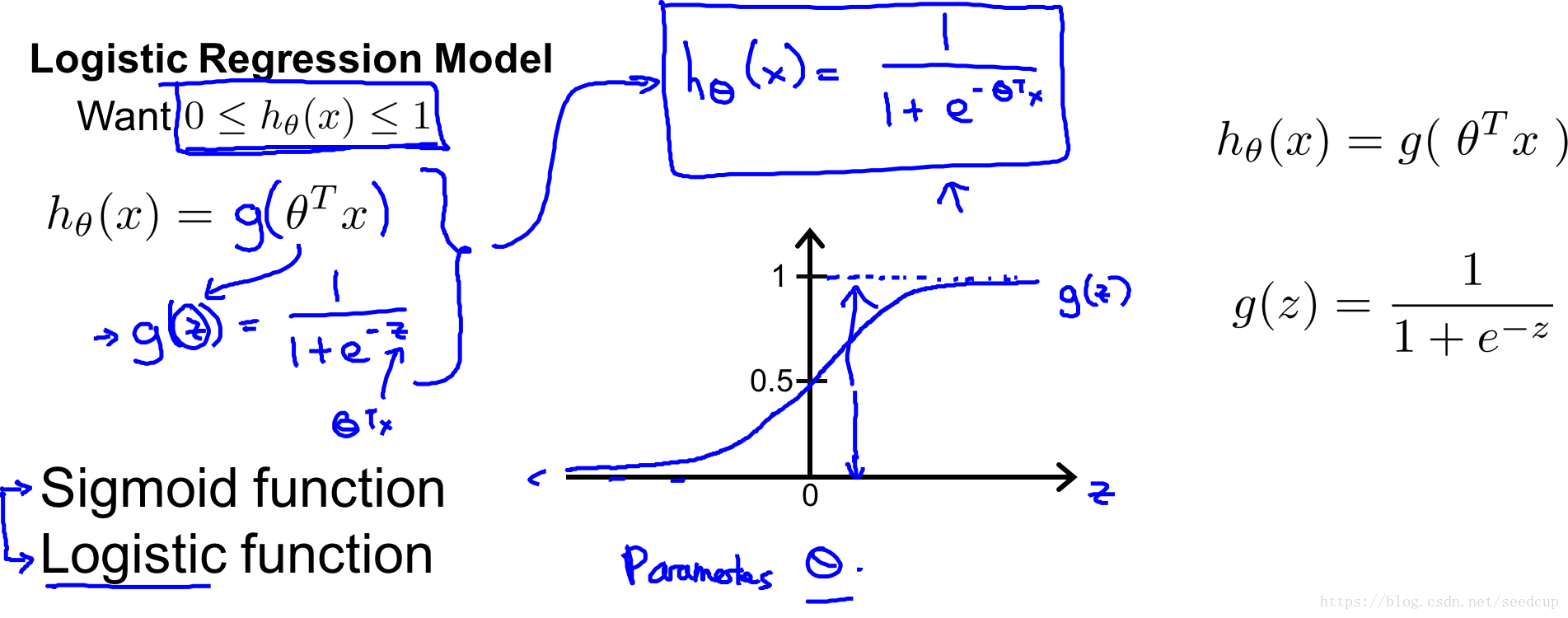
- hθ(x) h θ ( x ) 表示给定x的值后该模型上 y=1 y = 1 的概率
- 0<=hθ(x)<=1 0 <= h θ ( x ) <= 1 ,然后设定一个阈值,比如0.5,则高于0.5认为是1,低于0.5是0。这样就可以达到分类的效果。
我们拆分模型来看,其实是两个公式拼凑到一块:
如果 hθ(x)>=0.5 h θ ( x ) >= 0.5 意味着 θTx>=0 θ T x >= 0
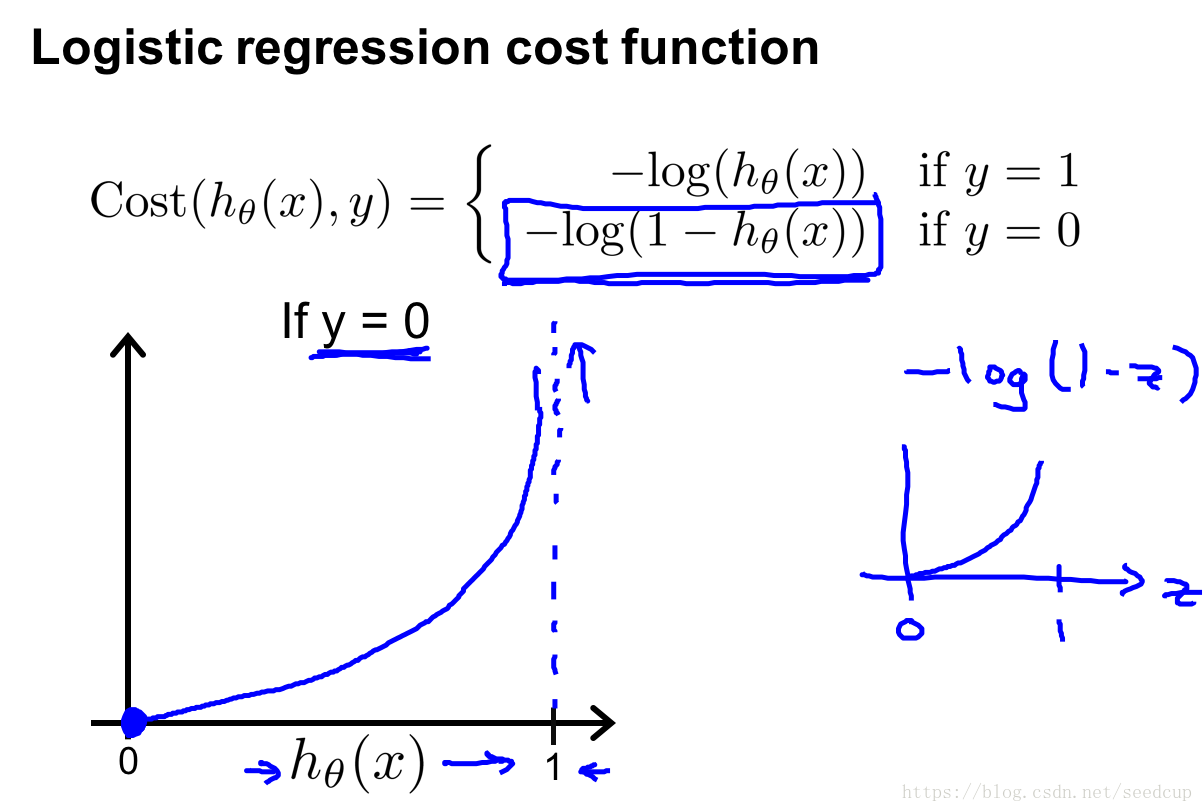
损益函数
函数
如果模型预测值与真实值一致,那模型就非常完美了。为了计算模型与真实值的差距,根据差距大小以此来选择合适的模型参数,让模型最接近真实值是模型的优化方向。为此定义如下损益函数来计算逻辑回归模型的预测值与真实值的差距:
如下面两图左下角所示,上面是当 y=1 y = 1 时的曲线图,下面是 y=0 y = 0 时的曲线图。

梯度下降法优化模型
为了更适合用梯度下降算法求解参数,转化一下损益函数为下面格式:
每次迭代更新参数方式为:
高级优化算法
- Conjugate gradient
- BFGS
- L-BFGS
这些算法不用选学习率,并且更快,但是比较复杂。暂时不介绍这些算法,于我们理解模型没有什么太大用处。
多分类
多分类问题是二分类的一个扩展,如下图所示,一个数据集里有三种类型数据,如何区分?
直观的想法是,将其转换为二分类问题,属于某一类和不属于某一类,这样分多次就形成了多分类模型。

具体的做法就是:
1. 为每一类
i
i
数据训练一个模型
2. 对每个数据都使用所有模型求出预测值,将该数据分类为模型值最大的那个分类,即
Max h(i)θ(x)
M
a
x
h
θ
(
i
)
(
x
)

















 1806
1806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









