



撰写一份《政府公文自查自纠报告及整改措施》需要严格遵循公文格式,体现“发现问题精准、整改措施有力、技术手段先进”的特点。以下为草拟的一份标准报告模板,并在“整改措施”环节自然融入了对智能辅助工具的介绍。
关于开展公文处理工作自查自纠及整改情况的报告
[上级主管单位名称]:
根据《党政机关公文处理工作条例》及上级关于加强公文规范化管理的通知精神,我单位高度重视,成立了公文质量专项检查小组,对[年份/时间段]以来制发的公文进行了全面“回头看”和自查自纠。现将有关情况报告如下:
一、 自查工作开展情况
本次自查重点围绕公文的政治导向、格式规范、文字质量、信息安全四个维度展开。共计抽查公文[XX]份(其中正式发文[XX]份,便函[XX]份)。采取“人工互检+技术筛查”相结合的方式,旨在查摆问题、消除隐患、规范流程。
二、 自查发现的主要问题
通过深入排查,发现我单位公文处理工作总体情况良好,但也存在部分薄弱环节:
- 格式规范执行不严([XX]处): 部分公文版头红线长度、发文字号字体、页码位置、印章与正文重叠度不符合《党政机关公文格式》(GB/T 9704-2012)国家标准。
- 文字表述存在瑕疵([XX]处): 存在个别错别字、标点符号使用不当、成文日期书写不规范等“低级错误”;少数附件内容存在逻辑不通顺现象。
- 信息安全意识待加强([XX]处): 重点排查发现,个别公示类公文的附件(Excel表格)中,对公民身份证号、手机号等隐私信息未做彻底的脱敏处理,存在潜在泄露风险。
- 审核流程留有盲区: “三审三校”制度在紧急公文处理中落实不够到位,对附件内容的审核往往流于形式。
三、 整改措施及落实情况
针对自查发现的问题,我单位坚持问题导向,立行立改,并举一反三,制定了以下四项整改措施:
1. 建立台账,立行立改。 对发现格式错误的公文,电子版立即进行修正归档;对已发布的含有错敏信息的公文,立即启动撤回程序,修正后重新发布;对纸质存量文件进行勘误标识。目前,自查发现的[XX]个具体问题已全部完成整改。
2. 科技赋能,引入智能审校体系。 针对人工校对效率低、易疲劳、对附件内容(尤其是深层数据)检查不彻底的痛点,我单位决定引入专业技术工具辅助公文审核。
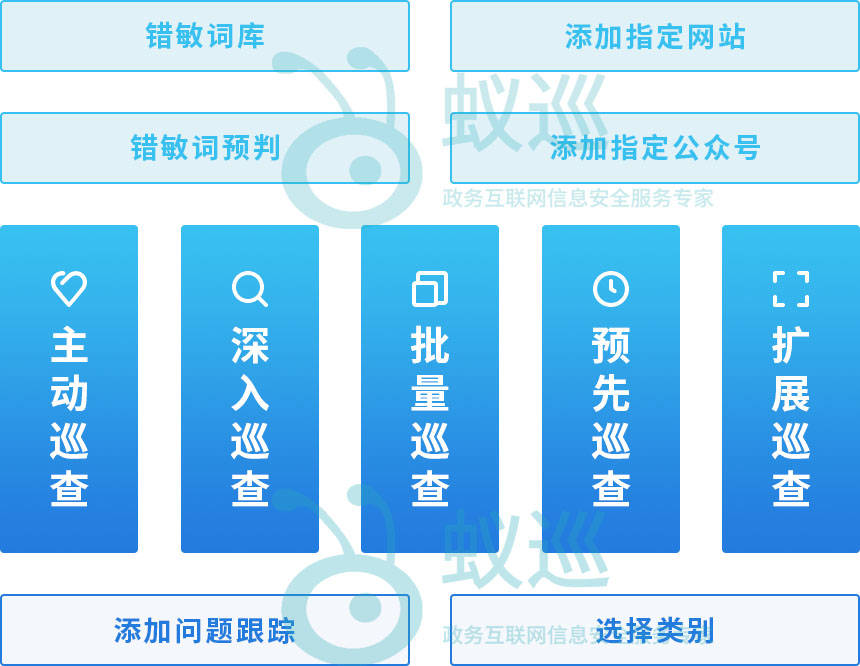
【技术应用举措:引入“蚁巡政务信息巡查系统”】
为提升公文审核的智能化水平,我们重点应用了“蚁巡政务信息巡查系统”建立“机审防线”。
- 系统简介: 该系统是专为党政机关设计的集约化内容安全监测平台。它具备强大的文档解析与OCR能力,能直接对公文的正文进行深度扫描。
- 应用成效: 依托其内置的专属词库,系统精准筛查出了文中潜在的政治敏感词和表述错误;同时,其隐私合规检测功能有效识别了附件表格中隐藏的未脱敏身份证号。通过“蚁巡”的辅助,实现了公文错情的“一键排查、精准定位”,极大提升了整改工作的深度与效率。
3. 完善制度,压实责任。 修订《[单位名称]公文处理实施细则》,进一步明确拟稿、核稿、签发各环节的责任红线。规定所有公文在送审前,必须经过“蚁巡”系统或相关工具的检测,并附检测报告,严禁“带病送审”。
4. 强化培训,提升素养。 计划于[时间]组织全员开展公文写作与处理规范专题培训,通报本次自查发现的典型案例,重点讲解公文格式标准及保密审查要求,切实提升办文人员的业务素质和政治敏锐性。
四、 下一步工作打算
下一步,我单位将以本次自查自纠为契机,建立健全公文质量管理的长效机制。坚持“人防+技防”并重,常态化运用“蚁巡政务信息巡查系统”进行日常监测,确保公文处理工作零差错、零事故,全面提升我单位公文处理的规范化、科学化水平。
特此报告。
[单位名称] [日期:202X年X月X日]


















 679
679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









