




 本文介绍了如何使用torch.utils.data模块在PyTorch中创建自定义数据集,并通过random_split划分训练集、验证集和测试集,同时展示了通过普通遍历和DataLoader进行样本加载的方法。
本文介绍了如何使用torch.utils.data模块在PyTorch中创建自定义数据集,并通过random_split划分训练集、验证集和测试集,同时展示了通过普通遍历和DataLoader进行样本加载的方法。
- 实例 1:自定义数据集类,torch.utils.data.random_split() 划分训练集和测试集,通过普通遍历方式使用自定义数据集中的样本
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
random_data = np.random.randn(10,3)
print(random_data)
print("#"*len(random_data))
class MyDataSet(Dataset):
def __init__(self, loaded_data):
self.data = loaded_data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
custom_dataset = MyDataSet(random_data)
for i in range(len(custom_dataset)):
print(custom_dataset[i])
train_size = int(len(custom_dataset) * 0.7)
test_size = len(custom_dataset) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(custom_dataset, [train_size, test_size])
print(len(train_dataset))
print(len(test_dataset))
print("#"*len(custom_dataset))
for i in range(len(train_dataset)):
print(train_dataset[i])
print("#"*len(train_dataset))
for i in range(len(test_dataset)):
print(test_dataset[i])
-
输出:
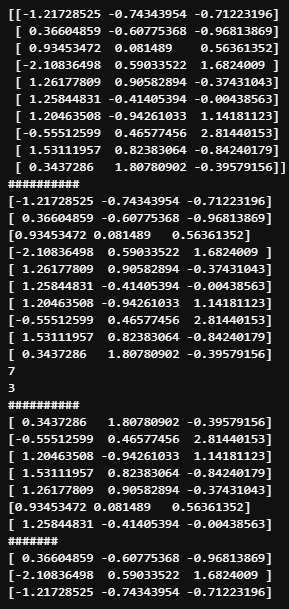
-
实例 2:自定义数据集类,torch.utils.data.random_split() 划分训练集和测试集,通过 dataloader 方式使用自定义数据集中的样本
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
random_data = np.random.randn(10,3)
print(random_data)
print("#"*len(random_data))
class MyDataSet(Dataset):
def __init__(self, loaded_data):
self.data = loaded_data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
custom_dataset = MyDataSet(random_data)
for i in range(len(custom_dataset)):
print(custom_dataset[i])
train_size = int(len(custom_dataset) * 0.5)
validate_size = int(len(custom_dataset) * 0.2)
test_size = len(custom_dataset) - validate_size - train_size
train_dataset, validate_dataset, test_dataset = torch.utils.data.random_split(custom_dataset, [train_size, validate_size, test_size])
train_loader = DataLoader(train_dataset, batch_size=1, shuffle=False, num_workers=0)
validate_loader = DataLoader(validate_dataset, batch_size=1, shuffle=False, num_workers=0)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False, num_workers=0)
print(len(train_loader))
print(len(validate_loader))
print(len(test_loader))
for i, train_sample in enumerate(train_loader):
print("{} {}".format(i, train_sample))
for j, validate_sample in enumerate(validate_loader):
print("{} {}".format(j, validate_sample))
for k, test_sample in enumerate(test_loader):
print("{} {}".format(k, test_sample))
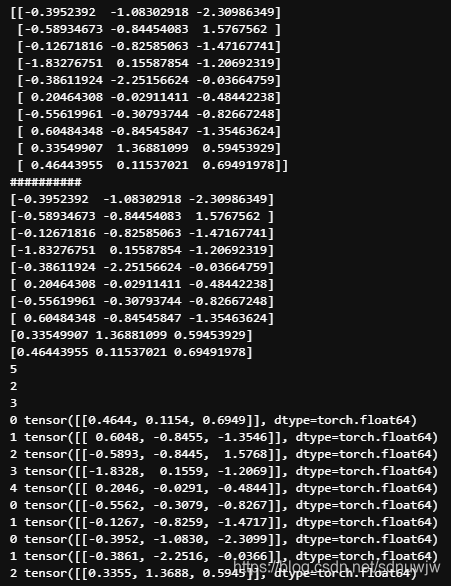
参考
- https://pytorch.org/tutorials/recipes/recipes/custom_dataset_transforms_loader.html?highlight=custom%20dataset



















 4万+
4万+







 到【灌水乐园】发言
到【灌水乐园】发言









