




 本文介绍使用sklearn的SimpleImputer处理数据集中的缺失值,包括不同数据分布情况下的插补策略,如均值、固定值填充,并展示了具体实例。
本文介绍使用sklearn的SimpleImputer处理数据集中的缺失值,包括不同数据分布情况下的插补策略,如均值、固定值填充,并展示了具体实例。
一、环境
Python 3.7.3(Anaconda 3)
sklearn.version’0.20.3’
二、方法
对数据中的缺失值进行插补
官方说明:https://scikit-learn.org/stable/modules/generated/sklearn.impute.SimpleImputer.html
三、实例
1、数据 - 缺失值 - 数据
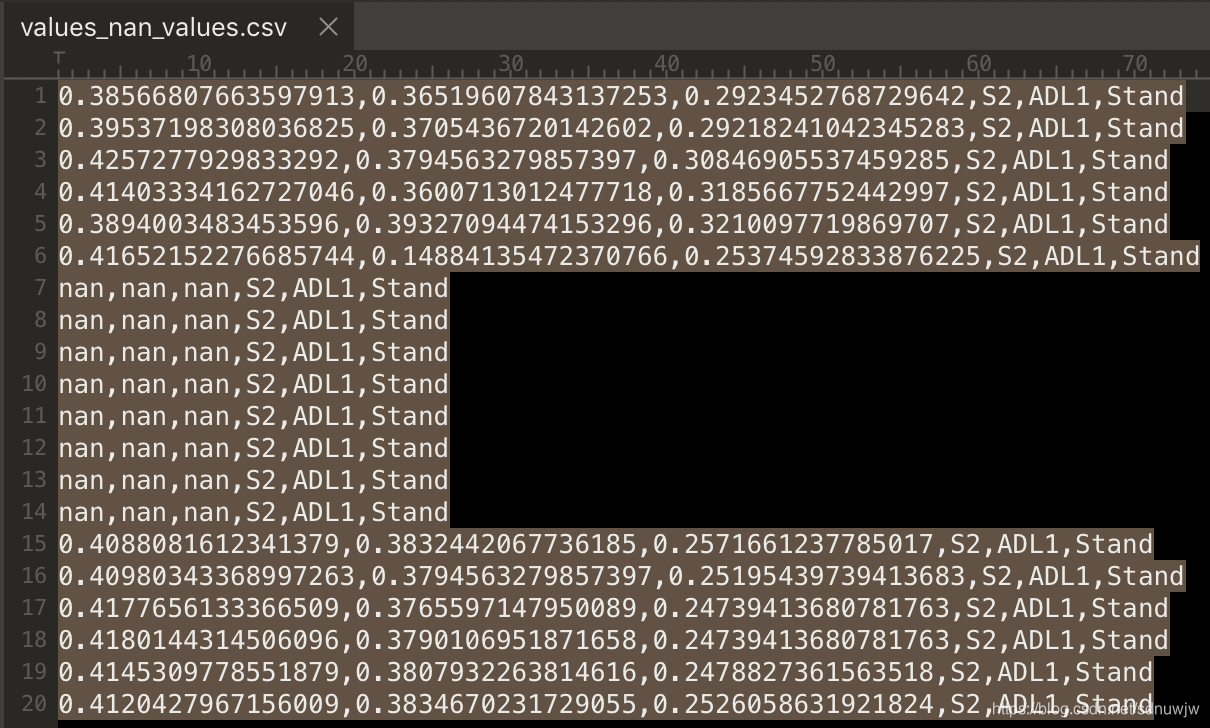
# 中间部分数据存在缺失值
>>> import numpy as np
>>> from sklearn.impute import SimpleImputer
>>> data1 = np.loadtxt("/test/data/values_nan_values.csv", delimiter=',', dtype='str')
>>> data1_values = data1[:,0:3]
>>> data1_values
array([['0.38566807663597913', '0.36519607843137253',
'0.2923452768729642'],
['0.39537198308036825', '0.3705436720142602',
'0.29218241042345283'],
['0.4257277929833292', '0.3794563279857397',
'0.30846905537459285'],
['0.41403334162727046', '0.3600713012477718',
'0.3185667752442997'],
['0.3894003483453596', '0.39327094474153296',
'0.3210097719869707'],
['0.41652152276685744', '0.14884135472370766',
'0.25374592833876225'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['0.4088081612341379', '0.3832442067736185', '0.2571661237785017'],
['0.40980343368997263', '0.3794563279857397',
'0.25195439739413683'],
['0.4177656133366509', '0.3765597147950089',
'0.24739413680781763'],
['0.4180144314506096', '0.3790106951871658',
'0.24739413680781763'],
['0.4145309778551879', '0.3807932263814616', '0.2478827361563518'],
['0.4120427967156009', '0.3834670231729055', '0.2526058631921824']],
dtype='<U19')
>>> imputation_transformer1 = SimpleImputer(np.nan, "mean")
>>> values_nan_values1 = imputation_transformer1.fit_transform(data1_values)
>>> values_nan_values1
array([[0.38566808, 0.36519608, 0.29234528],
[0.39537198, 0.37054367, 0.29218241],
[0.42572779, 0.37945633, 0.30846906],
[0.41403334, 0.3600713 , 0.31856678],
[0.38940035, 0.39327094, 0.32100977],
[0.41652152, 0.14884135, 0.25374593],
[0.40897404, 0.35832591, 0.27422638],
[0.40897404, 0.35832591, 0.27422638],
[0.40897404, 0.35832591, 0.27422638],
[0.40897404, 0.35832591, 0.27422638],
[0.40897404, 0.35832591, 0.27422638],
[0.40897404, 0.35832591, 0.27422638],
[0.40897404, 0.35832591, 0.27422638],
[0.40897404, 0.35832591, 0.27422638],
[0.40880816, 0.38324421, 0.25716612],
[0.40980343, 0.37945633, 0.2519544 ],
[0.41776561, 0.37655971, 0.24739414],
[0.41801443, 0.3790107 , 0.24739414],
[0.41453098, 0.38079323, 0.24788274],
[0.4120428 , 0.38346702, 0.25260586]])
2、数据 - 缺失值
# 后半部分数据存在缺失值
>>> import numpy as np
>>> from sklearn.impute import SimpleImputer
>>> data2 = np.loadtxt("/test/data/values_nan.csv", delimiter=',', dtype='str')
>>> data2_values = data2[:,0:3]
>>> data2_values
array([['0.38566807663597913', '0.36519607843137253',
'0.2923452768729642'],
['0.39537198308036825', '0.3705436720142602',
'0.29218241042345283'],
['0.4257277929833292', '0.3794563279857397',
'0.30846905537459285'],
['0.41403334162727046', '0.3600713012477718',
'0.3185667752442997'],
['0.3894003483453596', '0.39327094474153296',
'0.3210097719869707'],
['0.41652152276685744', '0.14884135472370766',
'0.25374592833876225'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan']], dtype='<U19')
>>> imputation_transformer2 = SimpleImputer(np.nan, "mean")
>>> values_nan = imputation_transformer2.fit_transform(data2_values)
>>> values_nan
array([[0.38566808, 0.36519608, 0.29234528],
[0.39537198, 0.37054367, 0.29218241],
[0.42572779, 0.37945633, 0.30846906],
[0.41403334, 0.3600713 , 0.31856678],
[0.38940035, 0.39327094, 0.32100977],
[0.41652152, 0.14884135, 0.25374593],
[0.40445384, 0.33622995, 0.29771987],
[0.40445384, 0.33622995, 0.29771987],
[0.40445384, 0.33622995, 0.29771987],
[0.40445384, 0.33622995, 0.29771987],
[0.40445384, 0.33622995, 0.29771987],
[0.40445384, 0.33622995, 0.29771987],
[0.40445384, 0.33622995, 0.29771987],
[0.40445384, 0.33622995, 0.29771987]])
3、缺失值 - 数据
# 前半部分数据存在缺失值
>>> import numpy as np
>>> from sklearn.impute import SimpleImputer
>>> data3 = np.loadtxt("/test/data/nan_values.csv", delimiter=',', dtype='str')
>>> data3_values = data3[:,0:3]
>>> data3_values
array([['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['0.4088081612341379', '0.3832442067736185', '0.2571661237785017'],
['0.40980343368997263', '0.3794563279857397',
'0.25195439739413683'],
['0.4177656133366509', '0.3765597147950089',
'0.24739413680781763'],
['0.4180144314506096', '0.3790106951871658',
'0.24739413680781763'],
['0.4145309778551879', '0.3807932263814616', '0.2478827361563518'],
['0.4120427967156009', '0.3834670231729055', '0.2526058631921824']],
dtype='<U19')
>>> imputation_transformer3 = SimpleImputer(np.nan, "mean")
>>> nan_values3 = imputation_transformer3.fit_transform(data3_values)
>>> nan_values3
array([[0.41349424, 0.38042187, 0.2507329 ],
[0.41349424, 0.38042187, 0.2507329 ],
[0.41349424, 0.38042187, 0.2507329 ],
[0.41349424, 0.38042187, 0.2507329 ],
[0.41349424, 0.38042187, 0.2507329 ],
[0.41349424, 0.38042187, 0.2507329 ],
[0.41349424, 0.38042187, 0.2507329 ],
[0.41349424, 0.38042187, 0.2507329 ],
[0.40880816, 0.38324421, 0.25716612],
[0.40980343, 0.37945633, 0.2519544 ],
[0.41776561, 0.37655971, 0.24739414],
[0.41801443, 0.3790107 , 0.24739414],
[0.41453098, 0.38079323, 0.24788274],
[0.4120428 , 0.38346702, 0.25260586]])
4、缺失值
# 某一数据文件中全部是缺失值
>>> import numpy as np
>>> from sklearn.impute import SimpleImputer
>>> data4 = np.loadtxt("/test/data/nan.csv", delimiter=',', dtype='str')
>>> data4_values = data4[:,0:3]
>>> data4_values
array([['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan'],
['nan', 'nan', 'nan']], dtype='<U5')
>>> nan = imputation_transformer4.fit_transform(data4_values)
>>> nan
array([], shape=(8, 0), dtype=float64)
第四种情况比较特殊,在加载多个数据文件中不同类型的数据,可以会遇到某一文件中的特定数据全部为 nan 值,这种情况在传感器数据中是存在的!sklearn.imputer.SimpleImputer() 是可以处理这种情况的,即把所以的 nan 值最终处理为一个空的数组,实际sklearn.imputer.SimpleImputer() 方法中也可以通过固定的数据来填补这些空值
5、固定替换缺失值
# 将参数 strategy 设置为 constant,参数 fill_value 设置为指定数值,如 0
>>> imputation_transformer5 = SimpleImputer(missing_values=np.nan, strategy="constant", fill_value=0)
>>> values_nan_values5 = imputation_transformer5.fit_transform(data5_values)
正常应该可以间给所有的 nan 用 0 代替,但是这里报错:
“with an object dtype.”.format(X.dtype))
ValueError: SimpleImputer does not support data with dtype <U5. Please provide either a numeric array (with a floating point or integer dtype) or categorical data represented either as an array with integer dtype or an array of string values with an object dtype.
将原数据中的 nan,使用 astype() 转换为字符串格式也是提示该错误!


















 1705
1705



 到【灌水乐园】发言
到【灌水乐园】发言









