






一、基础问答
进入DB-GPT后,再在线对话默认的基础功能就是对话功能。这里我们可以和使用通义千问、文心一言等在线大模型类似的方法, 来和DB-GPT进行对话。
但是值得注意的是,DB-GPT的输出结果是在内置提示词基础之上进行的回答,也就是说在DB-GPT中我们传输给模型任何问题,都会经过提示词模板修改后传输给底层模型。
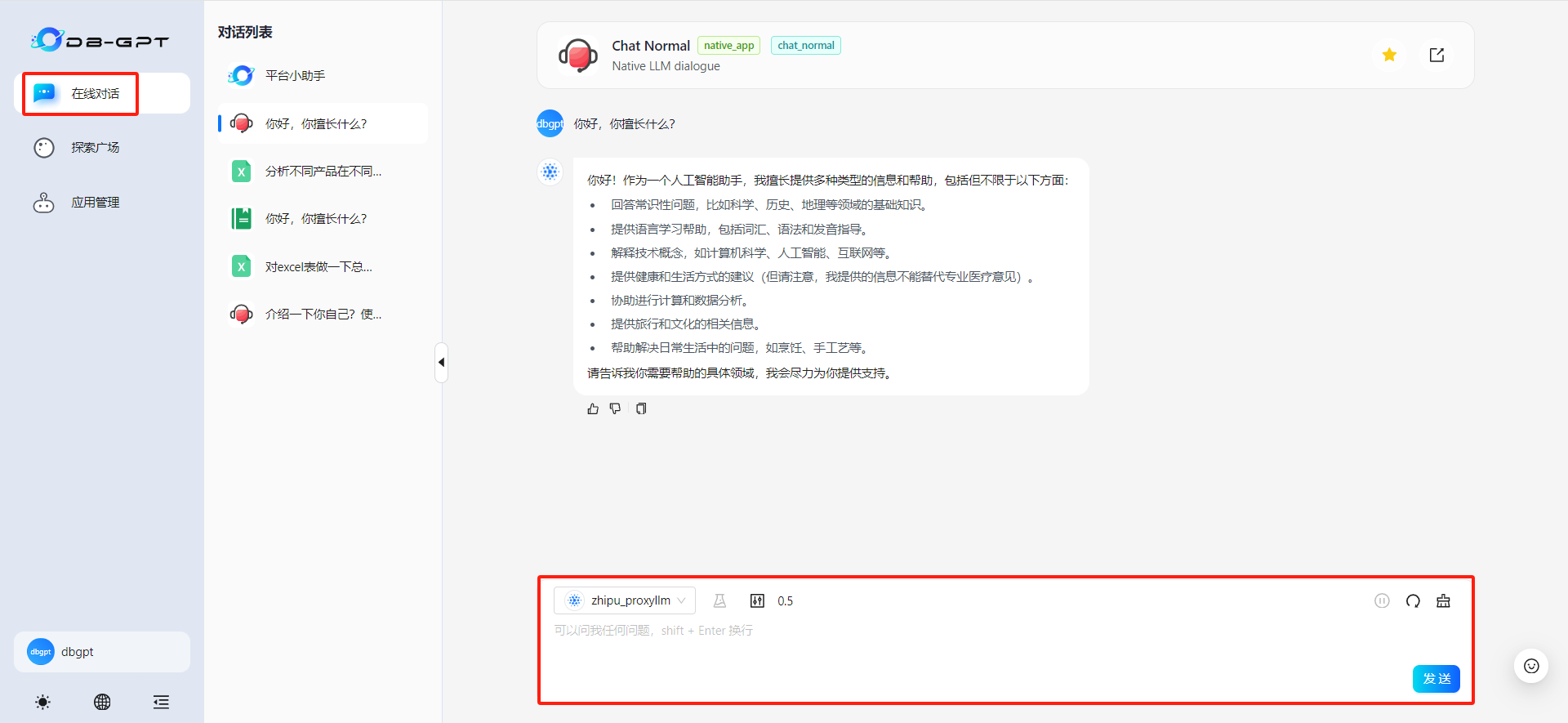
可以在探索广场中找到Chat Normal功能
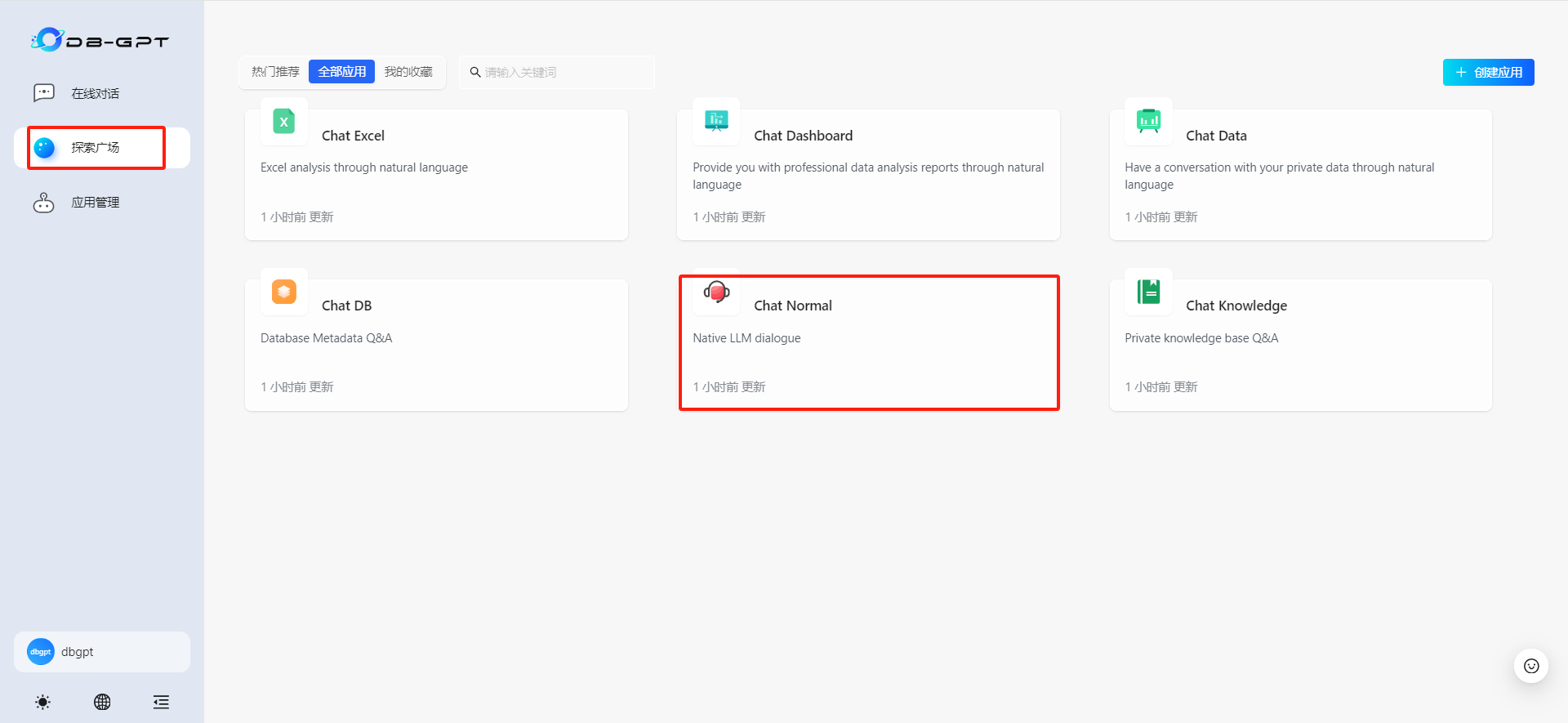
二、知识库问答
Chat Knowledge(知识库对话)借助RAG实现私有知识库问答,用户可以自定义传输企业业务说明文档、专家文档或数据字典等信息,并围绕相关问题进行问答,从而辅助用户快速了解企业业务,或辅助进行业务决策等。
知识库问答的操作主要分为以下几个步骤:
- 创建知识库
- 上传文档知识
- 等待文档切片+向量化
- 开始知识库对话
下面对这几个步骤进行逐一说明
1、创建知识库
在应用管理内切换到知识库tab页,点击创建知识库

填写知识库基础配置:
- 知识库名称:起一个贴切知识库内容的名字
- 存储类型:有Vector Store、Knowledge Graph、Full Text
- 领域类型:目前只有Normal
- 描述:写一下知识库简要的描述
这里的存储类型Vector Store表示向量存储、Knowledge Graph表示知识图谱存储、Full Text表示全文存储。

2、上传文档知识
接着在2 知识库类型中,根据自身的文档类型选择进行文档进行上传。
目前支持的文档类型有:
- 文本:填写原始文本内容
- 网址:读取在线URL的内容、
- 文档:目前支持文档类型有PDF, PowerPoint, Excel, Word, Text, Markdown, Zip, Csv
- 语雀文档:读取语雀(语雀,为每一个人提供优秀的文档和知识库工具 · 语雀)的在线文档内容

这里以上传本地word文档为例子,上传界面如下:

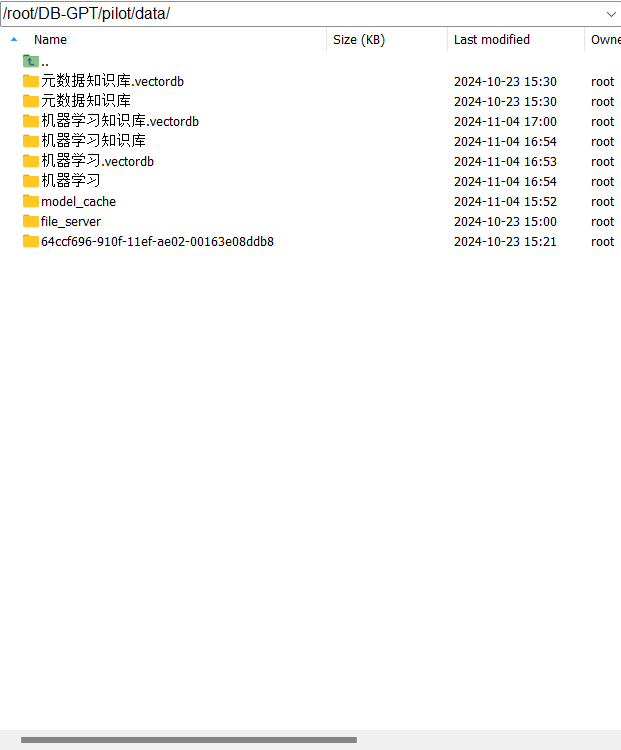
我们上传的文档其实是上传到DB-GPT运行的服务器上(例如公司服务器),本质上 其实还是“本地运行”,并不会存在数据泄露的风险。具体每个知识库文档地址为: /root/autodltmp/DB-GPT/pilot/data
3、等待文档切片+向量化
接下来回到DB-GPT知识库创建页面,可以继续选择文本切分方式,除非特殊情况,推荐选择默认的自动切分方法,然后点击Process即可。
DB-GPT支持下面四种切分方法:
- 自动切片
- chunk size
- paragraph
- separator
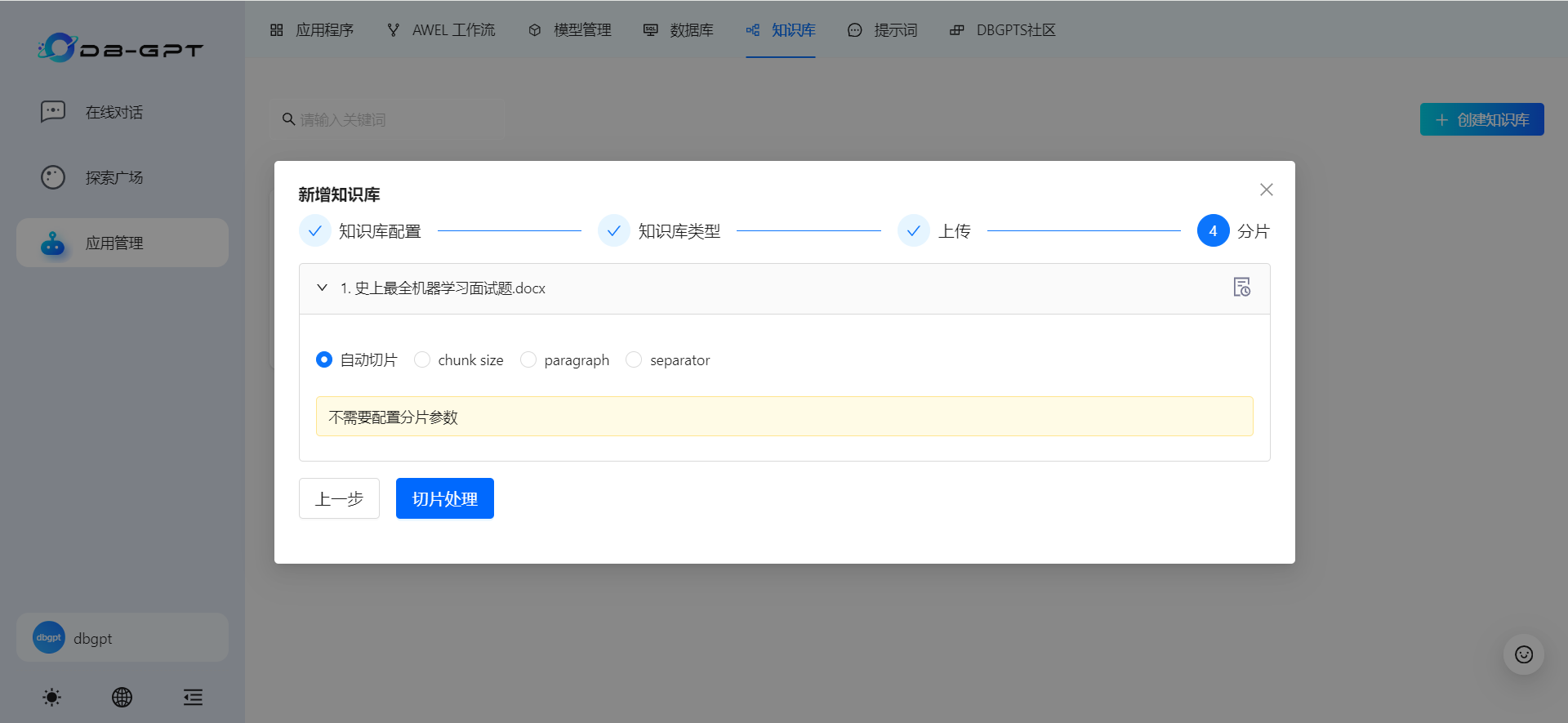
(1)自动切片
不需要设置任何分片参数
(2)chunk size
通过设置chunk_size、chunk_overlap两个参数来控制切分。
chunk_size:对输入文本序列进行切分的最大长度。
chunk_overlap:相邻两个chunk之间的重叠token数量。为了保证文本语义的连贯性,相邻chunk会有一定的重叠。chunk_overlap控制这个重叠区域的大小。

(3)paragraph
通过设置分隔符来区分自然段
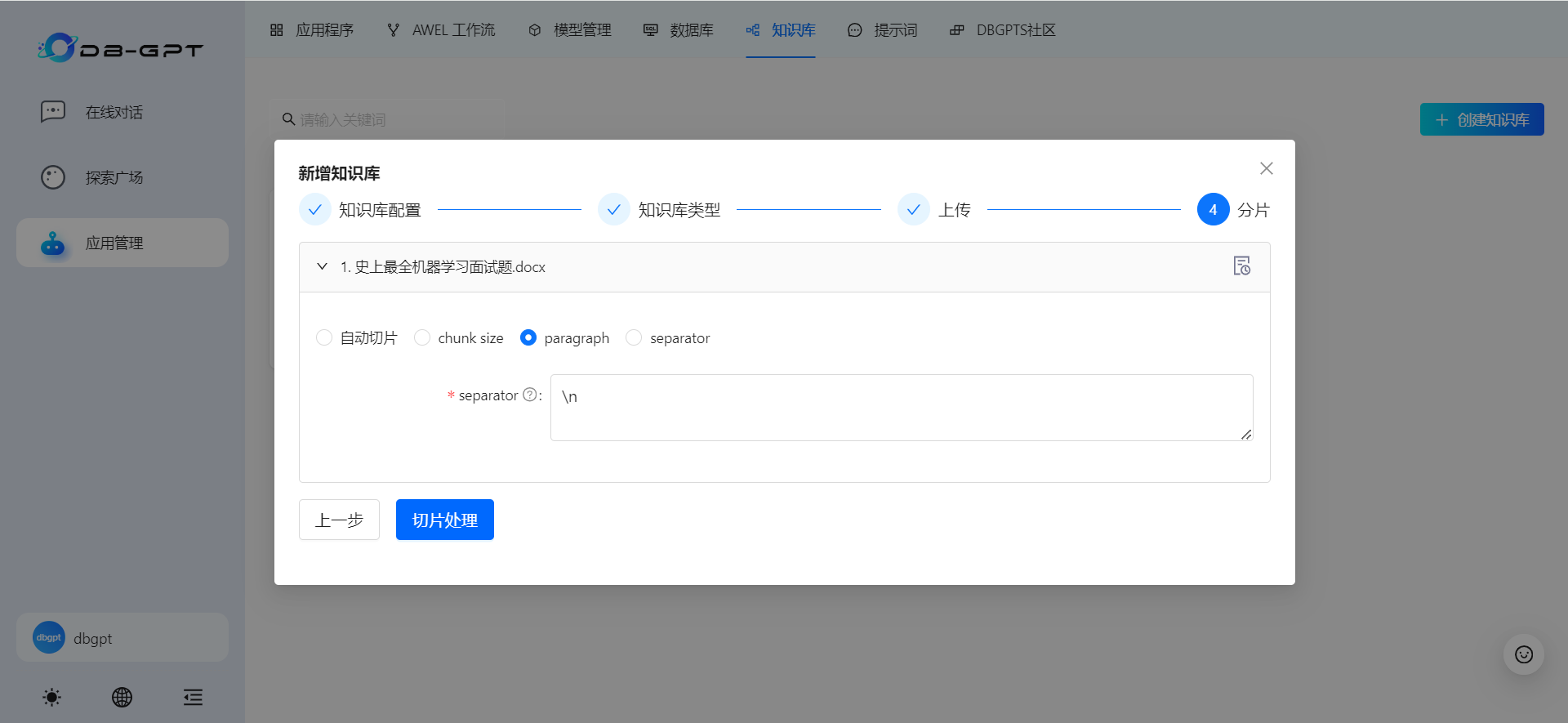

查看文档切分进度


可以查看文档的具体切分结果

4、开始知识库对话
对话会默认载入知识库基本背景,比如当我们输入你好,你擅长什么?时,回答会围绕DBGPT的知识库相关内容进行问答

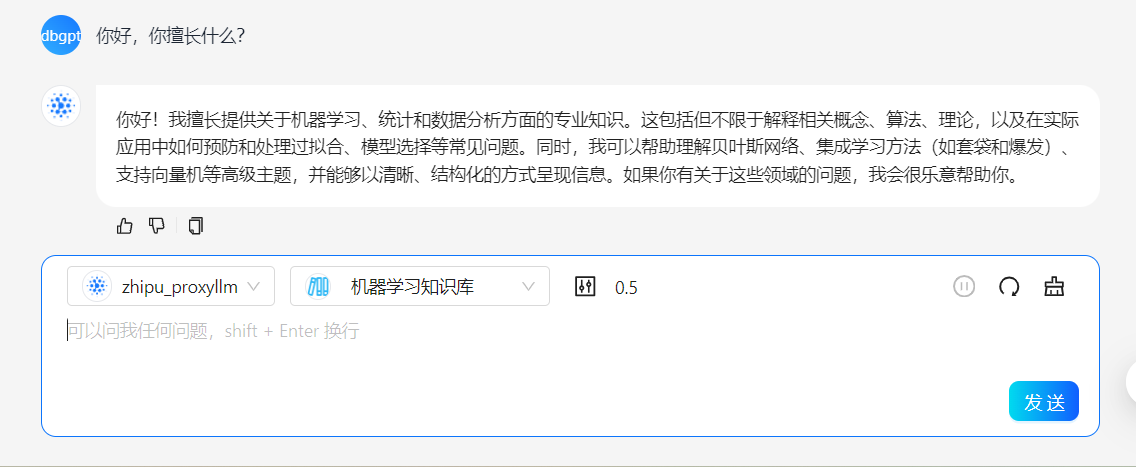
查看DB-GPT后台的处理情况


DB-GPT实现的私有知识库问答流程远比最热门RAG之一的LangChain-CahtChat复杂,在后续解读DB-GPT项目源码的文章会介绍
三、ChatExcel功能
Chat Excel(Excel对话)可以围绕某个Excel数据文件进行快速分析,允许用户上传数据文件并直接对其进行分析。
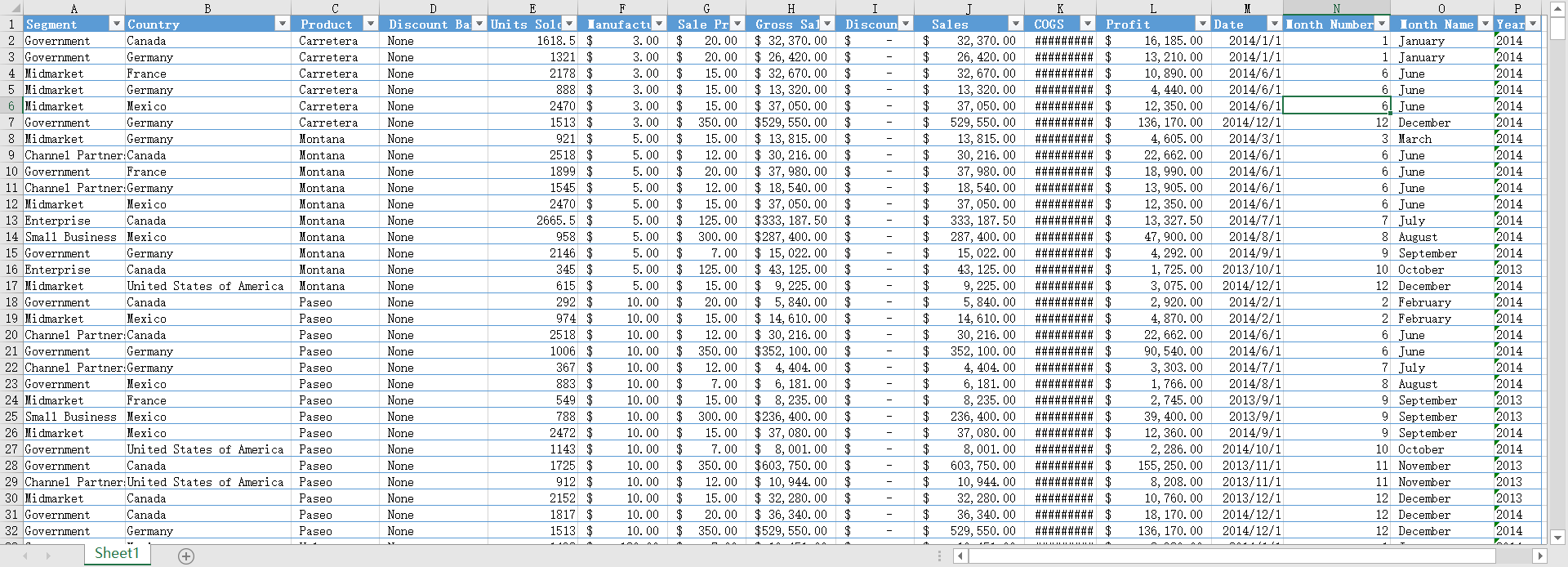
在下载的DB-GPT源码目录DB-GPT\docker\examples\excel下,有一个example.xlsx的示例excel文件。

该数据集数据集包含关于各种细分市场、国家、产品和日期的销售交易信息。包括折扣档次、销售单 位、定价、总销售额、成本、利润,以及交易的月份和年份等详细信息,基本情况如下:
上传了文件之后,发现系统会自动创建一段总结分析。
这里其实是在默认提示词模板作用下,自动对数据文件进行的分析。另外返回的结果是英文,也跟系统的默认提示词有关。后续解读DB-GPT项目源码的文章会介绍如何设置并修改这些提示词模板。

接下来,我们可以进一步提问题继续分析。
例如输入分析不同产品在不同国家的销售趋势,找出一些在某些国家销售势头好的产品。
分析结果如下:

在SQL页会看到DB-GPT也会将分析转换为SQL语句。
从SQL结果来看,很好得理解了上面问题的分析意图。

SELECT
Country,
Product,
SUM(Sales) AS TotalSales
FROM
excel_data
GROUP BY
Country,
Product
ORDER BY
Country,
TotalSales DESC;上传完的excel数据文件数据,也保存在服务器的/root/DB-GPT/pilot/data/文件夹内



















 2203
2203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











