




 本文介绍了如何通过激活函数(sigmoid)将线性回归转换为线性分类,详细解释了逻辑回归中的最大后验估计(MLE)过程,展示了如何将交叉熵优化问题转化为逻辑回归的目标函数。
本文介绍了如何通过激活函数(sigmoid)将线性回归转换为线性分类,详细解释了逻辑回归中的最大后验估计(MLE)过程,展示了如何将交叉熵优化问题转化为逻辑回归的目标函数。
1. 从线性回归到线性分类
我们之前用到的线性回归就是将数据
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)用
W
T
X
W^TX
WTX进行拟合,而现在的线性分类是一个{0,1}或者(0,1)分类问题,线性回归到线性分类是通过激活函数来实现数据的映射的。通过映射(激活函数)完成数据的转换
W
T
X
⟼
{
0
,
1
}
W^TX \longmapsto\{0,1\}
WTX⟼{0,1}
在逻辑回归(logistics regression)中常用的激活函数为:
σ
(
z
)
=
1
1
+
e
−
z
(1)
\sigma(z)=\frac{1}{1+e^{-z}} \tag 1
σ(z)=1+e−z1(1)
注:激活函数有如下性质:
1.
l
i
m
z
→
+
∞
σ
(
z
)
=
1
1.lim _{z\rightarrow+\infty}\sigma(z)=1
1.limz→+∞σ(z)=1
2.
l
i
m
z
→
0
σ
(
z
)
=
1
2
2.lim _{z\rightarrow0}\sigma(z)=\frac{1}{2}
2.limz→0σ(z)=21
3.
l
i
m
z
→
−
∞
σ
(
z
)
=
0
3.lim _{z\rightarrow-\infty}\sigma(z)=0
3.limz→−∞σ(z)=0
这个激活函数叫sigmoid函数:图像如下:
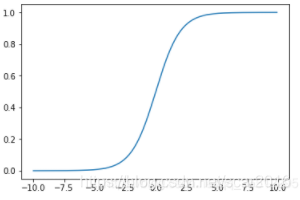
通过激活函数(sigmoid函数)我们可以实现数据
R
⟼
(
0
,
1
)
\mathbb{R}\longmapsto(0,1)
R⟼(0,1),我们将
W
T
X
带
入
s
i
g
m
o
i
d
函
数
可
得
:
W^TX带入sigmoid函数可得:
WTX带入sigmoid函数可得:
p
1
=
p
(
y
=
1
∣
x
)
=
σ
(
w
T
x
)
=
1
1
+
e
−
w
T
x
=
ψ
(
w
,
x
)
;
y
=
1
(2)
p1=p(y=1|x)=\sigma(w^Tx)=\frac{1}{1+e^{-w^Tx}} =\psi(w,x);y=1 \tag 2
p1=p(y=1∣x)=σ(wTx)=1+e−wTx1=ψ(w,x);y=1(2)
p
2
=
p
(
y
=
0
∣
x
)
=
1
−
σ
(
w
T
x
)
=
e
−
w
T
x
1
+
e
−
w
T
x
=
1
−
ψ
(
w
,
x
)
;
y
=
0
(3)
p2=p(y=0|x)=1-\sigma(w^Tx)=\frac{e^{-w^Tx}}{1+e^{-w^Tx}}=1-\psi(w,x) ;y=0 \tag 3
p2=p(y=0∣x)=1−σ(wTx)=1+e−wTxe−wTx=1−ψ(w,x);y=0(3)
我们可以由上式(2),(3)合并后得到如下公式:
p
(
y
∣
x
)
=
p
1
y
⋅
p
2
1
−
y
(4)
p(y|x)=p_1^y\cdot p_2^{1-y} \tag 4
p(y∣x)=p1y⋅p21−y(4)
我们知道了p(y|x)单个的概率密度后,我们可以极大似然估计法求出对应的值:
2.最大后验估计MLE
M L E = w ^ = a r g m a x w ∏ i = 1 n log p ( y i ∣ x i ) = ∏ i = 1 n log p 1 y ⋅ p 2 1 − y MLE=\hat{w}=argmax_{w}\prod_{i=1}^{n}\log{p(y_i|x_i)}=\prod_{i=1}^{n}\log {p_1^y\cdot p_2^{1-y} } MLE=w^=argmaxw∏i=1nlogp(yi∣xi)=∏i=1nlogp1y⋅p21−y
= a r g m a x w ∑ i = 1 n [ y log p 1 + ( 1 − y ) log p 2 ] =argmax_w\sum_{i=1}^{n}[y \log p_1+(1-y) \log{p_2}] =argmaxw∑i=1n[ylogp1+(1−y)logp2]
1 1 + e − w T x = ψ ( w , x ) ; y = 1 \frac{1}{1+e^{-w^Tx}} =\psi(w,x);y=1 1+e−wTx1=ψ(w,x);y=1
e − w T x 1 + e − w T x = 1 − ψ ( w , x ) ; y = 0 \frac{e^{-w^Tx}}{1+e^{-w^Tx}}=1-\psi(w,x) ;y=0 1+e−wTxe−wTx=1−ψ(w,x);y=0;代入可得如下:
M L E = a r g m a x w ∑ i = 1 n [ y log ψ ( x , w ) + ( 1 − y ) log ( 1 − ψ ( x , w ) ] (5) MLE=argmax_w{\sum_{i=1}^{n}}[y \log{\psi(x,w)}+(1-y)\log(1-\psi(x,w)] \tag 5 MLE=argmaxwi=1∑n[ylogψ(x,w)+(1−y)log(1−ψ(x,w)](5)
由上式可以看出: y log ψ ( x , w ) + ( 1 − y ) log ( 1 − ψ ( x , w ) ) 就 是 一 个 交 叉 熵 的 表 达 形 式 ( C r o s s _ E n t r o p y ) y \log{\psi(x,w)}+(1-y)\log(1-\psi(x,w))就是一个交叉熵的表达形式(Cross\_Entropy) ylogψ(x,w)+(1−y)log(1−ψ(x,w))就是一个交叉熵的表达形式(Cross_Entropy)以上我们成功的找到了目标函数的形式,可以描述为:
M L E ( m a x ) = L o s s _ F u n c t i o n m i n c r o s s _ e n t r o p y ) (6) MLE_{(max)}=Loss\_Function_{min}cross\_entropy) \tag 6 MLE(max)=Loss_Functionmincross_entropy)(6)
综上所述,逻辑回归的优化问题可以转换成一个Cross Entropy的优化问题。

















 1083
1083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









