



方案调研
我一开始的想法是,编写一个sh脚本,利用linux的curl命令来探测,每分钟执行一次,这个脚本也简单,如下所示:
-
-s: 静默模式,不显示进度信息。 -
-o /dev/null: 忽略返回的内容,只关心状态码。 -
-w "%{http_code}": 打印 HTTP 状态码。
bash
代码解读
复制代码
#!/bin/bash curl -s -o /dev/null -w "%{http_code}" http://192.168.6.131:8080/chat-api >> /var/log/chat_api_http_status_survey.log
随后,执行crontab -e命令设置cron定时任务,每分钟执行一次这个脚本。
bash
代码解读
复制代码
* * * * * /path/to/check_http_service.sh
探测任务完成了,但是,如何让Prometheus 监听到,并通过Alertmanager 来发送通知呢?找了一圈,没找到开箱即用的方案。需要自己整一个http服务器,把sh脚本返回的内容暴露出来,再通过Prometheus来抓取这个服务返回的内容。
这样做就太麻烦了,必要性不是很大。
blackbox_exporter监控
自定义sh脚本的路走不通后,我将思路转变到了Prometheus本身,发现它有一个Blackbox Exporter扩展,可以监控外部的 HTTP 服务。只需要安装相关的软件包、编写配置文件即可实现监控,给大家看下我最终实现的效果。
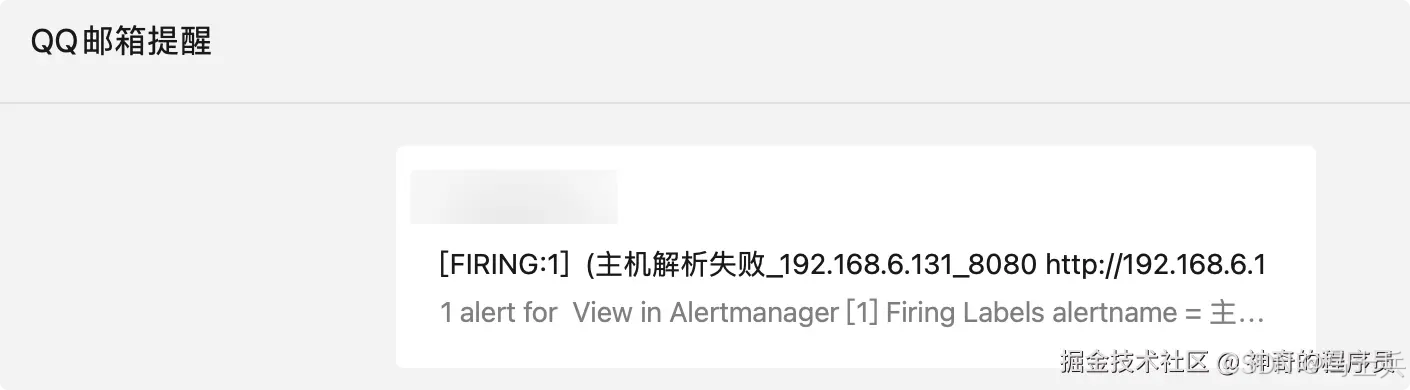
实现过程
方案有了,接下来,我们看下具体的实现过程。
安装扩展包
通过ssh登陆到pve服务器,依次执行下述命令,将软件包下载到用户目录下。
bash
代码解读
复制代码
# 下载 wget https://github.com/prometheus/alertmanager/releases/download/vX.Y.Z/alertmanager-X.Y.Z.linux-amd64.tar.gz # 解压 tar -xvzf alertmanager-X.Y.Z.linux-amd64.tar.gz
使用你喜欢的编辑器(此处使用nvim)来创建服务配置文件,便于管理服务的启动状态。
bash
代码解读
复制代码
nvim /etc/systemd/system/blackbox_exporter.service
添加下述内容:
ExecStart为blackbox_exporter服务的启动文件WorkingDirectory为blackbox_exporter的存放路径
bahs
代码解读
复制代码
[Unit] Description=Blackbox Exporter After=network.target [Service] Type=simple ExecStart=/root/blackbox_exporter-0.21.0.linux-amd64/blackbox_exporter Restart=always User=root Group=root WorkingDirectory=/root/blackbox_exporter-0.21.0.linux-amd64 [Install] WantedBy=multi-user.target
保存后,执行systemctl daemon-reload来重载服务。
依次执行下述命令来启动服务,并将其添加至开机自启名单中。
bahs
代码解读
复制代码
systemctl start blackbox_exporter systemctl enable blackbox_exporter
查看运行状态与日志
服务启动后,我们执行systemctl status blackbox_exporter命令,如果正常运行,你将看到如下所示的内容:
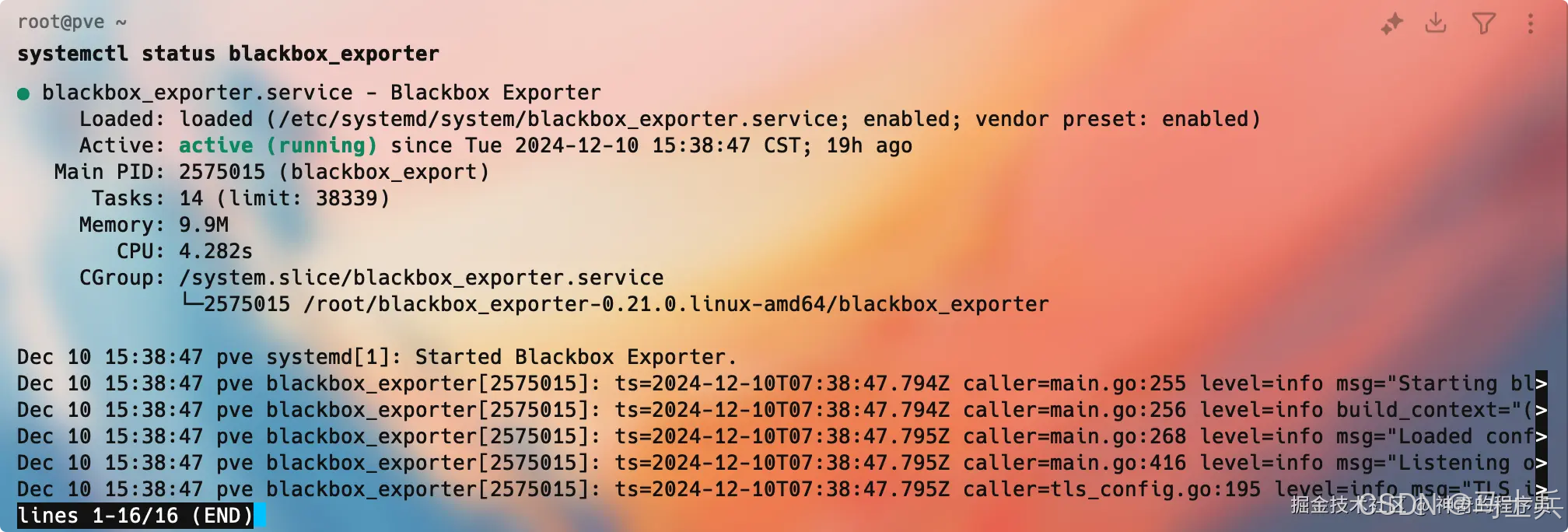
 通过
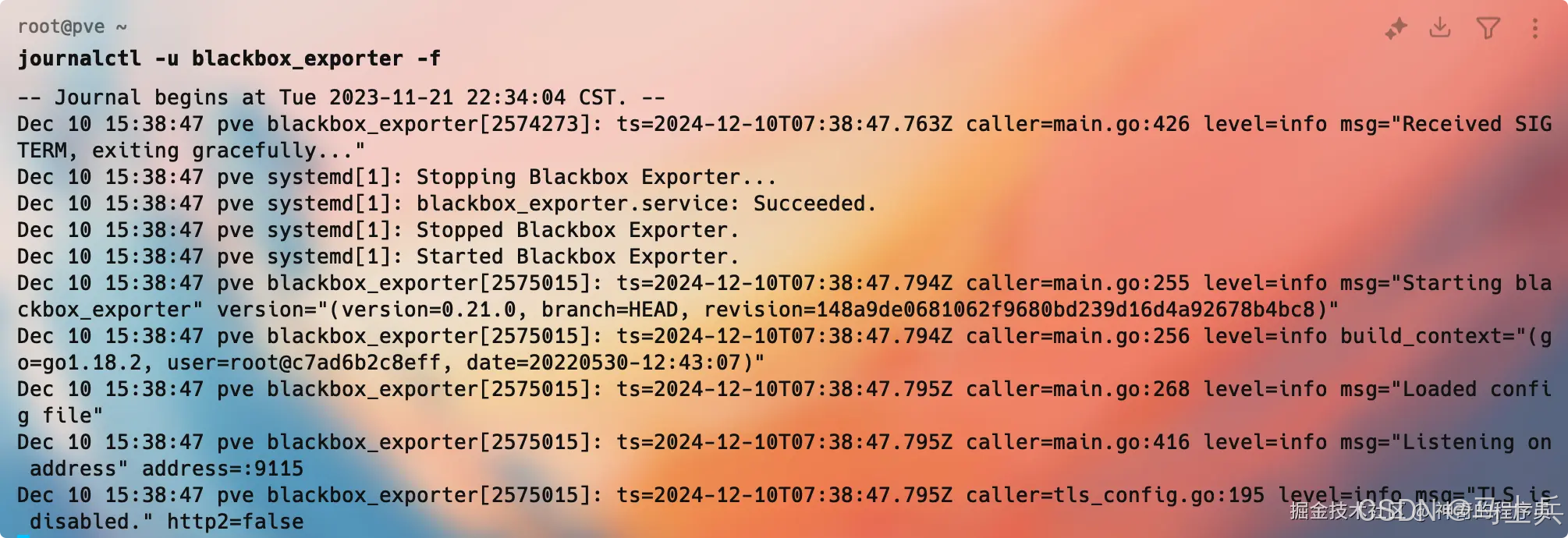
通过journalctl -u blackbox_exporter -f命令来查看运行日志。
测试能否正常工作
执行下述命令,将target换成你要检测的内网服务地址。
bash
代码解读
复制代码
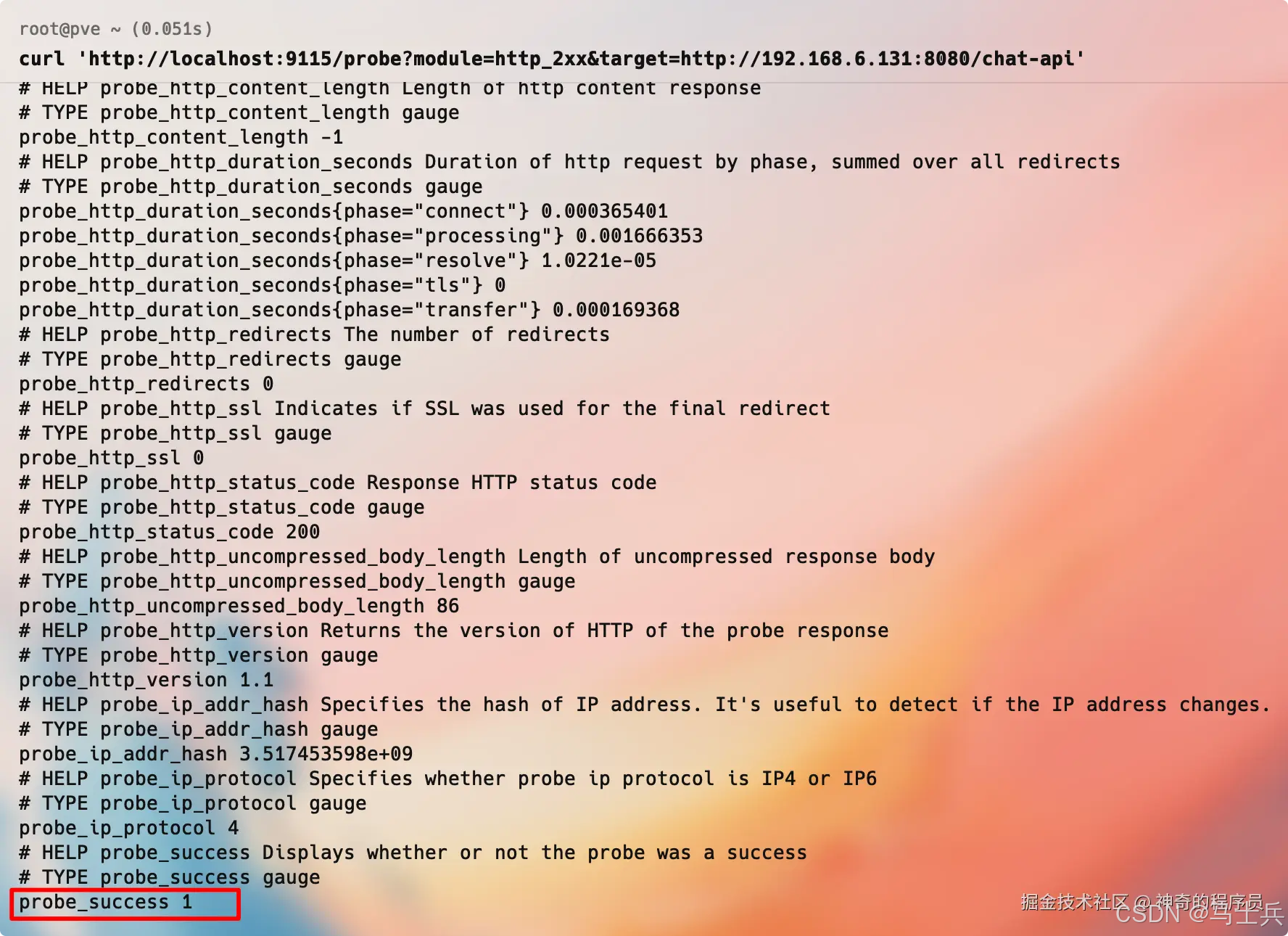
curl 'http://localhost:9115/probe?module=http_2xx&target=http://192.168.6.131:8080/chat-api'
如果你的服务正常运行,你将看到如下所示的输出。
probe_success的值为1,表示服务正常运行。为0,表示服务异常。

配置prometheus
用你喜欢的编辑器,打开prometheus.yml的配置文件。
bash
代码解读
复制代码
nvim /etc/prometheus/prometheus.yml
添加下述内容
- targets 替换为你要监听的内网服务地址
- replacement 替换为你的blackbox_exporter服务的部署地址,默认端口是9115
- scrape_interval 为采集间隔
bash
代码解读
复制代码
# blackbox_ping 监听内网服务是否正常 - job_name: 'blackbox_ping' metrics_path: /probe params: module: [http_2xx] # 使用 HTTP 模块 static_configs: - targets: - http://192.168.6.131:8080/chat-api # 使用完整的 URL relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: localhost:9115 # blackbox_exporter 的地址和端口 scrape_interval: 1m # 每分钟采集一次
配置Alertmanager
用你喜欢的编辑器,打开Alertmanager的配置文件。
bash
代码解读
复制代码
nvim /etc/prometheus/alert.rules.yml
添加下述内容
- alert 为邮件标题
- expr 为graph的表达式,将instance和job的值替换为上一步中填写的
targets和job_name的值 - summary和description为你要通知的内容
bash
代码解读
复制代码
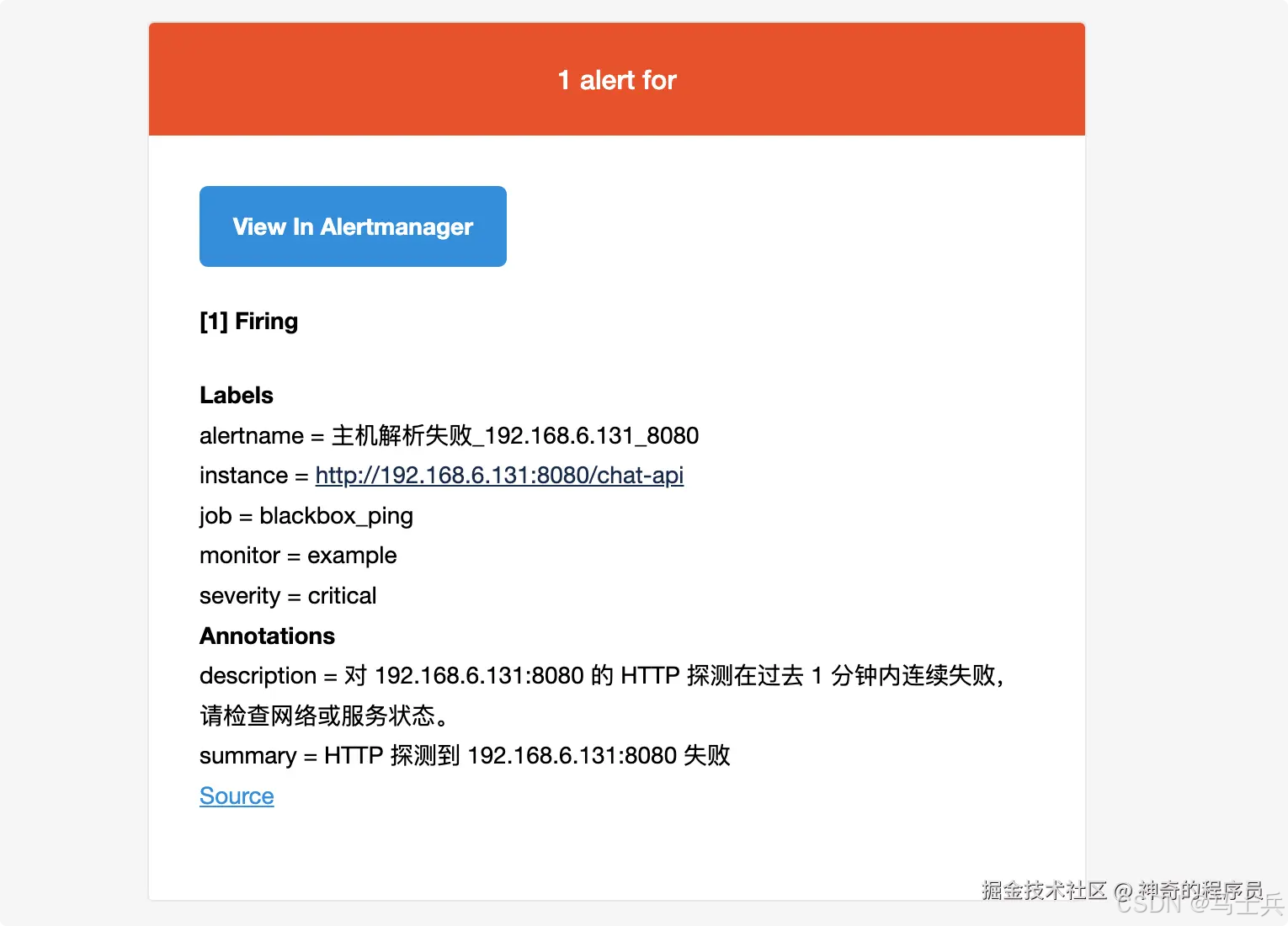
- alert: "主机解析失败_192.168.6.131_8080" expr: probe_success{instance="http://192.168.6.131:8080/chat-api",job="blackbox_ping"} == 0 for: 1m labels: severity: critical annotations: summary: "HTTP 探测到 192.168.6.131:8080 失败" description: "对 192.168.6.131:8080 的 HTTP 探测在过去 1 分钟内连续失败,请检查网络或服务状态。"
重启并验证所有服务
依次执行下述命令
bash
代码解读
复制代码
sudo systemctl restart blackbox_exporter sudo systemctl restart prometheus sudo systemctl restart alertmanager sudo systemctl status blackbox_exporter sudo systemctl status prometheus sudo systemctl status alertmanager
如果一切正常的话,打开prometheus的web界面,你将看到如下内容:

此时,将你的内网服务关闭,1分钟后,你将成功收到告警邮件。


















 1533
1533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









