




 博主通过Python将大量HTML教程文档分类、转换为PDF并合并,详细介绍了环境配置、HTML到PDF转换以及PDF合并的过程,针对遇到的问题提供了解决方案。
博主通过Python将大量HTML教程文档分类、转换为PDF并合并,详细介绍了环境配置、HTML到PDF转换以及PDF合并的过程,针对遇到的问题提供了解决方案。
版权声明:本文为博主原创文章,转载 请注明出处:https://blog.youkuaiyun.com/sc2079/article/details/106246106
-写在前面
最近想提升自己的PPT制作能力,便下载了某PPT教程类微信公共号的html文档,非常多,感觉一篇篇挨着看效率不高。因此,有了分类整理并制作PDF文档的想法。

- 环境配置安装
运行环境:Python3.6、Spyder;
依赖模块:pdfkit、PyPDF2等。
注:pdfkit的安装可以参考: python将html转化为pdf
- 开始工作
1.读取目录
首先,要有待整理文档的分类目录,示例如下:

我采用字典存储目录。
#读取txt文档目录
def read_txt(file):
contents={}
with open (file,'r') as f:
for line in f.readlines():
if line!='\n':
line=line.replace('\n','')
if re.search('^[0-9]+\.',line):
content=[]
contents[line]=content
continue
else:
line=line.replace('? ','')
content.append(line)
可以根据自己的目录特点加以修改。根据目录整理文档
2. 根据目录将html文档分类复制到指定位置
def copy_file(file_from_path,file_to_path,contents):
if os.path.isdir(file_from_path):
old_files=os.listdir(file_from_path)
tt=findStr(old_files[0],'_',2)+1
_old_files=[]
for old_file in old_files:
_old_file=old_file[tt:]
_old_files.append(_old_file)
#print(_old_files)
for title,content in contents.items():
#print(title)
_file_to_path=file_to_path+'//'+title
#print(_file_to_path)
if not os.path.isdir(_file_to_path):
os.mkdir(_file_to_path)
for i in content:
ii=i+'.html'
if os.path.exists(_file_to_path+'//'+ii): #防止重复复制
continue
try:
p=_old_files.index(i) #位置
shutil.copyfile(file_from_path+'//'+old_files[p],_file_to_path+'//'+ii)
#print(i+' 复制成功')
except:
pass
print(i+' 复制失败')
值得说明的是由于我的html文档格式为:公众号名称_日期_文档名称,复制时需要去掉前面部分,具体来说要查找文档名称字符串中“_”第2次出现位置。其程序实现如下:
#查找字符串中第n次出现位置
def findStr(string, subStr, findCnt):
listStr = string.split(subStr,findCnt)
if len(listStr) <= findCnt:
return -1
return len(string)-len(listStr[-1])-len(subStr)
3.将html转换成pdf
这里核心使用的是
pdfkit.from_file(src_file,dist_file)
需要说明的是,即使我的环境变量配置好之后,也会出现以下报错:
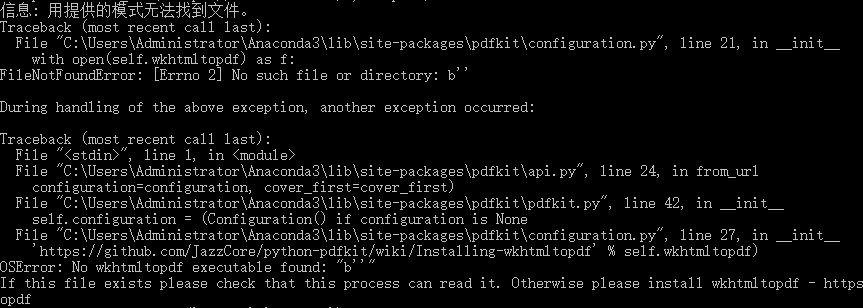
可能原因:环境变量还没起作用,可能需重启电脑?
于是,我用的是另一种方法:
config = pdfkit.configuration(wkhtmltopdf=r"C:\Users\Administrator\Downloads\Compressed\wkhtmltox\bin\wkhtmltopdf.exe")
pdfkit.from_file(src_file,dist_file,configuration=config)
具体代码如下:
def html_2_pdf(html_path,pdf_path):
titles=os.listdir(html_path)
for title in titles:
if not os.path.isdir(html_path+'//'+title):
continue
if not os.path.isdir(pdf_path+'//'+title):
os.mkdir(pdf_path+'//'+title)
htmls=os.listdir(html_path+'//'+title)
for html in htmls:
filename,extension=os.path.splitext(html)
if not os.path.exists(pdf_path+'//'+title+'//'+filename+'.pdf'):#防止重复转换
print('正在创建 '+filename+' PDF文档')
pdfkit.from_file(html_path+'//'+title+'//'+html,pdf_path+'//'+title+'//'+filename+'.pdf', configuration=config)
4.合并pdf
当前文档已经归类到不同的文件夹下,接下来就是进行合并pdf文档操作。具体参考的是 使用python合并pdf文件带书签
'''
本脚本用来合并pdf文件,支持带一级子目录的
每章内容分别放在不同的目录下,目录名为章节名
最终生成的pdf,按章节名生成书签
'''
import os, sys, codecs
from PyPDF2 import PdfFileReader, PdfFileWriter, PdfFileMerger
import glob
def getFileName(filepath):
'''
获取当前目录下的所有pdf文件
'''
file_list = glob.glob(filepath+"/*.pdf")
# 默认安装字典序排序,也可以安装自定义的方式排序
# file_list.sort()
return file_list
def get_dirs(filepath='', dirlist_out=[], dirpathlist_out=[]):
# 遍历filepath下的所有目录
for dir in os.listdir(filepath):
dirpathlist_out.append(filepath + '\\' + dir)
return dirpathlist_out
def merge_childdir_files(path):
'''
每个子目录下合并生成一个pdf
'''
dirpathlist = get_dirs(path)
if len(dirpathlist) == 0:
print("当前目录不存在子目录")
sys.exit()
for dir in dirpathlist:
mergefiles(dir, dir)
def mergefiles(path, output_filename, import_bookmarks=False):
# 遍历目录下的所有pdf将其合并输出到一个pdf文件中,输出的pdf文件默认带书签,书签名为之前的文件名
# 默认情况下原始文件的书签不会导入,使用import_bookmarks=True可以将原文件所带的书签也导入到输出的pdf文件中
merger = PdfFileMerger()
filelist = getFileName(path)
if len(filelist) == 0:
print("当前目录及子目录下不存在pdf文件")
sys.exit()
for filename in filelist:
f = codecs.open(filename, 'rb')
file_rd = PdfFileReader(f)
short_filename = os.path.basename(os.path.splitext(filename)[0])
if file_rd.isEncrypted == True:
print('不支持的加密文件:%s'%(filename))
continue
merger.append(file_rd, bookmark=short_filename, import_bookmarks=import_bookmarks)
print('合并文件:%s'%(filename))
f.close()
# out_filename = os.path.join(os.path.abspath(path), output_filename)
merger.write(output_filename + ".pdf")
print('合并后的输出文件:%s'%(output_filename))
merger.close()
if __name__ == "__main__":
# 每个章节一个子目录,先分别合并每个子目录文件为一个pdf,然后再将这些pdf合并为一个大的pdf,这样做目的是想生成每个章节的书签
# 1.指定目录
# 原始pdf所在目录
path = r"D:\学习资源\微信公共号\xx公共号\分类pdf"
#_path = r"D:\学习资源\微信公共号\xx公共号\cs"
# 输出pdf路径和文件名
output_filename = r"D:\学习资源\微信公共号\xx公共号\分类pdf\PPT教程"
# 2.生成子目录的pdf
merge_childdir_files(path)
# 3.子目录pdf合并为总的pdf
mergefiles(path, output_filename,True)
合并速度挺快的,过程如下:

不过,有很大不足:这里我要求的是有二级目录,但是这里第二次合并pdf时会去掉原先已生成的目录!
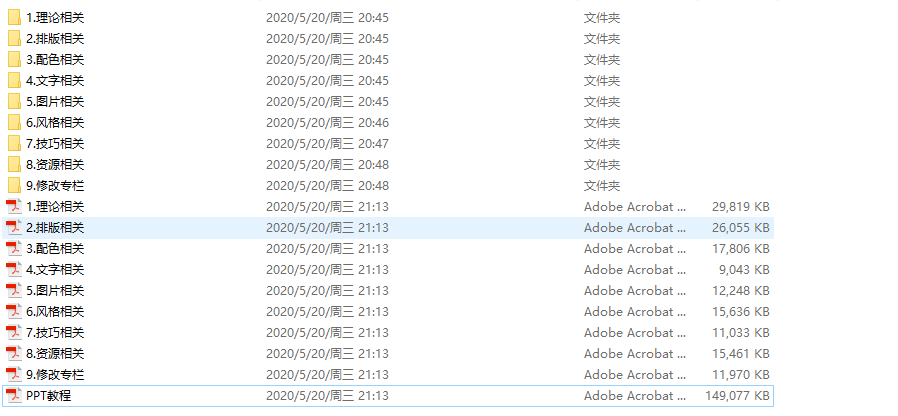
5.结果展示
-其它参考
1.Pdfkit OSError: No wkhtmltopdf executable found
2.python读写、创建文件、文件夹等等


















 379
379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









