




 MixMatch是一种半监督学习算法,利用Mixup数据增强技术和温度参数T对无标签数据进行处理,生成猜测标签。它在有标签和无标签数据上执行多次增强和Mixup操作,然后结合交叉熵和L2损失函数来训练模型。
MixMatch是一种半监督学习算法,利用Mixup数据增强技术和温度参数T对无标签数据进行处理,生成猜测标签。它在有标签和无标签数据上执行多次增强和Mixup操作,然后结合交叉熵和L2损失函数来训练模型。
算法的整个流程还是比较清晰简单的,主要使用了Mixup这一数据增强,混合了标签数据和无标签数据。
流程步骤如下:
一、记batch size为B,标签样本为X,无标签样本为U,temperature为T,无标签样本数据增强的次数为K,在实验中,K设为2,这里的数据增强就是指普通的数据增强而不是mixup。
二、
对一个batch中的X进行一次数据增强,得到
对一个batch中的U进行K次数据增强,得到
三、对所有增强的无标签数据进行预测,并对它们的预测求平均,再通过temperature进行sharpen,得到猜测标签
。

四、
得到增强的有标签数据和它们对应的标签;
得到增强的无标签数据和它们对应的猜测标签。
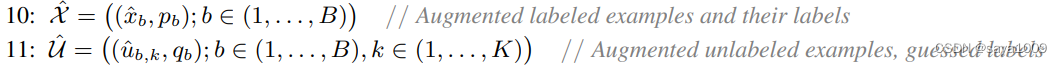
五、将有标签数据和无标签数据cat
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3997
3997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









