






欢迎来到 s a y − f a l l 的文章 欢迎来到say-fall的文章 欢迎来到say−fall的文章

前言:
在计算机的学习中,我们老是听到内存上有栈区、堆区、静态区等等,那么这个内存上的栈究竟是什么呢?或者说栈这个东西有什么特点?为什么又听说栈也是一种数据结构呢?本片文章就围绕栈的内部结构以及内存栈区与数据结构栈的关系展开叙述,解答这些疑惑
文章目录
正文:
一、内存中的栈区
内存中的栈区(Stack Memory)是程序运行时内存空间的核心分区之一,由操作系统/编译器自动管理,核心特点是“先进后出(LIFO)”,专门用于处理函数调用、局部变量等临时数据,是程序执行的基础支撑。
先进后出作为栈最基本也是最重要的性质,我们在稍后的数据结构栈内容仔细讲解,现在可以稍微记一下
1、定位
栈区是线程专属的内存分区(每个线程都有独立的栈),大小通常是固定的(默认几MB,可通过编译器/系统配置调整),用于存储函数调用过程中的临时数据,随函数的“调用”自动分配、“返回”自动释放,无需开发者手动管理。
不了解内存中分区的话可以配合下图食用:
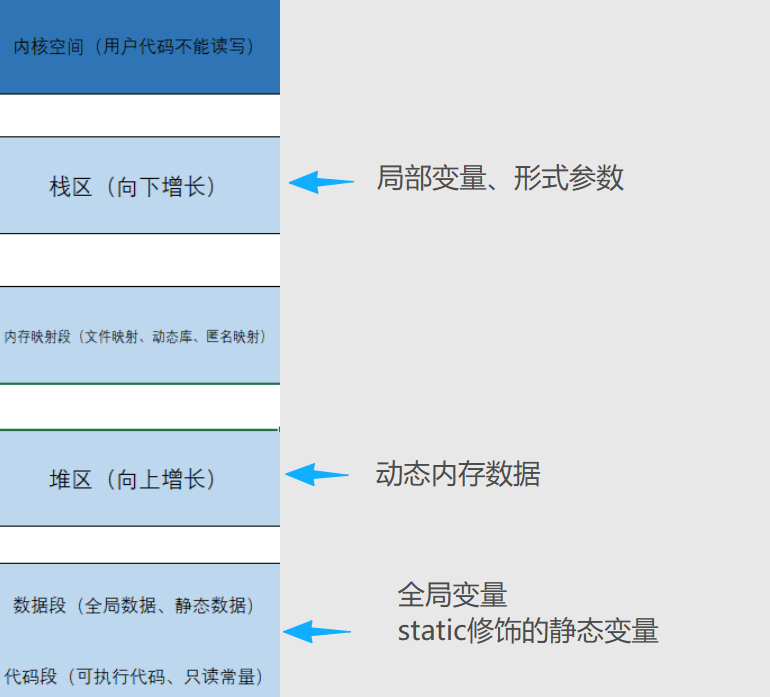
2、存储的内容
栈区的核心存储对象是栈帧(Stack Frame)——每个函数调用时,系统会在栈区分配一块“栈帧”,存储该函数的:
- 函数参数:调用函数时传入的参数(如
func(10, 20)中的1020); - 局部变量:函数内定义的临时变量(如
int a = 5;中的a); - 返回地址:函数执行完后要回到的代码位置(确保函数返回后程序能继续执行);
- 寄存器上下文:调用函数前的寄存器状态(函数执行完后恢复,保证程序状态不被破坏)。
3、工作机制:先进后出(LIFO)
栈区的操作只有“压栈(Push)”和“弹栈(Pop)”:
- 入栈(压栈):函数调用时,系统在栈的“顶端”分配新栈帧,栈顶指针(Stack Pointer)向栈底方向移动(栈增长方向通常是“从高地址到低地址”);
- 出栈(弹栈):函数返回时,当前栈帧被释放,栈顶指针向栈顶方向移动,原栈帧的数据会被后续压栈操作覆盖(无需手动释放)。
举个直观例子(函数调用过程):
// 函数A调用函数B
void B(int x) {
int y = x + 1; // y是B的局部变量,存在B的栈帧中
}
void A() {
int a = 10; // a是A的局部变量,存在A的栈帧中
B(a); // 调用B,分配B的栈帧(入栈)
} // A返回,A的栈帧被释放(出栈)
执行流程中栈的变化:
- 调用
A()→ 压入A的栈帧(存储a=10、返回地址等); A调用B(a)→ 压入B的栈帧(存储参数x=10、局部变量y=11等);B执行完返回 → 弹出B的栈帧;A执行完返回 → 弹出A的栈帧;
最终栈回到初始状态。
4、核心特点
- 自动管理:分配/释放由系统自动完成,无内存泄漏风险(但可能出现栈溢出);
- 速度极快:栈的操作是通过移动栈顶指针实现的,效率远高于堆区的内存分配;
- 大小有限:默认栈大小较小(如Windows默认1MB、Linux默认8MB),存储大量数据会导致栈溢出(Stack Overflow);
- 线程独立:每个线程有自己的栈区,线程间栈数据不共享。
二、数据结构的栈
数据结构的栈(Stack)是一种遵循“先进后出(LIFO,Last In First Out)”规则的线性逻辑结构——核心特点是“只允许在一端(栈顶)进行数据的插入(入栈)和删除(出栈)操作”,另一端(栈底)固定不可直接操作。
也就是说栈相当于是只有一个开口的直筒,所谓的 LIFO 特性就是先放进去的话在下面,导致后放进去的东西先拿出来的一种特性。
1、核心定义与核心操作
1.1 核心概念
- 栈顶(Top):允许操作的一端,用一个“栈顶标记”(比如之前代码中的
top变量)记录当前栈顶位置; - 栈底(Bottom):固定的一端,数据一旦压入栈底,只有上方所有元素都出栈后才能访问;
- 空栈:栈中没有任何元素时的初始状态(比如
top=0或top=-1,取决于实现约定)。
1.2 必选核心操作(所有栈都具备)
| 操作名 | 功能描述 | 时间复杂度 |
|---|---|---|
| Push(入栈) | 在栈顶插入一个新元素,栈顶标记更新 | O(1) |
| Pop(出栈) | 删除栈顶元素(不返回值,或返回被删元素),栈顶标记更新 | O(1) |
| Top(取栈顶) | 读取栈顶元素,但不删除(栈状态不变) | O(1) |
| Empty(判空) | 判断栈是否为空(空返回true,非空返回false) | O(1) |
1.3 可选辅助操作
Size(求大小):返回栈中有效元素的个数;Destroy(销毁):释放栈占用的内存(动态实现时必需,避免内存泄漏)。
2、底层实现方式(物理载体)
数据结构的栈是“逻辑规则”,需要借助具体的物理存储载体实现,常见两种方式:
2.1 动态数组实现(最常用)
- 用动态数组指针(比如之前代码中的
ptr)作为存储容器,top记录栈顶位置,capacity记录数组容量; - 优点:访问栈顶元素速度快(直接通过索引
ptr[top-1]访问),实现简单; - 缺点:扩容时需要重新开辟内存、拷贝数据(但扩容频率低,平均时间复杂度仍为O(1))。
2.2 链表实现(链式栈)
- 用单链表作为存储容器,链表的表头作为“栈顶”(插入/删除无需遍历);
- 优点:无需提前分配容量,没有扩容问题;
- 缺点:需要额外存储链表节点的指针域,空间开销略大,访问速度比数组实现稍慢。
2.3 动态数组实现
因为动态数组实现的栈其实是类似一个简单的线性表,这里就直接在这块插入代码供大家学习:
typedef int STDatatype;
typedef struct Stack
{
STDatatype* ptr;
int top;
int capacity;
}Stack;
//初始化与销毁
void StackInit(Stack* ps);
void StackDestroy(Stack* ps);
//入栈与出栈
void StackPush(Stack* ps,STDatatype x);
void StackPop(Stack* ps);
//查看顶端元素
STDatatype StackTop(Stack* ps);
//判空
bool StackEmpty(Stack* ps);
//有效元素个数
int StackSize(Stack* ps);
//初始化与销毁
void StackInit(Stack* ps)
{
assert(ps);
ps->ptr = NULL;
ps->capacity = 0;
//指向栈顶的下一个位置
ps->top = 0;
}
void StackDestroy(Stack* ps)
{
assert(ps);
free(ps->ptr);
ps->ptr = NULL;
ps->capacity = ps->top = 0;
}
//入栈与出栈
void StackPush(Stack* ps, STDatatype x)
{
assert(ps);
if (ps->top == ps->capacity)
{
int newcapacity = ps->capacity == 0 ? 4 : (2 * ps->capacity);
STDatatype* tmp = (STDatatype*)realloc(ps->ptr,newcapacity * sizeof(STDatatype));
if (tmp == NULL)
{
perror("realloc");
return;
}
ps->ptr = tmp;
ps->capacity = newcapacity;
}
ps->ptr[ps->top] = x;
ps->top++;
}
void StackPop(Stack* ps)
{
assert(ps);
assert(ps->top > 0);
ps->top-- ;
}
//查看顶端元素
STDatatype StackTop(Stack* ps)
{
assert(ps);
assert(ps->top > 0);
return ps->ptr[ps->top - 1];
}
//判空
bool StackEmpty(Stack* ps)
{
assert(ps);
return ps->top == 0;
}
//有效元素个数
int StackSize(Stack* ps)
{
assert(ps);
return ps->top;
}
3、典型应用场景
正因为“先进后出”的特性,栈在编程和算法中应用极广:
- 函数调用栈:编程语言的函数调用机制本质就是栈——调用函数时“压栈”(保存当前上下文、返回地址),函数返回时“弹栈”(恢复上下文);
- 表达式求值:比如计算后缀表达式(逆波兰表达式)、处理括号匹配(判断
()[]{}是否成对); - 回溯算法:比如迷宫求解、全排列问题(走错路时“回溯”到上一步,栈保存走过的路径);
- 浏览器历史记录:浏览器的“后退”功能,本质是把访问过的页面压栈,后退时出栈;
- 编辑器撤销操作:编辑器的“Ctrl+Z”撤销,把每一步操作压栈,撤销时弹出最后一步操作。
三、数据结构栈与“内存栈区”的本质区别
- 数据结构的栈:逻辑规则(先进后出),可借助“内存堆区”“内存栈区”等任意物理内存实现;
- 内存的栈区:物理分区(操作系统分配),天生支持先进后出,是数据结构栈的“物理灵感来源”。
- 本节完…

















 1668
1668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









