




前言
很多小伙伴还在为弄不懂深度学习整个流程而烦恼,比如图像数据如何读入?数据在网络之间如何传递?如何前向计算?如何反向计算?如何更新权重?如何预测输出?博主利用每天晚上的时间,历经两个星期,为大家带来这款为理解深度学习而生的学习框架,命名为LazyNet,为什么呢?因为此框架真的很简单,动动手指头就能明白整个深度学习流程了!
LazyNet优势
- 不依赖GPU,任何CPU均可
- 除OpenBLAS、OpenCV外,不依赖任何第三方
- 纯C++代码
- 代码简介明了,数据流简单易懂
- 相关原理在代码里面做了详细说明
LazyNet传送门
- 传送门(若对您有帮助,欢迎star和fork)
LazyNet简介
一、支持系统
- Windows7/10(强烈推荐,因为可以直观调试)
- Linux(可自己写简易makefile)
- Mac(暂未尝试)
二、环境搭建
- CPU
- VS2015(Windows强烈推荐)
三、示例数据
- mnist400(train200-0,train200-1,test20-0,test20-1)
四、示例网络
| Layers | channel | Kernel_size | stride | pad | Input_size | Output_size |
| Conv1 | 16 | 3 | 1 | 0 | 28x28 | 26x26 |
| Relu1 | 16 | - | - | - | 26x26 | 26x26 |
| Maxpool1 | 16 | 2 | 2 | 0 | 26x26 | 13x13 |
| Conv2 | 32 | 3 | 1 | 0 | 13x13 | 11x11 |
| Relu2 | 32 | - | - | - | 11x11 | 11x11 |
| Maxpool2 | 32 | 2 | 2 | 0 | 11x11 | 6x6 |
| Conv3 | 64 | 3 | 1 | 0 | 6x6 | 4x4 |
| Relu3 | 64 | - | - | - | 4x4 | 4x4 |
| Ip1 | 128 | - | - | - | 4x4 | 1x1 |
| Relu4 | 128 | - | - | - | 1x1 | 1x1 |
| Ip2 | 2 | - | - | - | 1x1 | 1x1 |
| softmax | - | - | - | - | 1x1 | 1x1 |
五、示例代码
#include "lazy_net.h"
int main()
{
//data information
string data_path = "data/";
int data_batch = 20;
int data_channel = 3;
int data_size = 28;
//hyperparameter
int max_iter = 1000;
int disp_iter = 10;
float weight_decay = 0.0005;
float base_lr = 0.01;
float momentum = 0.9;
string lr_policy = "inv";
float power = 0.75;
float gamma = 0.0001;
int test_iter = 50;
LazyNet lazy_net(data_path, data_batch, data_channel,
data_size, max_iter, disp_iter,
weight_decay, base_lr, momentum,
lr_policy, power, gamma, test_iter);
lazy_net.TrainNet();
return 0;
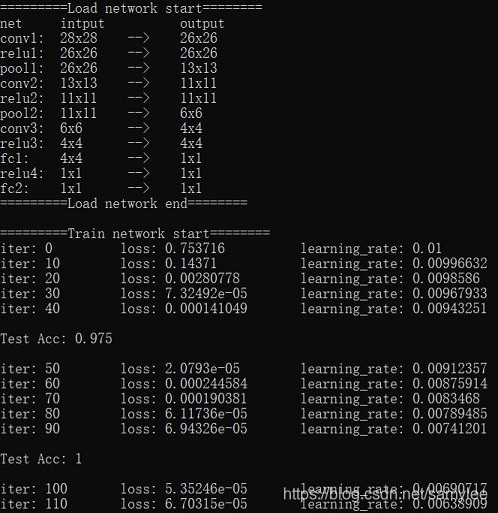
}六、示例结果
尾注
虽然这款学习框架很好理解,有利于梳理整个深度学习流程,但是也有几点不足之处,后面有时间会做相应调整
- 网络重塑性不好,网络已嵌入代码,后面考虑用文本的形式写入
- 训练数据灵活性不好,数据形式已嵌入代码,后面考虑利用random复写
- 主要layers基于caffe修改而成,后面考虑去除OpenBLAS
任何问题请加唯一QQ2258205918(名称samylee)!
或唯一VX:samylee_csdn

















 1266
1266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









