



引用Blog:
http://www.cnblogs.com/mindsbook/archive/2009/11/03/process_and_thread.html
进程和线程的定义
首先我们先要弄清楚二者的定义, 究竟什么是进程, 什么又是线程?
根据 wikipedia process 中的定义, 进程是一个计算机程序的实例,由一个或者多个线程组成.
同样在 wikipedia thread 中对线程的定义是: 线程的执行是由计算机的fork操作来将一个程序生成一个或者多个并发的运行任务.
在单核的计算机中, 线程并非 真正并行 的, 而是 分时的并发, 示意图如下:

也就是说多个线程无需等待另一个线程的完成,而只需要等待CPU的时间片.
在多核的计算机中,多个线程可以真正的并行,也就是同时执行,同时获得CPU时间片.
同样, 在现代计算机中, 通常都是 分时操作系统 (time sharing), 也就是不同的进程通过时间片来获得CPU的控制权, 来执行自己的代码. 同样,单核的系统进程也只能是并发的, 而多核的系统可以达到并行.
进程和线程的联系
二者的关系可以简单的一句话概括为, 通常, 一个进程可以包括多个线程, 一个线程只能属于一个进程.
一个进程可以生成多个线程,而这些线程之前共享地址空间和相应的资源, 在线程切换时, 并没有太多的开销.
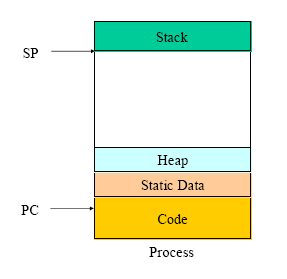
图1: 进程的执行空间示意图
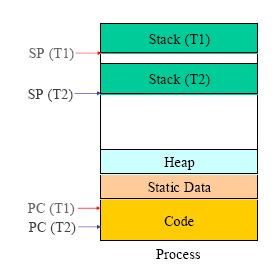
图2: 线程的执行空间示意图
从上面2个图可以很清楚地看到, 进程和线程在共享地址空间和资源的区别.
那么, 对于同样一个应用,我们可以选择 进程 来实现, 也可以选择 线程 来实现, 那么二者有什么区别呢? 我们应该如何选择呢?
进程和线程的区别
从本质上说,二者只是在 是否共享地址空间,及共享多少地址空间 上是有差别的,而至于其它的区别也都是 因为这个本质区别来引起的. 下面逐一地进行简单的说明.
安全性
因为进程之前是不共享资源和地址空间的,所以不会存在太多的安全问题(相比于线程).
而由于多个线程共享着相同的地址空间和资源,所以会存在线程之间有可能会恶意修改或者获取非授权数据的可能.
这也就是为什么近期, chrome和IE8相继开始使用多进程来替代之前的多线程(不同的tab之间).
健壮性
由于多个线程共享同一个进程的地址空间和相关的资源, 所以当一个线程出现crash,那么可能会导致相应的地址空间和资源 会出现问题,从而导致其它的线程也crash. 这个也很好理解,一个简单的大家可能都经历过的就是IE7吧, 当一个tab突然崩溃时,所有的tab都会崩溃,这时通常IE要重启(重启进程,重新生成线程).
而多进程则不存在这个问题, 因为不同的地址空间和资源, 当一个进程崩溃时, 并不会影响到其它进程. 同样,如果你用过chrome,如果一个tab崩溃了(chrome那搞笑的提示信息), 我们只需要关掉这个tab即可,并 不会影响到其它的tab.
图三: chrome崩溃时的截图
性能
进程的安全性,健壮性是建立在独立的地址空间和独立的资源的条件下的, 所以进程的 启动, 关闭, 切换 相比于线程会有更多的开销. 而这种开销的差别在Windows下更加显著, 请参考下面 特定操作系统的进程和线程 部分的详细说明.
特定操作系统的进程和线程
进程和线程是依赖于特定的操作系统的, 譬如Windows和Linux在实现进程和线程就有很大的差异, 这一部分主要说明 Windows和Linux下进程和线程的一些特定的特征.
Windows
通常做过Windows多任务系统开发的程序员肯定会知道, Windows中的进程比线程有很大的开销, 要一定坚持使用线程, 那么为什么呢?
这里有个讨论可供参考: Why is creating a new process more expensive on Windows than Linux?
简单总结下, 原因:
- 这是Windows的设计的理念所致(多用户和并行的要求不高的特性)
- 在创建进程时,会有相当的系统调用
究竟有哪些额外的系统调用,请参考上面帖子.
Linux
让我们回到本文的摘要部分的引入, 我的室友提出的对于我而言 闻所未闻 的新观点.
那么, 在Linux下 进程和线程真的没有本质区别吗?
首先大家可以参考这个帖子, Threads vs Processes in Linux.
下面内容摘自 Threads vs Processes in Linux.
Linux uses a 1-1 threading model, with (to the kernel) no distinction between processes and threads -- everything is simply a runnable task. * On Linux, the system call clone clones a task, with a configurable level of sharing, among which are: CLONE_FILES: share the same file descriptor table (instead of creating a copy) CLONE_PARENT: don't set up a parent-child relationship between the new task and the old (otherwise, child's getppid() = parent's getpid()) CLONE_VM: share the same memory space (instead of creating a COW copy) fork() calls clone(least sharing) and pthread_create() calls clone(most sharing). ** forking costs a tiny bit more than pthread_createing because of copying tables and creating COW mappings for memory, but the Linux kernel developers have tried (and succeeded) at minimizing those costs. Switching between tasks, if they share the same memory space and various tables, will be a tiny bit cheaper than if they aren't shared, because the data may already be loaded in cache. However, switching tasks is still very fast even if nothing is shared -- this is something else that Linux kernel developers try to ensure (and succeed at ensuring). In fact, if you are on a multi-processor system, not sharing may actually be a performance boon: if each task is running on a different processor, synchronizing shared memory is expensive.
上面其实已经讲得很清楚了,
- 对于内核而言, 进程和线程是 没有区别的
- 在用户的角度而言,区别在于如何创建(clone), 如果使用是 least shared ,那么就类似于进程的创建(最少共享)
- 如果使用的是 most sharing 那么就类似于线程的创建(最多共享)
- 由于Linux内核开发人员的努力和优化, 创建, 切换, 关闭 进程和线程之前的开销差异已经十分的小了
如何选择
如果你看到了这里, 应该会对进程和线程有较深入的理解, 那么我们该如何在面对多任务问题时选择呢?主要请考虑下面几个因素:
- 安全性要求
- 健壮性要求
- 性能要求
- 具体的平台
熟悉上面的具体的细节然后结合自己的应用场景, 做出最优的选择(通常做不到最优,次优即可), 这样就能够较好利用好 并发性(单核)或者并行(多核).
相关的技术细节
在结束本文之前, 我想谈下进程和线程相关的一些技术细节.
COW
COW即, Copy On Write, 具体的介绍可以参考 Copy On Write.
简单地说, COW是对下面场景的一种优化:
多任务系统对于初始时相同资源的共享, 只有当某个任务写这个资源时(更新), 才会 主动地在这个任务本地拷贝一份资源,从而不影响其它的任务.
例如, 资源author="zhutao", 这个变量资源, 在初始时由A,B,C三个任务共享author这个资源,
- 如果在整个过程, A,B,C三个任务都没有更改author, 那么整个系统只保留一份author资源的copy.
- 如果在过程中,B有修改author资源的操作,那么B会主动拷贝一份author, 然后再更改拷贝后author, 此时整个系统有2份author资源的copy.
- 以此类推, 一旦有更改的操作都会生成一份新的copy
那么从这个机制来看,它明显地有如下优势:
- 无需完全为每个任务生成资源拷贝, 而只是当修改时再生成拷贝
- 提高了任务之间切换的效率
- 提高了系统资源的利用率
- 其它
这个机制在Linux下已经得到了广泛的应用,这也是为什么Linux下进程和线程的开销差异小的原因.
线程安全(thread safety)
这个之前已经讨论过了,请参考我的博文 线程安全及Python中的GIL
进程同步
进程中的线程可能会在运行中形成不同的资源, 所以需要进行同步来达到数据的一致, 即所谓的 进程同步.
进程的同步方式有很多不同的方法, 如信号量, 锁, 事件等.
具体可以参考: Synchronization

















 964
964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









