




遵循一个网站盘一天的思想。
当你朋友做网站需要大量素材时,学爬虫的你,当然是毫不犹豫的爬给他。
这篇博客记录一下爬取感人文章的一个小爬虫,有需要规避的地方及解决方法也会列出。

本来想着会是很规范的网站,直接用xpath语法会很简单,结果往往事与愿违:
resp = requests.get(url,headers)
text = etree.HTML(resp)
urls = text.xpath("//div[@class='subBox']//div[@class='cmt_pic']//a/@href")
for url in urls:
print(url)
我们用xpath语法去解析时,报错如下:
File "src\lxml\etree.pyx", line 3170, in lxml.etree.HTML
File "src\lxml\parser.pxi", line 1876, in lxml.etree._parseMemoryDocument
ValueError: can only parse strings
大概知道就是只能解析strings类型,我们这样:
text = etree.HTML(str(resp))
urls = text.xpath("//div[@class='subBox']//div[@class='cmt_pic']//a/@href")
for url in urls:
print(url)

啥都没。。。。。
我盘了好久,XPath Helper都用了,还是没有用,找不到毛病,这里希望大神留言解决。
我同学让我换网站爬,开玩笑,我会放弃?坚决不可能,xpath不行就用万能的正则表达式。
上代码:
import pymysql
import requests
import re
import random
from lxml import etree
#连接数据库
db = pymysql.connect(host = "localhost" , user = "root" , password = "123",
database="atricle",port=3306)
#获取游标
cursor = db.cursor()
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36',
'Host' : 'www.wenzhangba.com',
'Cookies' : '__music_index__=2; count_m=1; count_h=14; first_m=1555835146650; __cfduid=dea29049d424e6bc92238400a77ea4b3c1555831911; client=61311; client__ckMd5=c363d5fbc3ff40a6; first_h=1555831911990; count_h=1; first_m=1555831911993; count_m=1; __music_index__=1; __51cke__=; UM_distinctid=16a3ecef7231f4-04ba372bea2d7d-39395704-100200-16a3ecef724b3; Hm_lvt_c46d1db4b4fbc2bdfdfe9831ab31bf3e=1555831912; CNZZDATA5923499=cnzz_eid%3D2090141217-1555828637-null%26ntime%3D1555834044; __tins__14944291=%7B%22sid%22%3A%201555834266852%2C%20%22vd%22%3A%204%2C%20%22expires%22%3A%201555836946666%7D; __51laig__=21; Hm_lpvt_c46d1db4b4fbc2bdfdfe9831ab31bf3e=1555835147'
}
def parse_page(url):
resp = requests.get(url,headers)
#失败的xpath
# text = etree.HTML(str(resp))
# urls = text.xpath("//div[@class='subBox']//div[@class='cmt_pic']//a/@href")
# for url in urls:
# print(url)
#成功的正则
resp = resp.text
urls = re.findall(r'<div class="cmt_pic">.*?<a href="(.*?)".*?</a>',resp,re.S)
for p_url in urls:
parse_detaile_page(p_url)
def parse_detaile_page(p_url):
a = {}
resp = requests.get(p_url,headers)
resp = resp.text
titles = re.findall(r'<h1>.*?<a .*?>(.*?)</a>',resp,re.S)
for title in titles:
a['title'] = title
# print(title)
datas = re.findall(r'<span class="s1">(.*?)</span>',resp,re.S)
for data in datas:
a['data'] = data
# print(data)
authors = re.findall(r'<span class="s5">(.*?)</span>|<span class="s2">(.*?)</span>', resp, re.S)
for author in authors:
if author[0] == "":
a['author'] = author[1]
else:
a['author'] = author[0]
# print(author)
images = re.findall(r'<img alt=".*?" src="(.*?)".*?>',resp,re.S)
for image in images:
# print(i)
a['image'] = image
contents = re.findall(r'<p class="inner_pic">(.*?)</div>',resp,re.S)
for content in contents:
# print("*"*50)
content = re.sub(r'<.*?>|“|”|ldquo;|rdquo;|mdash;|—',"",content).strip()
# print(content)
a['content'] = content
save_to_sql(a)
def save_to_sql(a):
s = ['感动心灵', '感人故事', '精美图文']
sql = """
insert into atricle(id, title, author, content, data, image, hits, comment, classfy) value
(null, %s, %s, %s, %s, %s, %s, %s, %s)
"""
title = a['title']
author = a['author']
content = a['content']
data = a['data']
image = a['image']
hits = random.randint(0, 2000)
comment = random.randint(0 , 2000)
classfy = s[random.randint(0,2)]
# print(image)
# print(author)
# print(title,author,content,data,image,hits,comment,classfy)
try:
cursor.execute(sql,(title,author,content,data,image,hits,comment,classfy))
# 提交执行,在插入和删除时必须有该语句
db.commit()
print("插入成功!")
except Exception as e:
print("Error", e.args)
db.rollback()
def main():
for x in range(1,80):
url = 'http://www.wenzhangba.com/ganrengushi/list_20_{}.html'.format(x)
parse_page(url)
if __name__ == '__main__':
main()
这里只有一项需要注意,就是作者,这个网站对这一块的设定比较神奇,感兴趣可以分析一下代码和网站,不在赘述。
authors = re.findall(r'<span class="s5">(.*?)</span>|<span class="s2">(.*?)</span>', resp, re.S)
for author in authors:
if author[0] == "":
a['author'] = author[1]
else:
a['author'] = author[0]
代码没什么好讲的,主要是这个网站没法用xpath解析比较难受,其中有几项数据是用随机数产生的,是我同学的要求,存储到MySQL数据库中。
另外记录一下,如果你数据库第一次读入数据了,然后在后续存储报错,解决bug后,清空数据库表继续存储:
可能会报存储文章那一列长度不足的错误,重新设置表是不行的,它会一直是0,这是正常的,但你需要删表重建,我也不知道为啥,大家的错误都一样,但回答得方案千奇百怪。。。。
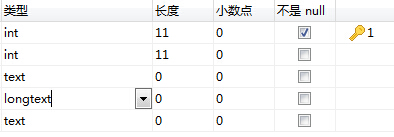
再记录一种报错:
Operand should contain 1 column(s)。
也是第一次存储正常,解决bug重新运行就错了,解法还是千奇百怪,众说纷纭,反正,没解决我的,依旧删表重建。
看看数据库
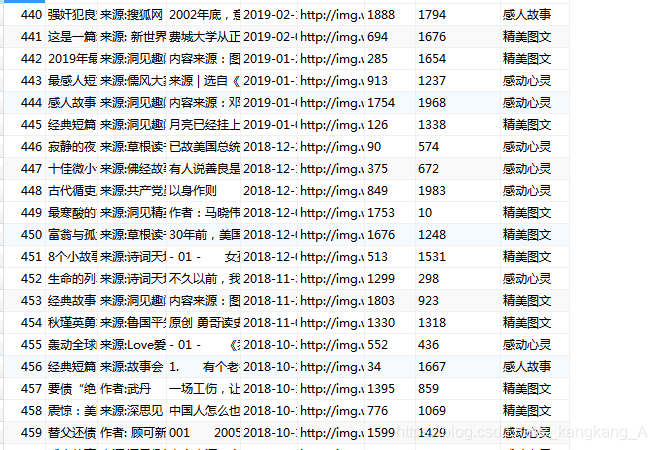

















 1042
1042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









