



目录
java.io.IOException: No FileSystem for scheme: hdfs
java.io.IOException: No FileSystem for scheme: hdfs
,用到hadoop(2.7.4)、spark(2.11),在做一个数据分片的时候,单独将程序打包提交任务到spark上执行没有任何问题,但是集成到web项目中后,就来问题了
Exception in thread "main" java.io.IOException: No FileSystem for scheme: hdfs这个问题有两种解决方法,第一种就是修改集群配置文件
core-site.xml,添加属性
fs.hdfs.impl
org.apache.hadoop.hdfs.DistributedFileSystem
The FileSystem for hdfs: uris.
这种方法有个缺点就是集群都跑起来了,还不知道有多少任务正在跑着,你跟人家停了,那不歇菜了!!!
另一种方法,那就是修改自己的代码:
configuration.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");在使用FileSystem的地方,设置org.apache.hadoop.hdfs.DistributedFileSystem
需要知道为什么这样做,参考这位大兄弟的博客, 大致意思就是。。。呃也没什么说的就是找不到配置项fs.hdfs.impl
下面贴一个操作hadoop的常用方法
public static void append(String path, String line) throws IOException {
BufferedWriter writer = null;
FSDataOutputStream fsout = null;
try {
conf = new Configuration();
conf.setBoolean("dfs.support.append", true);// 允许追加
conf.set("hadoop.user", "hadoop");//设置用户
conf.setBoolean("mapreduce.app-submission.cross-platform", true);//设置跨平台提交
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");//设置使用hdfs分布式文件系统
FileSystem fs = FileSystem.get(URI.create(path), conf);
Path pathpath = new Path(path);
if (!fs.exists(pathpath)) {
fs.create(pathpath).close();// 创建完成后关闭
}
fsout = fs.append(pathpath);// 追加
writer = new BufferedWriter(new OutputStreamWriter(fsout));
writer.write(line);
writer.newLine();
writer.flush();
} catch (IllegalArgumentException | IOException e) {
System.err.println("追加文件失败\t" + e.getMessage());
} finally {
if (fsout != null)
fsout.close();
if (writer != null)
writer.close();
}
}
/**
* 向hdfs中上传本地文件
*
* @param dst
* hdfs目录
* @param src
* 本地文件
* @return 上传是否成功,成功true,删除本地数据,否则失败;如果
*/
public static boolean put(String dst, String... src) {
try {
conf = new Configuration();
conf.set("hadoop.user", "hadoop");
conf.setBoolean("mapreduce.app-submission.cross-platform", true);
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(URI.create(dst), conf);
Path[] srcs = new Path[src.length];
for (int i = 0; i < src.length; i++) {
srcs[i] = new Path(src[i]);
}
fs.copyFromLocalFile(true, false, srcs, new Path(dst));
} catch (IllegalArgumentException | IOException e) {
System.err.println("文件上传失败\t" + e.getMessage());
return false;
}
return true;
}
/**
* 判断要给文件或者目录是否存在
*
* @param dir
* 文件或目录
* @return 是否存在
*/
public static boolean exist(String dir) {
if (StringUtils.isBlank(dir)) {
return false;
}
if (!dir.startsWith(P_HDFS)) {
dir = HDFS_URI + dir;
}
Configuration conf = new Configuration();
conf.set("hadoop.user", "hadoop");
conf.setBoolean("mapreduce.app-submission.cross-platform", true);
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
try {
FileSystem fs = FileSystem.get(URI.create(dir), conf);
return fs.exists(new Path(dir));
} catch (IllegalArgumentException | IOException e) {
System.err.println("错误\t" + e.getMessage());
return false;
}
}
public static boolean createDir(String dir) {
if (StringUtils.isBlank(dir)) {
return false;
}
if (!dir.startsWith(P_HDFS)) {
dir = HDFS_URI + dir;
}
Configuration conf = new Configuration();
conf.set("hadoop.user", "hadoop");
conf.setBoolean("mapreduce.app-submission.cross-platform", true);
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
try {
FileSystem fs = FileSystem.get(URI.create(dir), conf);
return fs.mkdirs(new Path(dir));
} catch (IllegalArgumentException | IOException e) {
System.err.println("错误\t" + e.getMessage());
return false;
}
}
/**
* 删除一个hdfs目录
* @param dir
* hdfs目录
* @return 删除是否成功
*/
public static boolean deleteDir(String dir) {
if (StringUtils.isBlank(dir)) {
return false;
}
if (!dir.startsWith(P_HDFS)) {
dir = HDFS_URI + dir;
}
Configuration conf = new Configuration();
conf.set("hadoop.user", "hadoop");
conf.setBoolean("mapreduce.app-submission.cross-platform", true);
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
boolean ret = false;
try {
FileSystem fs = FileSystem.get(URI.create(dir), conf);
ret = fs.delete(new Path(dir), true);
fs.close();
} catch (IOException e) {
System.err.println("错误\t" + e.getMessage());
ret = false;
}
return ret;
}Container killed on request. Exit code is 143
运行中发现有任务被kill掉,多半是因为内存分配不足造成,所有需要修改内存配置。
可先参考
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>22528</value>
<discription>每个节点可用内存,单位MB</discription>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1500</value>
<discription>单个任务可申请最少内存,默认1024MB</discription>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
<discription>单个任务可申请最大内存,默认8192MB</discription>
</property>然后在mapred-site.xml中添加下面内容:
<property>
<name>mapreduce.map.memory.mb</name>
<value>1500</value>
<description>每个Map任务的物理内存限制</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3000</value>
<description>每个Reduce任务的物理内存限制</description>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1200m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2600m</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>重启yarn再启动mapreduce任务,就可以了
但实际我遇到问题是在spark提交任务时参数做了如下设置
--conf spark.memory.fraction=0.9 \
--conf spark.memory.storageFraction=0.9 \改为
--conf spark.memory.fraction=0.2 \
--conf spark.memory.storageFraction=0.4 \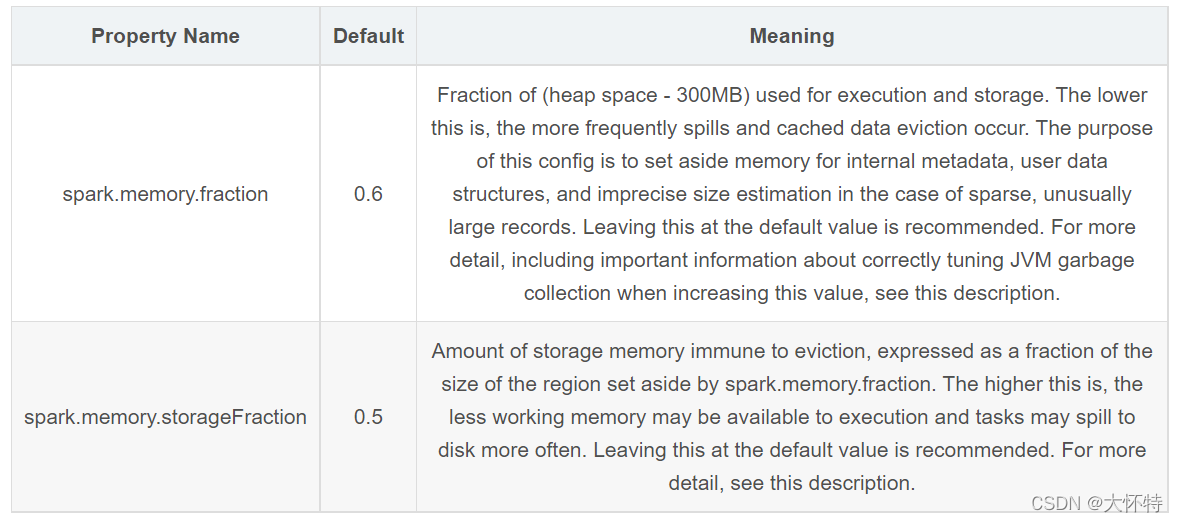


















 360
360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











