



 这个博客内容涉及到Ruby编程中处理中文字符的技巧,主要讲解了一个方法,用于将网页源码中的Unicode编码转换为UTF-8,以便正确显示中文。通过使用gsub方法和正则表达式匹配Unicode编码,然后进行解码和转换,确保中文字符在控制台或网页上能正确呈现。
这个博客内容涉及到Ruby编程中处理中文字符的技巧,主要讲解了一个方法,用于将网页源码中的Unicode编码转换为UTF-8,以便正确显示中文。通过使用gsub方法和正则表达式匹配Unicode编码,然后进行解码和转换,确保中文字符在控制台或网页上能正确呈现。
Ruby 中文unicode编码转utf-8
将网页源码中unicode编码的中文的转换成utf-8,显示成中文
def zh_unicode_utf8
self.gsub(/\\u\w{4}/) do |s|
str = s.sub(/\\u/, "").hex.to_s(2)
if str.length < 8
CGI.unescape(str.to_i(2).to_s(16).insert(0, "%"))
else
arr = str.reverse.scan(/\w{0,6}/).reverse.select{|a| a != ""}.map{|b| b.reverse}
hex = lambda do |s|
(arr.first == s ? "1" * arr.length + "0" * (8 - arr.length - s.length) + s : "10" + s).to_i(2).to_s(16).insert(0, "%")
end
CGI.unescape(arr.map(&hex).join)
end
end
end
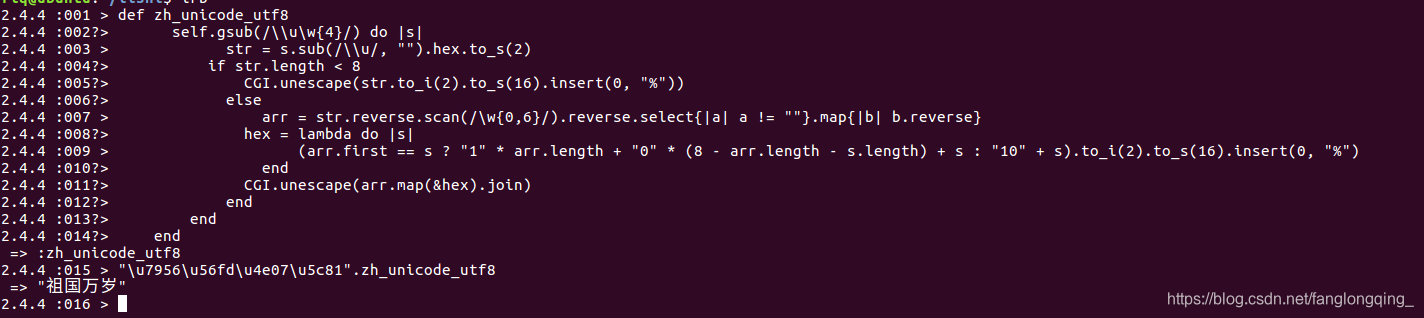 控制台irb实际操作
控制台irb实际操作


















 1691
1691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











