




 本文聚焦JDK优化,介绍了HashMap的优化。JDK1.7及以前,HashMap是数组+链表结构,易产生碰撞和扩容;JDK8改为数组+链表+红黑树,提升删改查效率。HashSet、ConcurrentHashMap等也有优化。还提到JDK8去掉永久区,方法区成元空间,降低内存溢出概率。
本文聚焦JDK优化,介绍了HashMap的优化。JDK1.7及以前,HashMap是数组+链表结构,易产生碰撞和扩容;JDK8改为数组+链表+红黑树,提升删改查效率。HashSet、ConcurrentHashMap等也有优化。还提到JDK8去掉永久区,方法区成元空间,降低内存溢出概率。
对HashMap等的优化
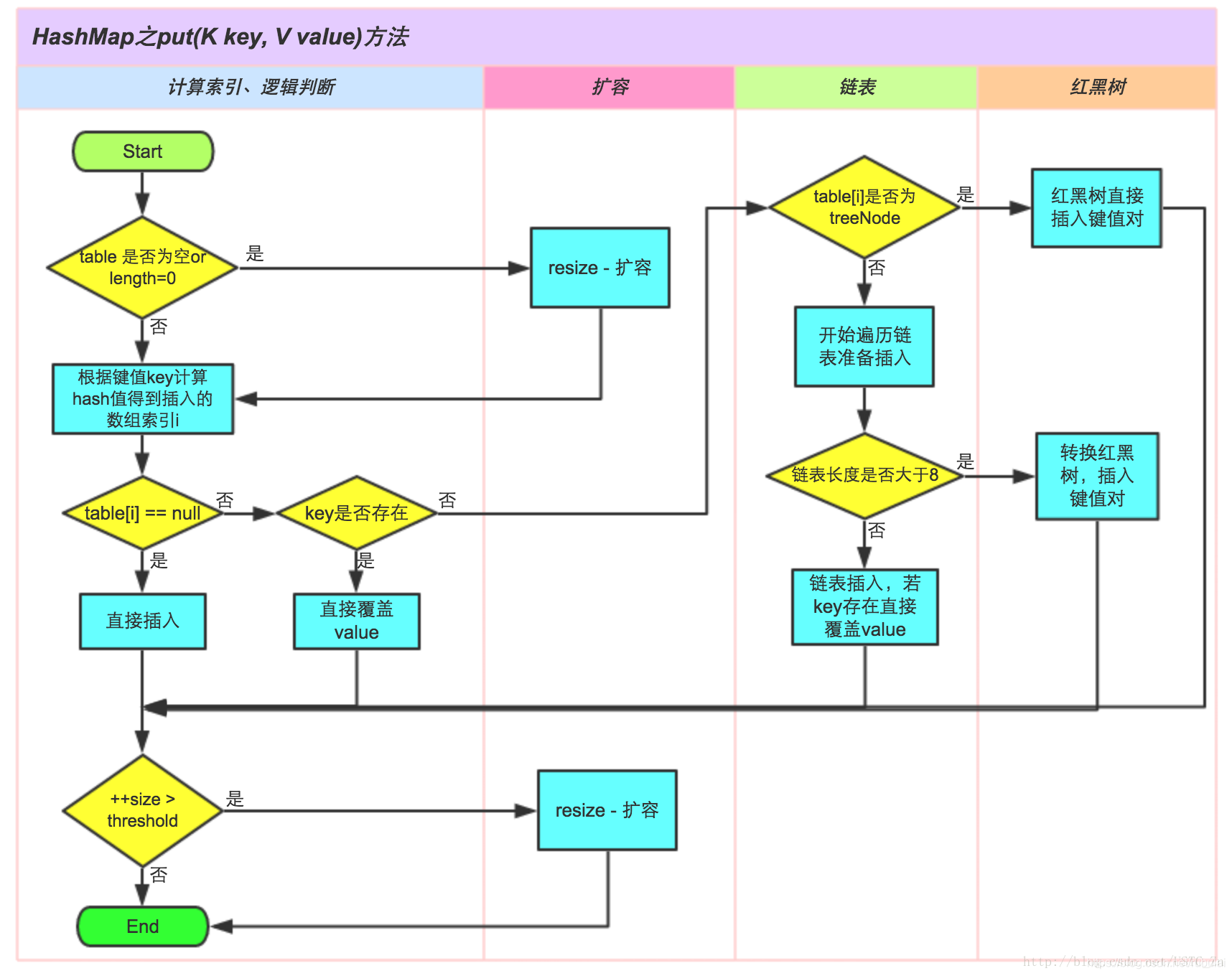
在JDK1.7及以前的版本中,HashMap的数据结构是数组+链表,在往HashMap中存放数据对象的时候,会先根据哈希算法对该对象进行计算,得出该对象的哈希码,再根据哈希码计算该对象在HashMap数组中的位置,以确定该对象应该存放的具体位置。然而计算得来的哈希码虽然不会重复,但是计算出来的位置坐标是会重复的,因为HashMap数组的长度不是无限大的(默认为16),这样就会产生碰撞(多个对象存放在HashMap数组的同一个坐标位置)。在产生碰撞后,会对同一坐标位置的对象依次进行equals比较,比较后如果内容相同则value值进行替换,否则则会形成一个链表,后进入的对象放在链表的末尾,很显然,链表越长越影响效率。
为了避免链表的长度过长,HashMap有自动扩容机制(默认的加载因子大小为0.75,即容量达到HashMap数组的75%时会自动扩容至原容量的2倍),自动扩容后又会重新计算存放在HashMap中的对象的哈希码,以计算新的位置坐标,再将这些对象重新存放。因此应该尽量避免产生碰撞和扩容,我们可以在创建HashMap时估算存放数据的数量以指定容量,存放的数据数量最好为指定的容量的75%。
JDK8及其之后的HashMap的数据结构改为了数组+链表+红黑树,当存放在HashMap数组中的对象形成的链表长度超过8或者HashMap的总数据数超过64的时候,HashMap会把每个数组位置上的数据变成一个红黑树,这样做就大大的提升删改查的效率,但是增加数据的效率会降低。
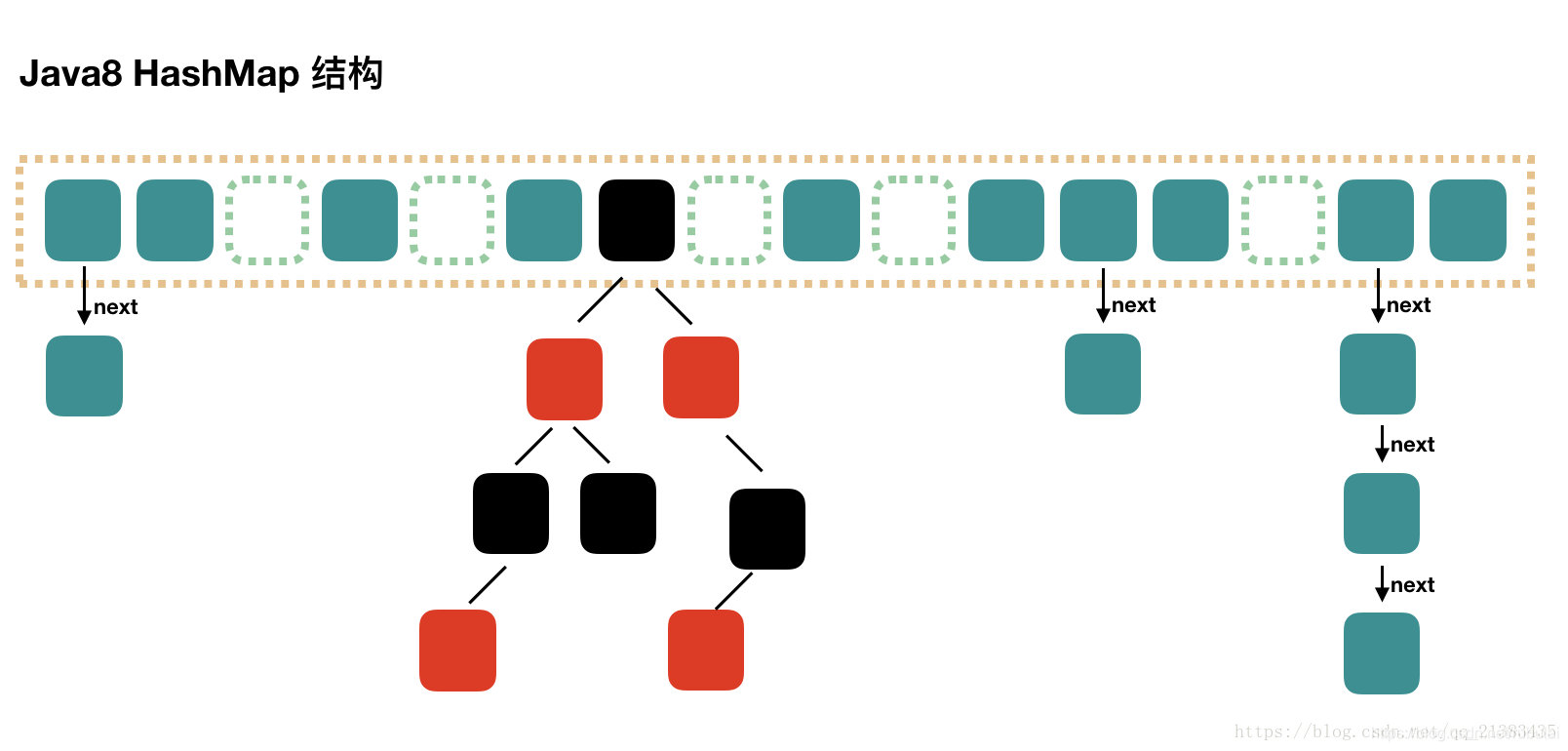
相应的HashSet、ConcurrentHashMap等在JDK8中也做了相应的优化。
对内存结构的优化
JDK8去掉了堆内存中的永久区,方法区从原来的永久区剥离出来成为元空间(MetaSpace),并且元空间直接使用物理内存,而不必自己分配内存,一般而言物理内存的容量是足够大的,这样垃圾回收机制运行的概率就会大大降低,内存溢出的概率也会大大降低。在进行内存调优的时候,原来的PermGenSize和MaxPermGenSize参数在JDK8中就没有用处了,取而代之的是MetaSpaceSize和MaxMetaSpaceSize,也就是说元空间的大小默认是物理内存的大小,但我们也可以指定元空间使用的内存空间大小。

















 1867
1867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









