



 该论文提出了一种名为PSTA的金字塔时空特征融合模型,用于视频行人重识别任务,以解决视频中的干扰信息问题。PSTA通过时空聚合模块逐级提取高维时序特征,增强模型的鲁棒性和准确性。实验结果显示,PSTA在多个数据集上优于现有方法。
该论文提出了一种名为PSTA的金字塔时空特征融合模型,用于视频行人重识别任务,以解决视频中的干扰信息问题。PSTA通过时空聚合模块逐级提取高维时序特征,增强模型的鲁棒性和准确性。实验结果显示,PSTA在多个数据集上优于现有方法。
1论文动机
行人重识别技术的目的是实现跨摄像头的行人快速检索。因为在现实场景中的广泛应用,它已经成为计算机视觉领域的一个热门方向。虽然基于图像的行人重识别方法已取得了一些令人瞩目的进展。但是在实际应用中图像数据容易出现遮挡或者错误检测等问题,因而严重影响了行人重识别的精度。相比图像数据,视频数据包含更为丰富的时空信息,因而能避免图像数据的一些弊端,从而提取出更加有效的行人特征。为了获取视频中对应的行人特征,过去提出的一些方法比较倾向于直接利用3D卷积[1]或循环神经网络[2]进行时空信息建模。但是受采样环境的影响,视频中不可避免地会出现干扰信息,例如缺失行人、物体遮挡、错误检测等。这些干扰信息的存在给时空建模带来了巨大困难,如图1所示。为此,本文针对性地提出了金字塔型时空特征融合模型(PSTA),在进行时空建模的同时能削弱干扰信息对特征表示的影响,从而提升行人重识别的精确度和鲁棒性。

图1.聚合视频特征的方式
2论文题目
[ICCV 2021] Pyramid Spatial-Temporal Aggregation for Video-based Person Re-identification
王英权(江苏大学),张平平(大连理工大学),高尚(大连理工大学),耿霞(江苏大学),陆虎(江苏大学),王栋(大连理工大学)
论文链接:
ICCV 2021 Open Access Repository
代码开源:
https://github.com/WangYQ9/VideoReID_PSTA
3创新点
本文提出了一种针对视频行人重识别特征融合的新范式。模型的设计灵感主要来自于以下两个判断:
- 视频作为一种典型的三维数据,若直接采用3D卷积或循环神经网络处理,有可能会丢失图像的细粒度信息或引入较大的运算量。
- 干扰信息在视频数据中普遍存在,因此需要对此做针对性的处理和设置。
本文的主要技术贡献有:
- 采用了一种新的金字塔型特征融合范式来进行时空建模,即能在一定程度上保留图像的细粒度信息,同时能兼顾长时序和短时序帧间的联系。
- 设计了一个新的特征聚合模块,即时空聚合模块,作为金字塔结构特征聚合的单元。它能够同时挖掘特征图内像素点间的空间信息以及相邻特征图像素点间的时序信息,进而达到逐级提取高维时序特征的目的。
- 在考虑相邻特征图像素点间联系时,引入了相似度对比矩阵。给予时空聚合模块判断哪些像素点为干扰信息的能力,使时空聚合模块能更加准确的避免干扰的影响,将更多的注意放在目标行人上。
4相关工作
为了从视频中提取出鲁棒的行人表征,研究人员进行了大量的研究。总体说来,为了获取视频特征,要么通过连续帧帧间相互参照对比的方式,获取融合信息[3];要么通过生成一个全局向量来指导获取融合信息[4]。但当遮挡或干扰信息出现时,这些方法可能会受到比较大的影响。并且这些方法往往只关注短时序内或长时序内的细粒度信息,没有将它们充分地结合起来。
5方法描述
本文旨在探索一种金字塔型的空时特征融合新范式,逐级地融合特征获得行人在不同时序条件下的轨迹表示,同时保证细粒度特征不丢失。此外,通过金字塔结构的特征聚合单元,识别并削弱干扰信息的影响。
5.1金字塔结构
如图2所示,对给定一个视频序列,首先利用ResNet50[5]提取出每张图片对应的帧特征。而后,以两帧特征为一组,逐层地输入时空特征融合模块进行特征聚合,
Ftn=STAMnF2t-1n-1, F2tn-1,t=1, 2,⋯,T2n![]()
其中,在金字塔浅层的Ftn![]() 可视为行人的具象特征。随着层数的加深,Ftn
可视为行人的具象特征。随着层数的加深,Ftn![]() 能提取到行人更加泛化的抽象特征。最终,将金字塔结构不同层的输出合并起来,得到一个更为鲁棒的行人特征表示,
能提取到行人更加泛化的抽象特征。最终,将金字塔结构不同层的输出合并起来,得到一个更为鲁棒的行人特征表示,
XN= 1Nn=1NFn![]()
在本文的实验中,将X3![]() 作为行人最终的特征表示进行重识别测试。
作为行人最终的特征表示进行重识别测试。
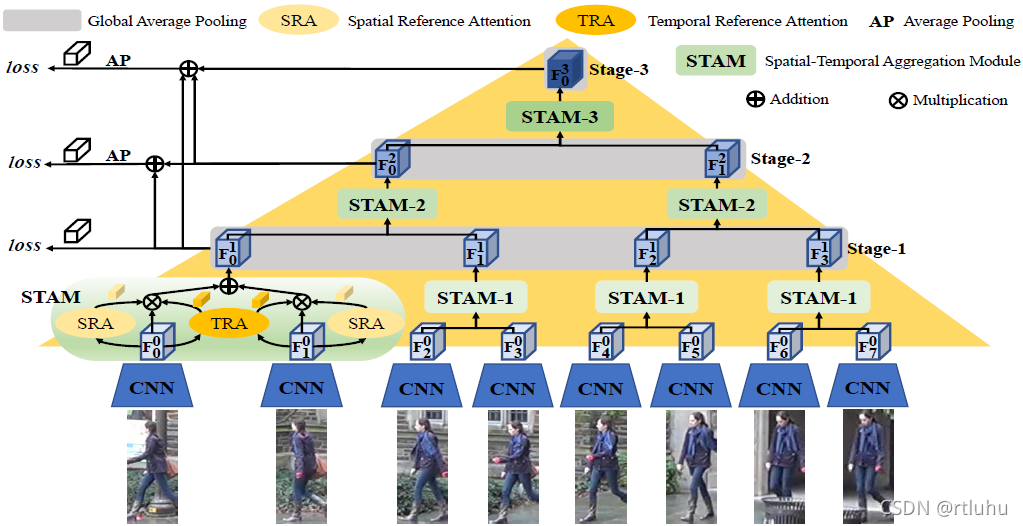 图2. PSTA模型的整体框架。在金字塔同一层的时空特征融合模块(STAM)参数共享。
图2. PSTA模型的整体框架。在金字塔同一层的时空特征融合模块(STAM)参数共享。
5.2空时聚合模块
为了使时空特征聚合模块的特征图内和图间信息被充分挖掘。受先前工作的启发[6][7],本文引入了时间(TRA)和空间(SRA)特征聚合模块用于生成输入对应的注意力矩阵Atn,At+1n,At,t+1n,At+1,tn![]() ,最后将两两一组的输入聚合在一起,如图3所示。具体的表示形式为
,最后将两两一组的输入聚合在一起,如图3所示。具体的表示形式为
Fn=Res[Ft,t+1T+Ft+1, tT+(FtS+Ft+1S)]![]()
其中,FtS![]() 和Ft,t+1T
和Ft,t+1T![]() 分别表示为
分别表示为
FtS=At∘Ft ![]() ,
,
Ft,t+1T=At,t+1∘Ft![]() 。
。
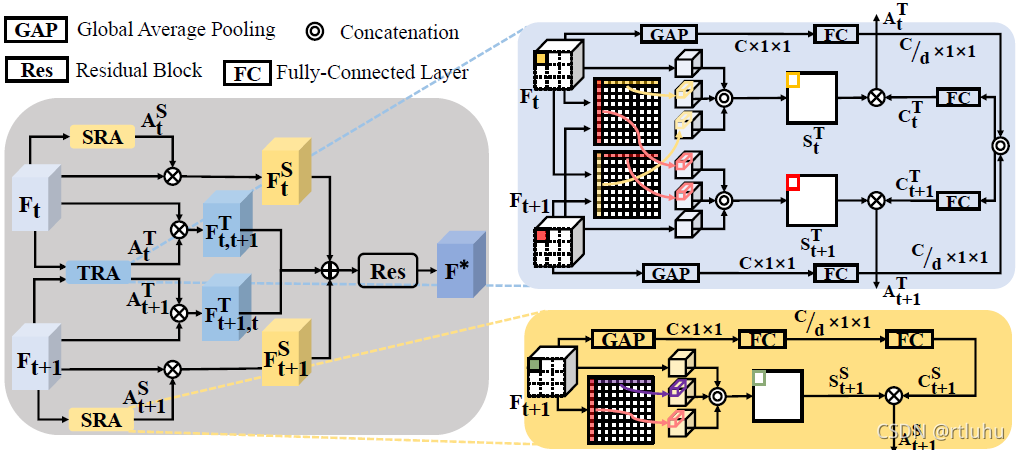
图3. 时空特征聚合模块的具体结构。右上方和右下方分别为时间和空间特征聚合模块
6实验结果
在视频行人重识别任务上,本文算法在MARS, DukeMTMC-VID, PRID, iLIDS-VID 和 PRID-2011四个数据集上进行了算法对比。首先,如图4所示,对比生成的热力图的效果可以发现PSTA相比基线方法能更好地降低干扰信息对提取行人特征的影响,使模型的更关注在目标行人上。
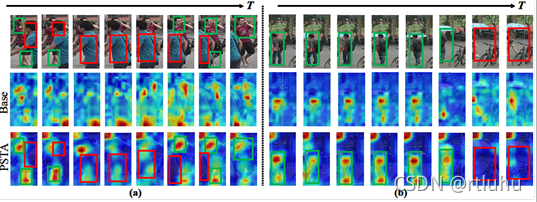
图4.基线和 PSTA 的可视化对比。其中红框表示干扰信息,绿框表示目标行人信息。
在四个基准数据集上,本文将PSTA和同时期主流方法进行数值对比,结果如表1和表2所示。PSTA的结果相对优于现有方法,说明PSTA确实能获得更鲁棒的行人特征表示。
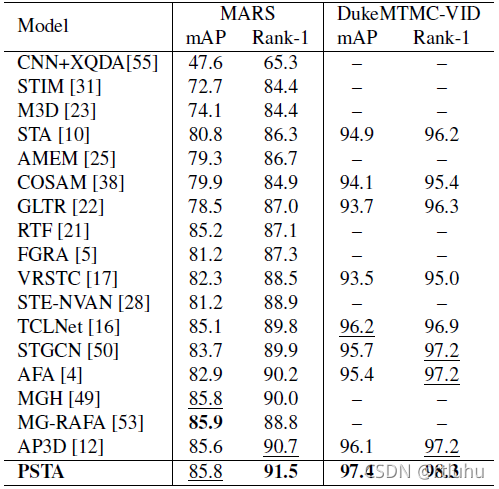
表1. 在MARS和DukeMTMC-VID数据集上和其他主流方法的结果对比
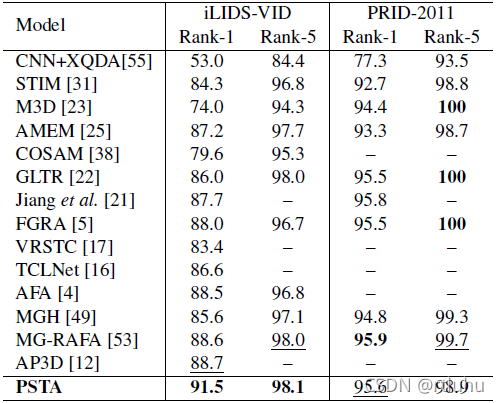
表2. 在iLIDS-VID 和 PRID-2011数据集上和其他主流方法的结果对比
为了验证模型中各个模块的有效性,本文还在MARS和DukeMTMC-VID这两个大型数据集上进行了消融性实验。实验结果表明,PSTA中各个设计部分都能发挥一定有效作用。
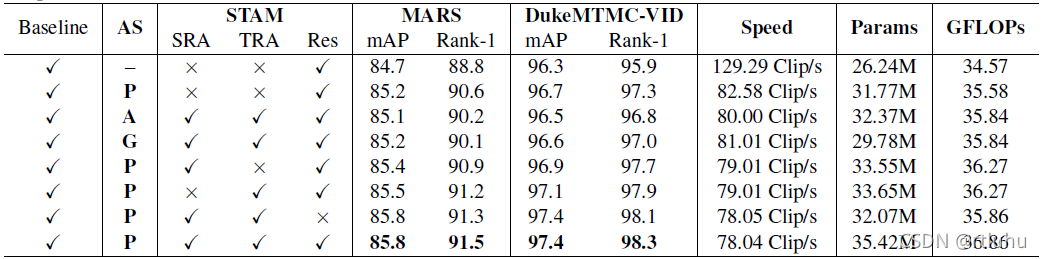
表3. 消融性实验结果
7参考文献
[1] Xinqian Gu, Hong Chang, Bingpeng Ma, Hongkai Zhang and Xilin Chen. Appearance-Preserving 3D Convolutional for Video-based Person Re-Identificaition. In ECCV, pages 228-243, 2020.
[2] Le Zhang, Shi Zenglin, Joey Tianyi Zhou, Ming-ming Cheng, Yun Liu, Jia-Wang Bian, Zeng Zeng and Chunhua Shen. Ordered or Orderless: A Revisit for Video based Person Re-Identification. TPAMI, 43(4):1460-1466, 2021.
[3] Yiheng Liu, Zhenxun Yuan, Wengang Zhou, and Houqiang Li. Spatial and Temporal Mutual Promotion for Video-based Person Re-Identification. In AAAI, pages 8786-8793, 2019.
[4] Zhizheng Zhang, Cuiling Lan, Wenjun Zeng, and Zhibo Chen. Multi-Granularity Reference-Aided Attentive Feature Aggregation for Video-based Person Re-Identification. In CVPR, pages 10407-10416, 2020.
[5] Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun. Deep Residual Learning for Image Recognition. In CVPR, pages 770-778, 2016.
[6] Zhizheng Zhang, Cuiling Lan, Wenjun Zeng, Xin Jin and Zhibo Chen. Relation-Aware Global Attention for Person Re-Identification. In CVPR, pages 3186-3195, 2020.
[7] Jianing Li, Shiliang Zhang, and Tiejun Huang. Multi-Scale 3D Convolution Network for Video-based Person Re-Identification. In AAAI, pages 8618-8625, 2019.


















 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









