




聚簇索引和非聚簇索引的数据分布有区别,以及对应的主键索引和二级索引的数据分布也有区别。下面我们看 InnoDB 和 MyISAM 是如何存储下面这个表:
DROP TABLE IF EXISTS test; – 若表已存在,则删除
CREATE TABLE test (
id INT NOT NULL,
num int NOT NULL,
tag CHAR(12) NOT NULL,
PRIMARY KEY(id), – 主键索引
KEY(num) – 辅助索引
– 尝试不同的引擎 MyISAM InnoDB
) ENGINE=MyISAM;
复制代码
然后插入下面的数据,id从1-9,故意把插入顺序打乱,tag代表插入顺序
INSERT test(id, num, tag) VALUES(7, 1, ‘no.1’);
INSERT test(id, num, tag) VALUES(5, 19, ‘no.2’);
INSERT test(id, num, tag) VALUES(6, 7, ‘no.3’);
INSERT test(id, num, tag) VALUES(9, 5, ‘no.4’);
INSERT test(id, num, tag) VALUES(3, 13, ‘no.5’);
INSERT test(id, num, tag) VALUES(4, 17, ‘no.6’);
INSERT test(id, num, tag) VALUES(2, 3, ‘no.7’);
INSERT test(id, num, tag) VALUES(8, 23, ‘no.8’);
INSERT test(id, num, tag) VALUES(1, 11, ‘no.9’);
复制代码
MyISAM的数据存储
MyISAM按照数据插入的顺序存储在磁盘上,我们假设第一行数据在数据库表文件中的偏移位置是1,以此类推。 如下图
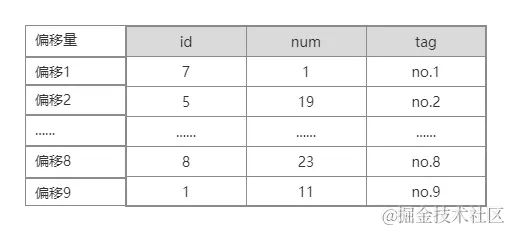
现在我们验证一下,使用 SELECT * FROM test; 扫描全表(SELECT * 不会使用任何索引,可以用 explain 实际观察下),输出的顺序正是我们sql插入的顺序,大家可以调整sql的顺序再次插入,观察输出顺序。

搞清楚了MyISAM的数据存储方式,再来看下主键索引的存储。我们假设每个磁盘块只能存储两个节点数据,MyISAM的主键分布如下图:
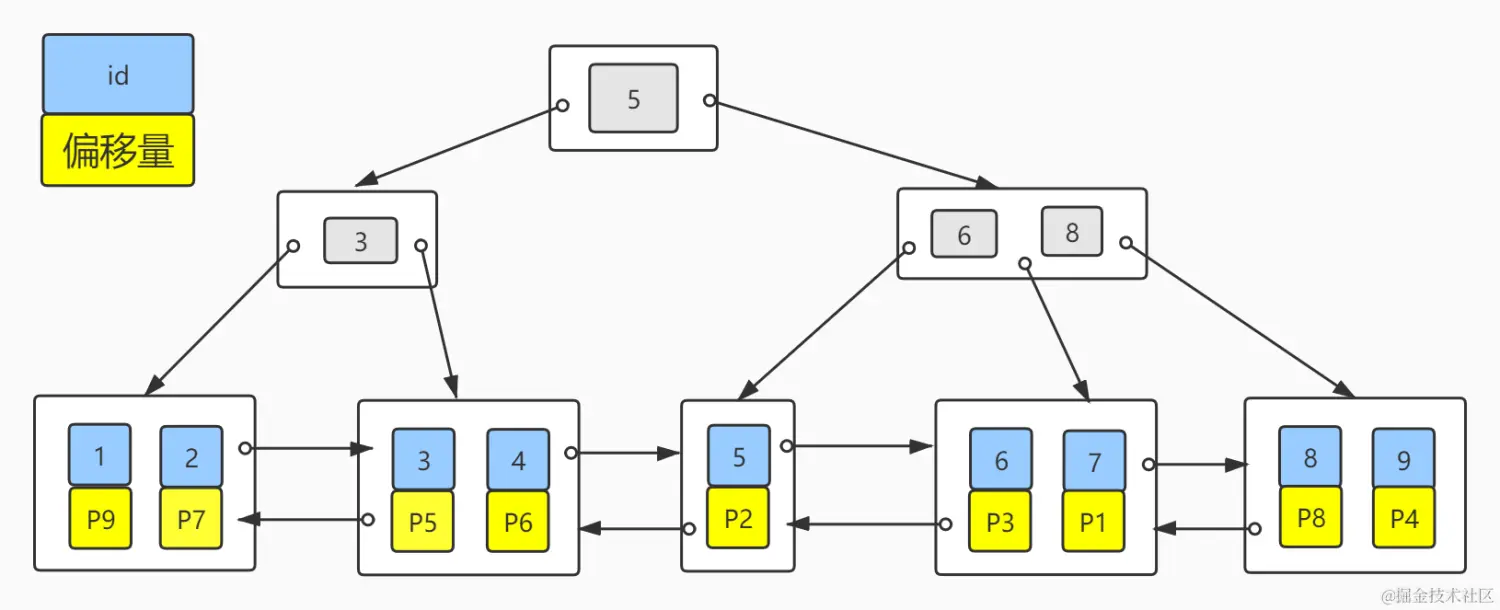
其实MyISAM的二级索引和主键索引并无区别,只是名称不同罢了,二级索引key(num)分布如下图:
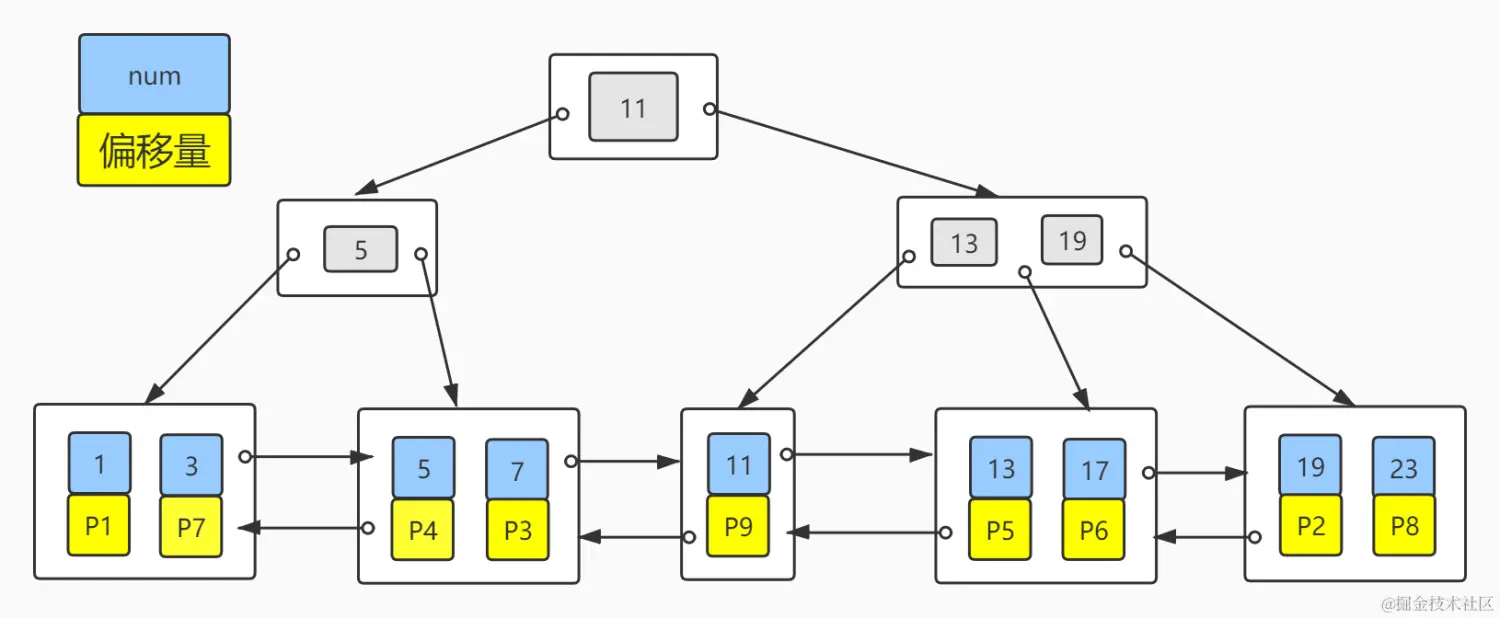
二级索引子节点也只存储了索引列(num)和文件的偏移量(P),但可以看出num是有序的,这在范围查找(比如:where num > 3)是非常有利的,但文件的偏移量并没有规律,当需要回表查询其他字段,可能会导致多次随机I/O。
当对增加数据时MyISAM直接添加到文件尾部,不需要移动其他数据,而且更新主键时,也不会导致其他行数据移动,但它不支持行级锁,修改时直接锁表。若不需要事务支持,对读多写少的场景可以考虑MyISAM引擎,但不要默认使用MyISAM引擎。
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Android工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此收集整理了一份《2024年Web前端开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点!不论你是刚入门Android开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!

















 2161
2161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









