




 本文深入解析变分自编码器(VAE)的工作原理与实现步骤。介绍了如何通过正态分布假设简化后验概率,并采用重构损失与KL散度损失来训练模型。此外,还详细展示了使用Keras实现VAE的具体代码实例。
本文深入解析变分自编码器(VAE)的工作原理与实现步骤。介绍了如何通过正态分布假设简化后验概率,并采用重构损失与KL散度损失来训练模型。此外,还详细展示了使用Keras实现VAE的具体代码实例。
1 理论
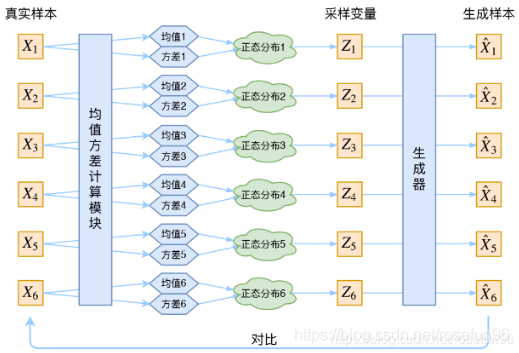
假设后验分布
p
(
z
∣
x
)
p(z|x)
p(z∣x) 是服从正态分布。
两个loss, 一个是重构误差,一个是p(z)分布和标准正态分布的散度(假定p(z)是服从标准正态分布)。
2.1 模型目的
为了随便给定一个分布 z, 能够产生很多数据 x。z的分布可以随便取,比如简单的标准高斯分布,但是
p
θ
(
x
)
=
p
θ
(
x
∣
z
)
p
θ
(
z
)
/
p
θ
(
z
∣
x
)
p_{\theta}(x)=p_{\theta}(x | z) p_{\theta}(z) / p_{\theta}(z | x)
pθ(x)=pθ(x∣z)pθ(z)/pθ(z∣x), 我们的
p
θ
(
z
∣
x
)
p_{\theta}(z | x)
pθ(z∣x)未知,可以由编码器网络进行拟合。
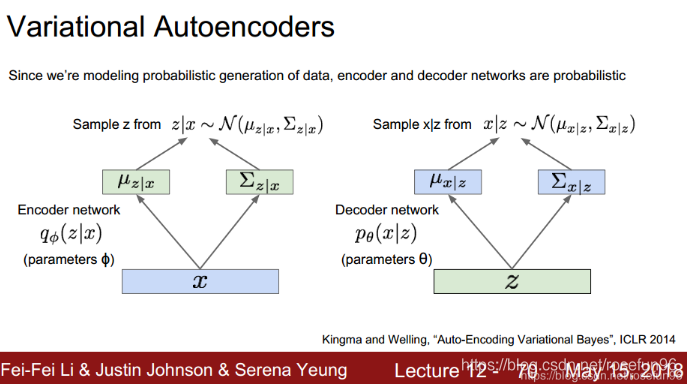
2.2 拟合误差loss
由两部分组成,一部分是编码解码后x的偏差;另一部分是,x到z采样的分布和z的假设先验分布的差异。

值得注意的是,KL散度误差可以推导出更为简洁的公式:

2.3 重采样
为什么需要重采样?
重采样的过程在反向传播是不可导,可导的是采样后的结果(公式),因此,我们用标准正态分布来完成采样过程,在利用公式 Z = μ + ε × σ Z=\mu+\varepsilon \times \sigma Z=μ+ε×σ获得采样的结果,这个公式反向传播就可以对均值,方差求偏导了,完成反向传播的过程。
2 实践
x = Input(shape=(original_dim,))
h = Dense(intermediate_dim, activation='relu')(x)
# 算p(Z|X)的均值和方差
z_mean = Dense(latent_dim)(h)
z_log_var = Dense(latent_dim)(h)
# 重参数技巧
def sampling(args):
z_mean, z_log_var = args
epsilon = K.random_normal(shape=(K.shape(z_mean)[0], latent_dim), mean=0.,
stddev=epsilon_std)
return z_mean + K.exp(z_log_var / 2) * epsilon
# 重参数层,相当于给输入加入噪声
z = Lambda(sampling, output_shape=(latent_dim,))([z_mean, z_log_var])
# 解码层,也就是生成器部分
decoder_h = Dense(intermediate_dim, activation='relu')
decoder_mean = Dense(original_dim, activation='sigmoid')
h_decoded = decoder_h(z)
x_decoded_mean = decoder_mean(h_decoded)
# 建立模型
vae = Model(x, x_decoded_mean)
# xent_loss是重构loss,kl_loss是KL loss
xent_loss = original_dim * metrics.binary_crossentropy(x, x_decoded_mean)
kl_loss = - 0.5 * K.sum(1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1)
vae_loss = K.mean(xent_loss + kl_loss)
# add_loss是新增的方法,用于更灵活地添加各种loss
vae.add_loss(vae_loss)
vae.compile(optimizer='rmsprop')
vae.summary()
vae.fit(x_train,
shuffle=True,
epochs=epochs,
batch_size=batch_size,
validation_data=(x_test, None))
# 构建encoder,然后观察各个数字在隐空间的分布
encoder = Model(x, z_mean)
x_test_encoded = encoder.predict(x_test, batch_size=batch_size)
plt.figure(figsize=(6, 6))
plt.scatter(x_test_encoded[:, 0], x_test_encoded[:, 1], c=y_test_)
plt.colorbar()
plt.show()
# 构建生成器
decoder_input = Input(shape=(latent_dim,))
_h_decoded = decoder_h(decoder_input)
_x_decoded_mean = decoder_mean(_h_decoded)
generator = Model(decoder_input, _x_decoded_mean)
注意:
本文用到的图片均来源参考2链接,以及李菲菲cs231n 课程中 章节GeneratIve Modes PPT.
参考:
1github vae.py;
2 blog vae;
3 mnist.npz;
4. 变分推断 csdn;
5. pytorch for vae;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











