




今年最值得开心的事情,就是Spark Application在客户局点跑的效果。虽然里面涉及的算法由于涉密所以不能透露,但是性能杠杠的还是值得高兴一下的。
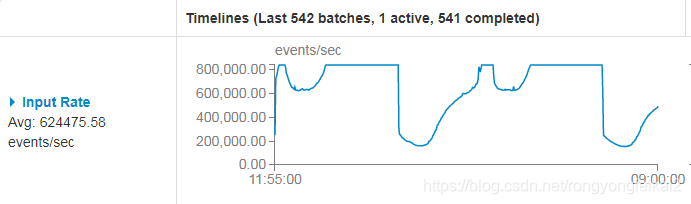
每秒钟的数据量大概为40万~80万条。
实时Spark Application的性能(开5分钟的时间窗口):
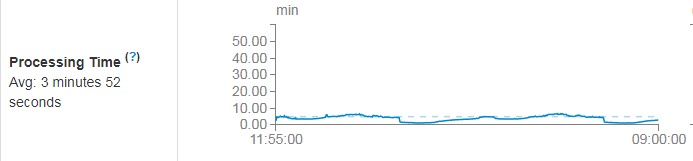
5分钟内可以处理完,没有延迟和堆积。

离线Spark Application的性能(一天跑一次,一次处理前一天的数据):

大概4.5个小时处理完毕,一天的数据量为几百亿级别,输入数据大小为2.1TB左右:
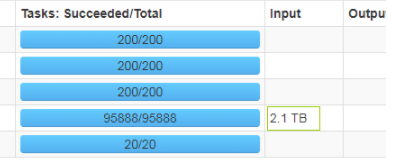
可以这么刚,我还是非常欣慰的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









