




 该文介绍了一种名为MaskCLIP的方法,该方法利用CLIP模型进行图像分割任务。通过改进CLIP模型的图像编码器和文本编码器部分,MaskCLIP能够有效应用于像素级别的密集预测任务。文中还提出了一种名为MaskCLIP+的技术,该技术可以为未见过的对象生成伪标签以增强模型的泛化能力。
该文介绍了一种名为MaskCLIP的方法,该方法利用CLIP模型进行图像分割任务。通过改进CLIP模型的图像编码器和文本编码器部分,MaskCLIP能够有效应用于像素级别的密集预测任务。文中还提出了一种名为MaskCLIP+的技术,该技术可以为未见过的对象生成伪标签以增强模型的泛化能力。
一篇CLIP应用在语义分割上的论文
论文标题:
Extract Free Dense Labels from CLIP
作者信息:

代码地址:
https://github.com/chongzhou96/MaskCLIP
Abstract:
许多论文研究了CLIP在图像分类的表现,作者提出了采用CLIP去处理像素型密集任务,如图像分割,作者提出了MaskCLIP和MaskCLIP+均取得了很好的效果。
Introduction
(作者认为CLIP模型有处理密集型预测任务的潜力,具有以下优势:)
1.能够学习一些局部的语义特征(从NLP中)。
2.能够学习一些开放的词汇的概念。
3.能够捕获丰富的上下文本信息。
(作者的尝试和经验)
1.不要打破CLIP中固有的visual-language association。作者早期将CLIP中的img encode单独拿出用于初始化如deeplab的backbone并Fine tune。使CLIP的泛化能力降低。
2.不要对CLIP中的text encode做太多改变,会使CLIP丢失对unseen物体的分割能力。
(作者的贡献和模型的效果)
1.作者提出了MaskCLIP模型:从CLIP中的 Img encode获得patch-level图像特征,从text encode直接获得像素预测的权重,而没有采用有意的映射。
(另一篇论文有些类似:也取消了采用GAP生成CAM,而是改用1×1的卷积直出)
2.提出两种refine技术:key smoothing 和prompt denoising。
2.提出了MaskCLIP+,利用MaskCLIP对unseen的物体生成伪标签,然后进行训练。
Methodology
下图为模型的整体概略图
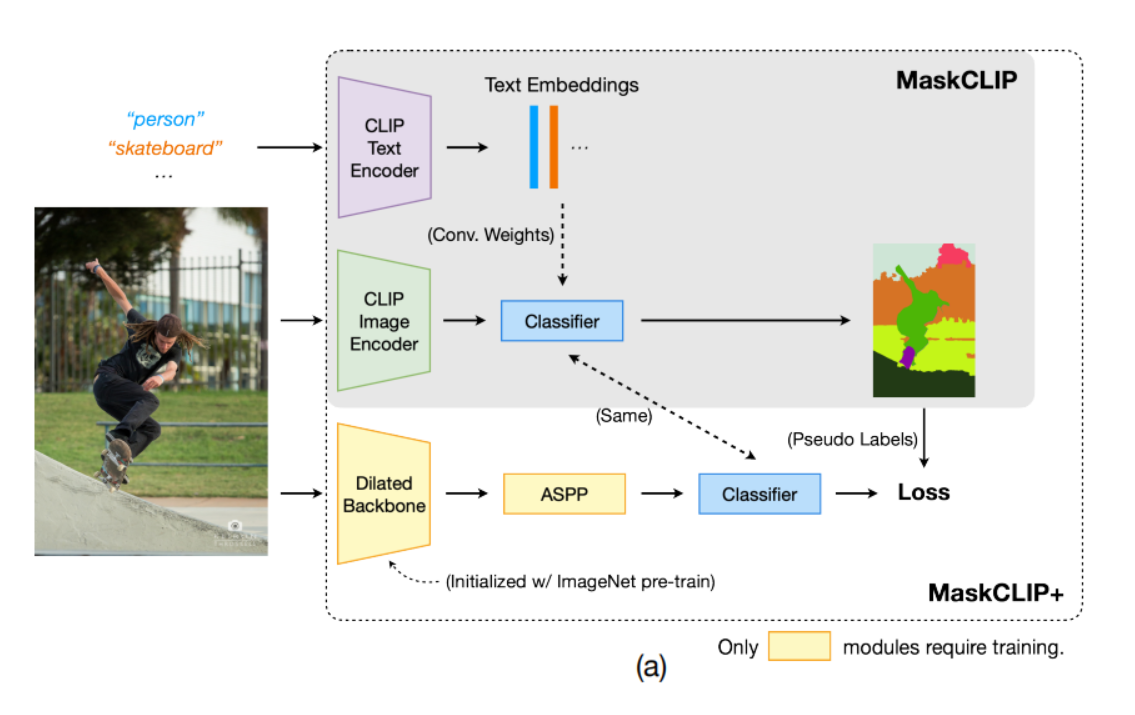
3.1 Preliminary on CLIP
(作者简单介绍了下CLIP模型)
3.2 Conventional Fine-Tuning Hinders Zero-Shot Ability
(对于分割问题的范式)1.初始化在Image net上预训练的backbone,2.添加专用于分割模块(随机初始化权重)3.fine tune backbone,增添新的模块。
(作者仿照这样的思路)首先,用image encoder of CLIP替换ImageNet预训练的backbone(deeplab)。然后,使用映射
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1228
1228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









