




头文件:
#include<unistd.h>
#include<sys/types.h>
函数定义:
pid_t fork(void);
pid_t只是一个typedef定义,在不同的平台下可能是不同的数据类型(short, int , long),只是为了令可移植性好一些,其定义在文件 sys/types.h中。
函数返回值:
在父进程当中,返回子进程的ID,在子进程当中,返回0,失败返回-1.
函数说明:
一个现有进程可以调用fork函数创建一个新进程。由fork创建的新进程被称为子进程(child process)。fork函数被调用一次但返回两次。两次返回的唯一区别是父进程中返回子进程ID,而子进程中返回0值。
我们可以利用返回值的这一特性,来确定当前是处于子进程还是父进程当中。
if ((retValue = fork()) == 0) // 0,当前位于子进程当中,执行子进程的代码
{
// 子进程需要处理的任务
/* ... */
exit(0); // 结束子进程
}
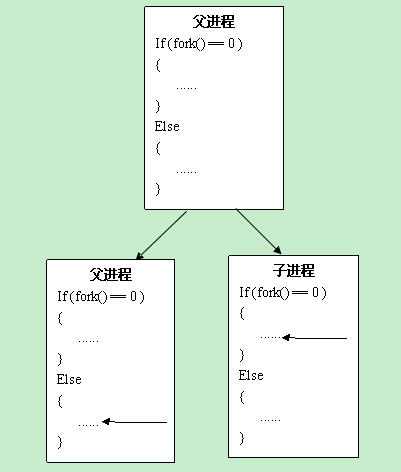
子进程具有独立的地址空间,进程调用fork()之后,系统会给子进程分配新的资源。
fork的另一个特性是所有由父进程打开的描述符(descriptor,如file,socket等)都被复制到子进程中。父、子进程中相同编号的描述符在内核中指向同一个结构体,也就是说,仅仅是描述符结构体的引用计数要增加。
在调用fork之前,只有一个进程在执行代码,但之后将会有两个进程同时执行(父子),这两个进程几乎完全相同,将要执行的下一条语句都是fork()后面的那条语句。
例如:
int main ()
{
pid_t fpid;
int count=0;
fpid=fork();
if (fpid < 0)
printf("error in fork!");
else if (fpid == 0) {
printf("i am the child process, my process id is %d/n",getpid());
printf("我是爹的儿子/n");
count++;
}
else {
printf("i am the parent process, my process id is %d/n",getpid());
printf("我是孩子他爹/n");
count++;
}
printf("统计结果是: %d/n",count);
return 0;
} 运行结果是:
i am the child process, my process id is 5574
我是爹的儿子
统计结果是: 1
i am the parent process, my process id is 5573
我是孩子他爹
统计结果是: 1

在语句 fpid=fork()之前,只有一个进程在执行这段代码,但在这条语句之后,就变成两个进程在执行了,这两个进程几乎完全相同,将要执行的下一条语句都是if(fpid<0)……
fork出错可能有两种原因:
1)当前的进程数已经达到了系统规定的上限,这时errno的值被设置为EAGAIN。
2)系统内存不足,这时errno的值被设置为ENOMEM。
创建新进程成功后,系统中出现两个基本完全相同的进程,这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略.
为什么fork不从main函数开始执行?
这致是fork的约定,fork()将进程的内存完全复制一份给子进程,所有程序的上下文和内存变量都是一致的,因此新的程序还是从fork下一句开始执行,需要根据fork的返回值判断当前是在父进程还是子进程。
fork() 子进程的terminate及僵尸(Zombie)进程的处理... ....(未完)

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









