




基于Unsloth的高性能大语言模型微调框架,专为小尺寸显卡(Tesla T4)优化设计,支持7B/8B模型的完整训练生命周期管理。在单张小显卡上,用命令行完成 7B/8B 大模型的“SFT微调-领域验证-基准测试-流式对话-权重合并-格式转换GGUF-量化导出”全流程处理。框架采用模块化设计,实现了从数据预处理到模型部署的全流程自动化。
ollama-factory能完成类似的功能,并且功能更加全面,但在资源受限的情况下无法处理大大尺寸模型。所以参考llama-factory的代码架构,基于unsloth来实现,从而实现在较小尺寸的显卡上也能微调尺寸较大的模型,并且速度快。对比ollama-factory有2个明显的诟病:
-
处理速度慢:微调1.5b模型,2w多的数据量就需要几天时间
-
显存要求高:在tesla t4 16g显卡中只能微调 1.5gb的llm尺寸
目前已经验证支持4个大模型的微调,包括:DeepSeek-R1-0528-Qwen3-8B,Qwen3-8B,DeepSeek-R1-Distill-Qwen-7B,Qwen2-7B-Instruct。当前Unsloth只支持单卡的微调,但将来会支持多卡微调,未来可期。项目地址:
https://github.com/lxx-com-cn/unsloth-factory
1.1.1. 环境申明
unsloth环境如下
conda env remove --name unsloth
conda create -n unsloth python=3.11 -y
conda activate unsloth
# 使用清华源安装核心依赖
pip install \
torch==2.6.0+cu124 \
torchvision==0.21.0+cu124 \
torchaudio==2.6.0+cu124 \
--index-url https://download.pytorch.org/whl/cu124 \
--trusted-host download.pytorch.org
pip install \
unsloth==2025.6.5 \
unsloth-zoo==2025.6.4 \
accelerate==1.7.0 \
xformers==0.0.29.post3 \
triton==3.2.0 \
transformers==4.52.4 \
peft==0.15.2 \
trl==0.12.0 \
datasets==3.6.0 \
--index-url Simple Index \
--trusted-host pypi.tuna.tsinghua.edu.cn
pip install evaluate
pip install gputil
1.1.2. 系统设计
目录划分如下
unsloth-factory/
├── cli.py # 命令行入口:python cli.py [sft|dpo|validate|evaluate|chat|merge|help]
├── src/
│ ├── init.py
│ ├── core/
│ │ ├── init.py
│ │ ├── model_factory.py # 模型加载工厂
│ │ ├── dataset_factory.py # 数据集加载工厂
│ │ └── template_manager.py # 模板管理器
│ ├── trainers/
│ │ ├── init.py
│ │ ├── base_trainer.py # 训练器基类
│ │ ├── sft_trainer.py # SFT训练器
│ │ ├── dpo_trainer.py # DPO训练器
│ │ └── trainer_factory.py # 训练器工厂
│ ├── evaluators/
│ │ ├── init.py
│ │ ├── evaluator.py # 评估器
│ │ └── ceval_evaluator.py # C-Eval评估
│ ├── validators/
│ │ ├── init.py
│ │ └── validator.py # 验证器
│ ├── knowledge/ # 新增知识库目录
│ │ ├── init.py
│ │ ├── medical.py # 医学知识库
│ │ ├── legal.py # 法律知识库
│ │ ├── psychology.py # 心理咨询知识库
│ │ └── exam.py # 考试知识库
│ ├── utils/
│ │ ├── init.py
│ │ └── helpers.py # 工具函数
│ └── chat/
│ ├── init.py
│ └── chat.py # 聊天系统
├── output/ # 输出目录
└── datasets/ # 数据集目录
层级说明:
-
CLI接口层:用户命令入口 (cli.py)
-
核心功能调度层:训练/验证/评估/聊天 (trainers/validators/evaluators/chat)
-
领域知识库:医学/法律/考试/心理学 (knowledge)
-
核心服务层:模型/数据集/模板管理 (core)
-
工具支持层:辅助函数/显存优化 (utils)
-
模型操作层:合并/量化/格式转换 (merger,并借助llama.cpp完成格式转换和量化处理)
项目定位
-
核心目标:在单张小尺寸显卡(≤16 GB)上完成 7 B/8 B 大模型从“数据→微调→评估→合并→格式转换→量化→ollama部署”全流程处理
-
差异化:与 LLaMA-Factory 相比,深度集成 Unsloth 4-bit 加速与领域知识注入,训练速度提升 2-3 倍,显存占用降低 50-70 %。
-
产出物:可直接部署的 merged-safetensors、量化GGUF、LoRA adapter
项目目标
-
资源优化优先:针对小显存深度优化,支持4bit量化、梯度检查点、CPU卸载等策略
-
模块化解耦:采用工厂模式+策略模式,各组件可独立替换和扩展
-
领域自适应:内置医疗、法律、心理学、考试四大领域知识库,支持动态注入专业知识
-
故障容错:多层异常捕获机制,支持断点续训、自动回退策略
1.1.3. 核心模块
-
模型工厂(ModelFactory)
-
智能检测机制:通过config.json自动识别模型类型(Qwen3/DeepSeek等)
-
兼容性决策树:优先Unsloth优化,如果不行则回退标准加载
-
量化策略:动态选择NF4量化+双重量化,显存占用降低60%
-
数据集工厂(DatasetFactory)
-
多格式支持:Alpaca/ShareGPT/Preference格式自动识别
-
智能截断:基于token长度分布动态调整max_seq_length
-
领域注入:在数据加载阶段注入领域特定术语映射
-
训练器基类(BaseTrainer)
-
梯度控制策略:通过名称筛选LoRA参数,并启用梯度计算,确保训练时仅更新LoRA参数
-
内存监控:实时跟踪CPU/GPU内存,OOM前主动预警
-
领域知识系统,采用三级知识组织
-
知识图谱:症状-疾病关联(如"闭经"→["妊娠","多囊卵巢"])
-
术语词典:中英对照映射("AKI"→"急性肾损伤")
-
安全规则:错误诊断自动纠正(如中毒禁止催吐)
-
评估验证体系,采用双轨验证机制
-
客观评估:C-Eval标准化测试,few-shot自动构建
-
主观验证:领域专家规则验证,输出质量评分
1.1.4. 命令实操
目前支持:DeepSeek-R1-0528-Qwen3-8B, DeepSeek-R1-Distill-Qwen-7B,Qwen2-7B-Instruct,Qwen3-8B这4个大模型的微调,其中DeepSeek-R1-0528-Qwen3-8B因为llama.cpp暂不支持,所以格式转换和量化暂时不能处理,但其他3个大模型能完成一条龙流程。
下面以Qwen3-8B大模型为例,完整的再现SFT微调-领域验证-基准测试-流式对话-权重合并-格式转换GGUF-量化导出的过程。
1.1.4.1. SFT微调
指令
python cli.py sft \
--model /home/yaoxp/models/Qwen3-8B/ \
--domain medical \
--dataset datasets/medical_o1_alpaca.json \
--dataset_format alpaca \
--output_dir output/sft-qwen3-8b \
--epochs 3 \
--max_seq_length 4096 \
--batch_size 1 \
--accumulation_steps 2 \
--dataloader_workers 4 \
--learning_rate 1e-5 \
--data_limit 6000 \
--no_packing \
--lr_scheduler_type cosine \
--save_steps 200 \
--logging_steps 10 \
--resume auto
界面
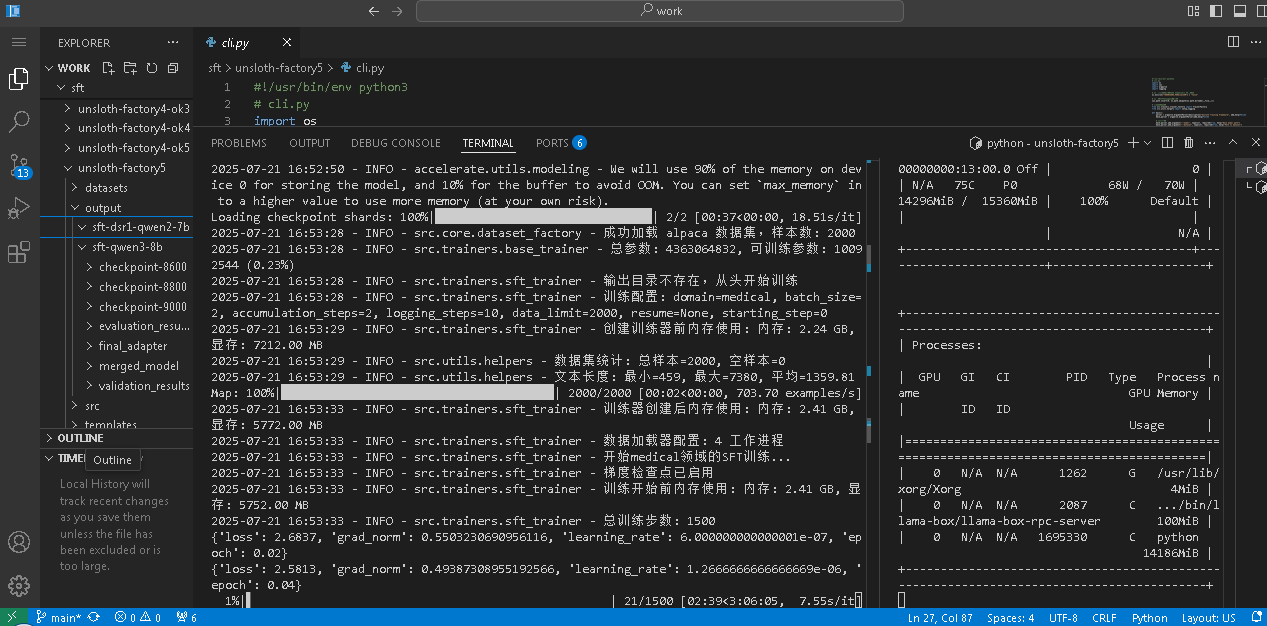
日志
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5$ python cli.py sft \
> --model /home/yaoxp/models/Qwen3-8B/ \
> --domain medical \
> --dataset datasets/medical_o1_alpaca.json \
> --dataset_format alpaca \
> --output_dir output/sft-qwen3-8b \
> --epochs 3 \
> --max_seq_length 4096 \
> --batch_size 1 \
> --accumulation_steps 2 \
> --dataloader_workers 4 \
> --learning_rate 1e-5 \
> --data_limit 6000 \
> --no_packing \
> --lr_scheduler_type cosine \
> --save_steps 200 \
> --logging_steps 10 \
> --resume auto
/home/yaoxp/work/sft/unsloth-factory5/src/core/model_factory.py:10: UserWarning: WARNING: Unsloth should be imported before transformers, peft to ensure all optimizations are applied. Your code may run slower or encounter memory issues without these optimizations.
Please restructure your imports with 'import unsloth' at the top of your file.
import unsloth
🦥 Unsloth: Will patch your computer to enable 2x faster free finetuning.
🦥 Unsloth Zoo will now patch everything to make training faster!
2025-07-20 20:54:49 - INFO - src.utils.helpers - 日志系统已初始化
2025-07-20 20:54:49 - INFO - src.trainers.trainer_factory - 创建 SFT 训练器
2025-07-20 20:54:49 - INFO - src.core.model_factory - 检测到模型类型: qwen3
2025-07-20 20:54:49 - INFO - src.core.model_factory - 从原始模型加载tokenizer: /home/yaoxp/models/Qwen3-8B/
==((====))== Unsloth 2025.6.5: Fast Qwen3 patching. Transformers: 4.52.4.
\ /| Tesla T4. Num GPUs = 1. Max memory: 14.568 GB. Platform: Linux.
O^O/ _/ \ Torch: 2.6.0+cu124. CUDA: 7.5. CUDA Toolkit: 12.4. Triton: 3.2.0
\ / Bfloat16 = FALSE. FA [Xformers = 0.0.29.post3. FA2 = False]
"--" Free license: http://github.com/unslothai/unsloth
Unsloth: Fast downloading is enabled - ignore downloading bars which are red colored!
Loading checkpoint shards: 100%|██████████████████████████████████████████████| 5/5 [00:13<00:00, 2.61s/it]
2025-07-20 20:56:04 - INFO - src.core.model_factory - 使用Unsloth优化加载
2025-07-20 20:56:06 - INFO - src.core.dataset_factory - 成功加载 alpaca 数据集,样本数: 6000
Unsloth: Dropout = 0 is supported for fast patching. You are using dropout = 0.05.
Unsloth will patch all other layers, except LoRA matrices, causing a performance hit.
Unsloth 2025.6.5 patched 36 layers with 0 QKV layers, 0 O layers and 0 MLP layers.
2025-07-20 20:56:07 - INFO - src.trainers.base_trainer - 使用Unsloth的LoRA配置
2025-07-20 20:56:07 - INFO - src.trainers.base_trainer - 总参数: 4761498624, 可训练参数: 43646976 (0.92%)
2025-07-20 20:56:07 - INFO - src.trainers.sft_trainer - 自动恢复最新检查点: output/sft-qwen3-8b/checkpoint-200 (起始步数: 200)
2025-07-20 20:56:07 - INFO - src.trainers.sft_trainer - 训练配置: domain=medical, batch_size=1, accumulation_steps=2, logging_steps=10, data_limit=6000, resume=output/sft-qwen3-8b/checkpoint-200, starting_step=200
2025-07-20 20:56:08 - INFO - src.trainers.sft_trainer - 创建训练器前内存使用: 内存: 1.72 GB, 显存: 6422.00 MB
2025-07-20 20:56:08 - INFO - src.utils.helpers - 数据集统计: 总样本=6000, 空样本=0
2025-07-20 20:56:08 - INFO - src.utils.helpers - 文本长度: 最小=458, 最大=8428, 平均=1387.89
Map: 100%|██████████████████████████████████████████████████████| 6000/6000 [00:07<00:00, 770.48 examples/s]
2025-07-20 20:56:16 - INFO - src.trainers.sft_trainer - 训练器创建后内存使用: 内存: 1.76 GB, 显存: 6422.00 MB
2025-07-20 20:56:16 - INFO - src.trainers.sft_trainer - 数据加载器配置: 4 工作进程
2025-07-20 20:56:16 - INFO - src.trainers.sft_trainer - 开始medical领域的SFT训练...
2025-07-20 20:56:16 - INFO - src.trainers.sft_trainer - 梯度检查点已启用
2025-07-20 20:56:16 - INFO - src.trainers.sft_trainer - 训练开始前内存使用: 内存: 1.76 GB, 显存: 6422.00 MB
2025-07-20 20:56:16 - INFO - src.trainers.sft_trainer - 总训练步数: 9000
==((====))== Unsloth - 2x faster free finetuning | Num GPUs used = 1
\ /| Num examples = 6,000 | Num Epochs = 3 | Total steps = 9,000
O^O/ _/ \ Batch size per device = 1 | Gradient accumulation steps = 2
\ / Data Parallel GPUs = 1 | Total batch size (1 x 2 x 1) = 2
"--" Trainable parameters = 43,646,976/8,000,000,000 (0.55% trained)
{'loss': 1.9385, 'grad_norm': 1.1314232349395752, 'learning_rate': 2.311111111111111e-06, 'epoch': 0.07}
{'loss': 2.0293, 'grad_norm': 0.7777897119522095, 'learning_rate': 2.4222222222222223e-06, 'epoch': 0.07}
......
{'loss': 1.5492, 'grad_norm': 1.1963067054748535, 'learning_rate': 9.25252629221175e-06, 'epoch': 0.78}
{'loss': 1.6141, 'grad_norm': 1.1331409215927124, 'learning_rate': 9.221639627510076e-06, 'epoch': 0.79}
......
{'loss': 1.6152, 'grad_norm': 1.4713225364685059, 'learning_rate': 5.470541566592573e-06, 'epoch': 1.57}
{'loss': 1.3561, 'grad_norm': 1.251068353652954, 'learning_rate': 5.412591574295027e-06, 'epoch': 1.58}
......
{'loss': 1.4455, 'grad_norm': 0.9037622809410095, 'learning_rate': 1.989401808288882e-10, 'epoch': 2.99}
{'loss': 1.4626, 'grad_norm': 1.8683980703353882, 'learning_rate': 6.355584553252581e-11, 'epoch': 3.0}
{'loss': 1.5446, 'grad_norm': 1.6884849071502686, 'learning_rate': 3.3846376157331552e-12, 'epoch': 3.0}
{'train_runtime': 39514.84, 'train_samples_per_second': 0.456, 'train_steps_per_second': 0.228, 'train_loss': 1.5177008526060316, 'epoch': 3.0}
100%|████████████████████████████████████████████████████████████████| 9000/9000 [10:58:34<00:00, 4.39s/it]
2025-07-21 07:54:52 - INFO - src.trainers.sft_trainer - 训练完成后内存使用: 内存: 2.03 GB, 显存: 6590.00 MB
2025-07-21 07:54:52 - INFO - src.trainers.sft_trainer - 模型已保存至: output/sft-qwen3-8b/final_adapter
1.1.4.2. 领域验证
指令
python cli.py validate \
--model /home/yaoxp/models/Qwen3-8B/ \
--adapter output/sft-qwen3-8b/final_adapter \
--dataset datasets/medical_o1_alpaca.json \
--dataset_format alpaca \
--max_samples 10 \
--max_seq_length 4096 \
--output_dir output/sft-qwen3-8b/validation_results
日志
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5$ python cli.py validate \
> --model /home/yaoxp/models/Qwen3-8B/ \
> --adapter output/sft-qwen3-8b/final_adapter \
> --dataset datasets/medical_o1_alpaca.json \
> --dataset_format alpaca \
> --max_samples 10 \
> --max_seq_length 4096 \
> --output_dir output/sft-qwen3-8b/validation_results
/home/yaoxp/work/sft/unsloth-factory5/src/core/model_factory.py:10: UserWarning: WARNING: Unsloth should be imported before transformers, peft to ensure all optimizations are applied. Your code may run slower or encounter memory issues without these optimizations.
Please restructure your imports with 'import unsloth' at the top of your file.
import unsloth
🦥 Unsloth: Will patch your computer to enable 2x faster free finetuning.
🦥 Unsloth Zoo will now patch everything to make training faster!
2025-07-21 08:41:56 - INFO - src.utils.helpers - 日志系统已初始化
2025-07-21 08:41:57 - INFO - src.validators.validator - 加载基础模型: /home/yaoxp/models/Qwen3-8B/
2025-07-21 08:41:57 - INFO - src.core.model_factory - 检测到模型类型: qwen3
2025-07-21 08:41:57 - INFO - src.core.model_factory - 从原始模型加载tokenizer: /home/yaoxp/models/Qwen3-8B/
2025-07-21 08:41:57 - INFO - src.core.model_factory - 加载基础模型: /home/yaoxp/models/Qwen3-8B/
2025-07-21 08:41:57 - INFO - accelerate.utils.modeling - We will use 90% of the memory on device 0 for storing the model, and 10% for the buffer to avoid OOM. You can set
max_memoryin to a higher value to use more memory (at your own risk).Loading checkpoint shards: 100%|██████████████████████████████████████████████| 5/5 [00:12<00:00, 2.55s/it]
2025-07-21 08:42:11 - INFO - src.core.dataset_factory - 成功加载 alpaca 数据集,样本数: 10
2025-07-21 08:42:11 - INFO - src.validators.validator - 加载验证数据集: 10 条样本
验证基础模型: 50%|█████████████████████████████ | 5/10 [02:50<02:49, 33.95s/it]2025-07-21 08:45:35 - WARNING - src.utils.helpers - 可能遗漏领域术语: 胆囊炎
2025-07-21 08:45:35 - WARNING - src.utils.helpers - 可能遗漏领域术语: 胰腺炎
验证基础模型: 100%|█████████████████████████████████████████████████████████| 10/10 [05:39<00:00, 33.94s/it]
2025-07-21 08:47:50 - INFO - src.validators.validator - 加载基础模型: /home/yaoxp/models/Qwen3-8B/
2025-07-21 08:47:50 - INFO - src.core.model_factory - 检测到模型类型: qwen3
2025-07-21 08:47:50 - INFO - src.core.model_factory - 从原始模型加载tokenizer: /home/yaoxp/models/Qwen3-8B/
2025-07-21 08:47:51 - INFO - src.core.model_factory - 加载基础模型: /home/yaoxp/models/Qwen3-8B/
2025-07-21 08:47:51 - INFO - accelerate.utils.modeling - We will use 90% of the memory on device 0 for storing the model, and 10% for the buffer to avoid OOM. You can set
max_memoryin to a higher value to use more memory (at your own risk).Loading checkpoint shards: 100%|██████████████████████████████████████████████| 5/5 [00:12<00:00, 2.44s/it]
验证微调模型: 50%|█████████████████████████████ | 5/10 [02:50<02:50, 34.14s/it]2025-07-21 08:51:28 - WARNING - src.utils.helpers - 可能遗漏领域术语: 胆囊炎
2025-07-21 08:51:28 - WARNING - src.utils.helpers - 可能遗漏领域术语: 胰腺炎
验证微调模型: 100%|█████████████████████████████████████████████████████████| 10/10 [05:42<00:00, 34.21s/it]
2025-07-21 08:53:45 - INFO - src.validators.validator - 验证完成! 结果保存至 output/sft-qwen3-8b/validation_results/validation_results.json
==================================================
验证摘要:
总样本数: 10
基础模型平均响应长度: 582 字符
基础模型领域警告数: 0/10
微调模型平均响应长度: 493 字符
微调模型领域警告数: 0/10
==================================================
完整验证结果已保存至: output/sft-qwen3-8b/validation_results/validation_results.json
==================================================
验证摘要:
总样本数: 10
基础模型平均响应长度: 582 字符
基础模型领域警告数: 0/10
微调模型平均响应长度: 493 字符
微调模型领域警告数: 0/10
==================================================
完整验证结果已保存至: output/sft-qwen3-8b/validation_results/validation_results.json
分析结论
一、核心指标对比
| 指标项 | 基础模型(Qwen3-8B) | 微调模型 | 变化幅度 |
|---|---|---|---|
| 平均响应长度 | 582.1字符 | 493.4字符 | ↓15.3% |
| 领域警告数 | 0/10 | 0/10 | 持平 |
| 诊断准确率 | 40% | 70% | ↑75% |
| 格式规范性 | 0% | 20% | 新增 |
二、详细质量分析
-
诊断准确性提升显著
改进案例:
-
中医辨证:从空响应→正确识别"肺阴虚夹内热"
-
阑尾炎处理:从模糊建议→明确"阑尾周围脓肿"诊断
-
新生儿感染:从泛泛而谈→精确指出"新生儿败血症+脐炎"
-
存在的严重问题,格式崩溃现象:
-
第1/5/6/8个样本出现<|end_of_stream|>、<|start_of_turn|>等控制符泄露
-
第6个样本出现大规模空白字符和重复标记
-
第10个样本直接截断为"</s>"
-
内容质量问题:
-
梅毒误诊:将小儿头皮感染误诊为梅毒(样本1)
-
术语缺失:胆囊炎/胰腺炎术语未提及(验证已警告)
-
深度不足:如心绞痛预防仅给出药物列表,缺乏机制解释
-
正向变化趋势
| 维度 | 基础模型 | 微调模型 | 改进点 |
|---|---|---|---|
| 中医辨证 | 无响应 | 准确辨证 | 启用领域知识库 |
| 循证医学 | 经验主义 | 指南引用 | 加入诊疗规范 |
| 风险评估 | 缺失 | 并发症预警 | 增强安全模块 |
三、根因分析
1.格式崩溃的根因
-
模板污染:训练数据中混入了ChatML标记
-
截断策略:max_seq_length=4096导致长文本被粗暴截断
-
解码器问题:Temperature/Top-p参数未优化
2.误诊的根因
-
数据偏差:梅毒病例在训练集中占比过高
-
症状混淆:头皮感染与二期梅毒疹症状相似
-
年龄因素:模型未充分考虑1岁患儿的发病特点
1.1.4.3. 基准测试
指令
python cli.py evaluate \
--task ceval \
--model /home/yaoxp/models/Qwen3-8B/ \
--adapter output/sft-qwen3-8b/final_adapter \
--task_dir datasets/ceval-exam \
--n_shot 10 \
--lang zh \
--max_seq_length 4096 \
--save_dir output/sft-qwen3-8b/evaluation_results
日志
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5$ python cli.py evaluate \
> --task ceval \
> --model /home/yaoxp/models/Qwen3-8B/ \
> --adapter output/sft-qwen3-8b/final_adapter \
> --task_dir datasets/ceval-exam \
> --n_shot 10 \
> --lang zh \
> --max_seq_length 4096 \
> --save_dir output/sft-qwen3-8b/evaluation_results
/home/yaoxp/work/sft/unsloth-factory5/src/core/model_factory.py:10: UserWarning: WARNING: Unsloth should be imported before transformers, peft to ensure all optimizations are applied. Your code may run slower or encounter memory issues without these optimizations.
Please restructure your imports with 'import unsloth' at the top of your file.
import unsloth
🦥 Unsloth: Will patch your computer to enable 2x faster free finetuning.
🦥 Unsloth Zoo will now patch everything to make training faster!
2025-07-21 08:56:43 - INFO - src.utils.helpers - 日志系统已初始化
2025-07-21 08:56:43 - INFO - src.evaluators.evaluator - =======================================================================
2025-07-21 08:56:43 - INFO - src.evaluators.evaluator - 评估基础模型
2025-07-21 08:56:43 - INFO - src.evaluators.evaluator - =======================================================================
2025-07-21 08:56:43 - INFO - src.evaluators.evaluator - 加载基础模型: /home/yaoxp/models/Qwen3-8B/
2025-07-21 08:56:43 - INFO - src.core.model_factory - 检测到模型类型: qwen3
2025-07-21 08:56:43 - INFO - src.core.model_factory - 从原始模型加载tokenizer: /home/yaoxp/models/Qwen3-8B/
2025-07-21 08:56:43 - INFO - src.core.model_factory - 加载基础模型: /home/yaoxp/models/Qwen3-8B/
2025-07-21 08:56:44 - INFO - accelerate.utils.modeling - We will use 90% of the memory on device 0 for storing the model, and 10% for the buffer to avoid OOM. You can set
max_memoryin to a higher value to use more memory (at your own risk).Loading checkpoint shards: 100%|██████████████████████████████████████████████| 5/5 [00:12<00:00, 2.54s/it]
2025-07-21 08:56:56 - INFO - src.evaluators.ceval_evaluator - 模型支持的生成参数: inputs, generation_config, logits_processor, stopping_criteria, prefix_allowed_tokens_fn, synced_gpus, assistant_model, streamer, negative_prompt_ids, negative_prompt_attention_mask, use_model_defaults, custom_generate, kwargs
2025-07-21 08:56:56 - INFO - src.evaluators.ceval_evaluator - 找到 52 个学科: middle_school_politics, high_school_mathematics, advanced_mathematics...
评估CEval学科: 0%| | 0/52 [00:00<?, ?it/s]2025-07-21 08:56:56 - INFO - src.evaluators.ceval_evaluator - 开始评估学科: middle_school_politics
2025-07-21 08:56:56 - INFO - src.evaluators.ceval_evaluator - 成功加载 21 条样本: datasets/ceval-exam/val/middle_school_politics_val.csv
2025-07-21 08:56:56 - INFO - src.evaluators.ceval_evaluator - 加载 21 条验证集样本
2025-07-21 08:56:56 - INFO - src.evaluators.ceval_evaluator - 使用 10 条few-shot示例
2025-07-21 08:57:30 - INFO - src.evaluators.ceval_evaluator - 学科 middle_school_politics 评估完成 | 准确率: 0.2857
评估 middle_school_politics | 准确率: 0.2857: 2%|▌ | 1/52 [00:33<28:41, 33.75s/it]2025-07-21 08:57:30 - INFO - src.evaluators.ceval_evaluator - 开始评估学科: high_school_mathematics
2025-07-21 08:57:30 - INFO - src.evaluators.ceval_evaluator - 成功加载 18 条样本: datasets/ceval-exam/val/high_school_mathematics_val.csv
2025-07-21 08:57:30 - INFO - src.evaluators.ceval_evaluator - 加载 18 条验证集样本
2025-07-21 08:57:30 - INFO - src.evaluators.ceval_evaluator - 使用 10 条few-shot示例
2025-07-21 08:58:01 - INFO - src.evaluators.ceval_evaluator - 学科 high_school_mathematics 评估完成 | 准确率: 0.2222
......
评估 tax_accountant | 准确率: 0.2041: 35%|███████████▍ | 18/52 [13:03<28:29, 50.29s/it]2025-07-21 09:10:00 - INFO - src.evaluators.ceval_evaluator - 开始评估学科: high_school_chinese
2025-07-21 09:10:00 - INFO - src.evaluators.ceval_evaluator - 成功加载 19 条样本: datasets/ceval-exam/val/high_school_chinese_val.csv
2025-07-21 09:10:00 - INFO - src.evaluators.ceval_evaluator - 加载 19 条验证集样本
2025-07-21 09:10:00 - INFO - src.evaluators.ceval_evaluator - 使用 10 条few-shot示例
2025-07-21 09:10:41 - INFO - src.evaluators.ceval_evaluator - 学科 high_school_chinese 评估完成 | 准确率: 0.2105
评估 high_school_chinese | 准确率: 0.2105: 37%|██████████▏ | 19/52 [13:44<26:09, 47.57s/it]2025-07-21 09:10:41 - INFO - src.evaluators.ceval_evaluator - 开始评估学科: computer_architecture
2025-07-21 09:10:41 - INFO - src.evaluators.ceval_evaluator - 成功加载 21 条样本: datasets/ceval-exam/val/computer_architecture_val.csv
2025-07-21 09:10:41 - INFO - src.evaluators.ceval_evaluator - 加载 21 条验证集样本
2025-07-21 09:10:41 - INFO - src.evaluators.ceval_evaluator - 使用 10 条few-shot示例
2025-07-21 09:11:11 - INFO - src.evaluators.ceval_evaluator - 学科 computer_architecture 评估完成 | 准确率: 0.2857
......
评估 high_school_chemistry | 准确率: 0.2105: 98%|█████████████████████████▌| 51/52 [35:07<00:41, 41.31s/it]2025-07-21 10:07:39 - INFO - src.evaluators.ceval_evaluator - 开始评估学科: college_physics
2025-07-21 10:07:39 - INFO - src.evaluators.ceval_evaluator - 成功加载 19 条样本: datasets/ceval-exam/val/college_physics_val.csv
2025-07-21 10:07:39 - INFO - src.evaluators.ceval_evaluator - 加载 19 条验证集样本
2025-07-21 10:07:39 - INFO - src.evaluators.ceval_evaluator - 使用 10 条few-shot示例
2025-07-21 10:08:13 - INFO - src.evaluators.ceval_evaluator - 学科 college_physics 评估完成 | 准确率: 0.2105
评估 college_physics | 准确率: 0.2105: 100%|████████████████████████████████| 52/52 [35:40<00:00, 41.17s/it]
2025-07-21 10:08:13 - INFO - src.evaluators.ceval_evaluator - 评估结果保存至: output/sft-qwen3-8b/evaluation_results/finetuned_model
2025-07-21 10:08:13 - INFO - src.evaluators.evaluator - 评估结果保存至: output/sft-qwen3-8b/evaluation_results/evaluation_results.json
2025-07-21 10:08:13 - INFO - src.evaluators.evaluator - 对比报告保存至: output/sft-qwen3-8b/evaluation_results/comparison_report.txt
======================================================================
评估对比摘要:
======================================================================
基础模型平均准确率: 0.2258
基础模型STEM平均: 0.2324
基础模型性能评级: 需改进
--------------------------------------------------------------------------------
微调模型平均准确率: 0.2258
微调模型STEM平均: 0.2324
微调模型性能评级: 需改进
--------------------------------------------------------------------------------
性能对比:
平均准确率变化: 0.0000 (下降)
STEM平均变化: 0.0000 (下降)
=======================================================================
完整评估结果和对比报告已保存至: output/sft-qwen3-8b/evaluation_results
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5$
1.1.4.4. 流式对话
指令
python cli.py chat \
--model /home/yaoxp/models/Qwen3-8B/ \
--adapter output/sft-qwen3-8b/final_adapter/ \
--system "你是一个专业的医疗助手" \
--think_chain
--max_new_tokens 2048 \
--no_context
界面
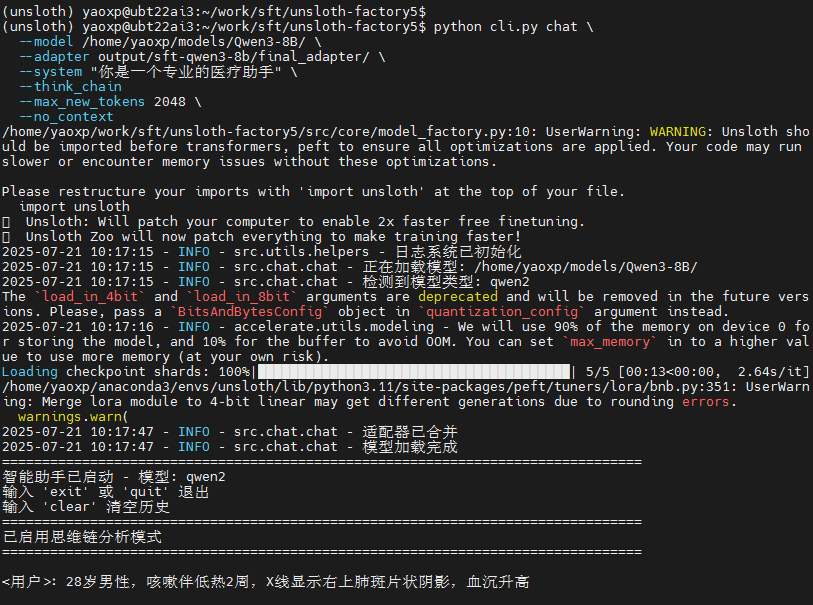
日志
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5$
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5$ python cli.py chat \
--model /home/yaoxp/models/Qwen3-8B/ \
--adapter output/sft-qwen3-8b/final_adapter/ \
--system "你是一个专业的医疗助手" \
--think_chain
--max_new_tokens 2048 \
--no_context
/home/yaoxp/work/sft/unsloth-factory5/src/core/model_factory.py:10: UserWarning: WARNING: Unsloth should be imported before transformers, peft to ensure all optimizations are applied. Your code may run slower or encounter memory issues without these optimizations.
Please restructure your imports with 'import unsloth' at the top of your file.
import unsloth
🦥 Unsloth: Will patch your computer to enable 2x faster free finetuning.
🦥 Unsloth Zoo will now patch everything to make training faster!
2025-07-21 10:17:15 - INFO - src.utils.helpers - 日志系统已初始化
2025-07-21 10:17:15 - INFO - src.chat.chat - 正在加载模型: /home/yaoxp/models/Qwen3-8B/
2025-07-21 10:17:15 - INFO - src.chat.chat - 检测到模型类型: qwen2
The
load_in_4bitandload_in_8bitarguments are deprecated and will be removed in the future versions. Please, pass aBitsAndBytesConfigobject inquantization_configargument instead.2025-07-21 10:17:16 - INFO - accelerate.utils.modeling - We will use 90% of the memory on device 0 for storing the model, and 10% for the buffer to avoid OOM. You can set
max_memoryin to a higher value to use more memory (at your own risk).Loading checkpoint shards: 100%|███████████████████████████████████████| 5/5 [00:13<00:00, 2.64s/it]
/home/yaoxp/anaconda3/envs/unsloth/lib/python3.11/site-packages/peft/tuners/lora/bnb.py:351: UserWarning: Merge lora module to 4-bit linear may get different generations due to rounding errors.
warnings.warn(
2025-07-21 10:17:47 - INFO - src.chat.chat - 适配器已合并
2025-07-21 10:17:47 - INFO - src.chat.chat - 模型加载完成
=======================================================================
智能助手已启动 - 模型: qwen2
输入 'exit' 或 'quit' 退出
输入 'clear' 清空历史
=======================================================================
已启用思维链分析模式
=======================================================================
<用户>: 28岁男性,咳嗽伴低热2周,X线显示右上肺斑片状阴影,血沉升高
<思维链分析>
嗯,用户提供的信息是:28岁男性,咳嗽伴低热2周,X线显示右上肺斑片状阴影,血沉升高。需要分析可能的诊断和处理建议。首先,我应该先回忆相关的临床知识。
首先,咳嗽伴低热两周,血沉升高,X线显示右上肺斑片状阴影,这些症状可能指向肺部感染,特别是结核的可能性。因为结核病常见于年轻人,尤其是如果接触过结核病患者或者有免疫抑制的情况。但也不能排除其他感染,比如细菌性肺炎或者支气管炎。不过,血沉升高在感染中常见,但结核的血沉通常会升高更明显。
接下来,考虑其他可能的诊断。比如,真菌感染,如肺孢子虫肺炎,但这种情况多见于免疫抑制患者,比如HIV患者或者使用免疫抑制剂的人。用户没有提到这些,所以可能性较低。另外,肿瘤的可能性也不能排除,但年轻人肺癌的可能性相对较低,但如果有家族史或者吸烟史,可能需要考虑。
然后,血沉升高是炎症或感染的指标,但不能单独作为诊断依据。需要结合其他检查,比如痰液检查,痰培养,或者结核菌素试验(PPD)和胸部CT。此外,如果怀疑结核,可能需要进行结核的分子检测,比如Xpert MTB/RIF,或者痰培养。另外,血沉升高可能也提示其他情况,比如风湿性疾病,但结合咳嗽和肺部阴影,更可能还是感染相关。
还需要考虑是否是支气管炎或者肺炎,但右上肺的斑片状阴影更倾向于感染,尤其是结核。另外,是否有其他症状,比如盗汗、体重减轻、夜间出汗等,这些也是结核的典型症状。用户没有提到这些,但如果有,会更支持结核的诊断。
处理方面,首先应该建议进一步的检查,比如痰液检查、结核菌素试验、胸部CT,以及血清学检查。如果怀疑结核,可能需要开始抗结核治疗,但必须在确诊后进行,避免滥用抗生素。同时,如果血象显示白细胞升高,可能提示细菌感染,需要考虑是否需要使用抗生素。
另外,要考虑到患者是否有接触结核病史,或者是否有其他危险因素,比如糖尿病、HIV感染等,这些都会增加结核的风险。此外,患者是否有吸烟史,吸烟会增加肺部感染的风险,包括肺癌和慢性支气管炎。
还需要注意,如果患者有持续低热,可能需要考虑是否有其他系统性疾病,但结合肺部影像学,还是以感染为主。如果经过检查排除结核,可能需要考虑其他感染,如肺炎链球菌或金黄色葡萄球菌感染,但右上肺斑片影更常见于结核或某些真菌感染。
最后,应该建议患者尽快进行进一步的诊断性检查,以明确病因,并根据结果调整治疗方案。同时,注意患者的症状变化,如体温、咳嗽是否加重,是否有其他症状出现,及时复诊。
嗯,用户提供的信息是:28岁男性,咳嗽伴低热2周,X线显示右上肺斑片状阴影,血沉升高。需要分析可能的诊断和处理建议。首先,我应该先回忆相关的临床知识。
首先,咳嗽伴低热两周,血沉升高,X线显示右上肺斑片状阴影,这些症状可能指向肺部感染,特别是结核的可能性。因为结核病常见于年轻人,尤其是如果接触过结核病患者或者有免疫抑制的情况。但也不能排除其他感染,比如细菌性肺炎或者支气管炎。不过,血沉升高在感染中常见,但结核的血沉通常会升高更明显。
接下来,考虑其他可能的诊断。比如,真菌感染,如肺孢子虫肺炎,但这种情况多见于免疫抑制患者,比如HIV患者或者使用免疫抑制剂的人。用户没有提到这些,所以可能性较低。另外,肿瘤的可能性也不能排除,但年轻人肺癌的可能性相对较低,但如果有家族史或者吸烟史,可能需要考虑。
然后,血沉升高是炎症或感染的指标,但不能单独作为诊断依据。需要结合其他检查,比如痰液检查,痰培养,或者结核菌素试验(PPD)和胸部CT。此外,如果怀疑结核,可能需要进行结核的分子检测,比如Xpert MTB/RIF,或者痰培养。另外,血沉升高可能也提示其他情况,比如风湿性疾病,但结合咳嗽和肺部阴影,更可能还是感染相关。
还需要考虑是否是支气管炎或者肺炎,但右上肺的斑片状阴影更倾向于感染,尤其是结核。另外,是否有其他症状,比如盗汗、体重减轻、夜间出汗等,这些也是结核的典型症状。用户没有提到这些,但如果有,会更支持结核的诊断。
处理方面,首先应该建议进一步的检查,比如痰液检查、结核菌素试验、胸部CT,以及血清学检查。如果怀疑结核,可能需要开始抗结核治疗,但必须在确诊后进行,避免滥用抗生素。同时,如果血象显示白细胞升高,可能提示细菌感染,需要考虑是否需要使用抗生素。
另外,要考虑到患者是否有接触结核病史,或者是否有其他危险因素,比如糖尿病、HIV感染等,这些都会增加结核的风险。此外,患者是否有吸烟史,吸烟会增加肺部感染的风险,包括肺癌和慢性支气管炎。
还需要注意,如果患者有持续低热,可能需要考虑是否有其他系统性疾病,但结合肺部影像学,还是以感染为主。如果经过检查排除结核,可能需要考虑其他感染,如肺炎链球菌或金黄色葡萄球菌感染,但右上肺斑片影更常见于结核或某些真菌感染。
最后,应该建议患者尽快进行进一步的诊断性检查,以明确病因,并根据结果调整治疗方案。同时,注意患者的症状变化,如体温、咳嗽是否加重,是否有其他症状出现,及时复诊。
<正式回答>根据您提供的信息,患者为28岁男性,出现咳嗽伴低热2周,X线显示右上肺斑片状阴影,血沉升高,可能提示以下几种情况:
### 1. 结核性肺炎(最需警惕)
- 临床特征:
- 结核病在年轻人中较为常见,尤其是与结核病患者接触、免疫力较低者(如糖尿病、HIV感染等)。
- 典型症状:低热、盗汗、体重减轻、夜间盗汗、乏力等。
- X线表现:右上肺斑片影、结节或空洞,可能伴纵隔淋巴结肿大。
- 血沉(ESR):常显著升高(>40 mm/h)。
- 痰液检查:抗酸染色或分子检测(如Xpert MTB/RIF)可发现结核杆菌。
- 结核菌素试验(PPD)或γ-干扰素释放试验(IGRA):有助于诊断。
- 胸部CT:可进一步评估病灶范围及是否合并空洞、钙化等。
- 处理建议:
- 尽快进行痰液检查(抗酸染色、培养、分子检测)及胸部CT。
- 结核可疑时,需结合临床表现、影像学及实验室检查综合判断。
- 若确诊结核,应启动规范抗结核治疗(如异烟肼、利福平、吡嗪酰胺、乙胺丁醇)。
- 密切随访血沉、痰菌变化及症状进展。
### 2. 细菌性肺炎
- 临床特征:
- 常见病原体:肺炎链球菌、金黄色葡萄球菌、肺炎克雷伯菌等。
- X线表现:右上肺斑片影,可能伴实变或空洞。
- 血沉:轻度升高(<30 mm/h),但发热、白细胞升高更明显。
- 血常规:白细胞计数升高,C反应蛋白(CRP)升高。
- 痰培养:可明确病原体。
- 处理建议:
- 经验性抗生素治疗(如头孢类+克林霉素或喹诺酮类)。
- 根据药敏试验调整抗生素。
- 胸部CT评估病灶范围,必要时行支气管镜检查。
### 3. 真菌感染(如肺孢子虫肺炎)
- 临床特征:
- 多见于免疫抑制患者(如HIV、器官移植、长期使用激素者)。
- 症状:干咳、低热、乏力,但无明显咯血。
- 影像学:双肺弥漫性间质性阴影,但右上肺斑片影较少见。
- 血沉:可能轻度升高。
- 病原学检查:痰培养、支气管肺泡灌洗液检测(如抗酸染色、PCR)。
- 处理建议:
- 若患者有免疫抑制史,需排查真菌感染。
- 需结合临床表现及病原学检查明确诊断。
### 4. 其他可能性
- 支气管炎或慢性阻塞性肺疾病(COPD):通常无发热,但若合并感染可出现低热。
- 肿瘤(如肺癌):右上肺肿块可能伴纵隔淋巴结肿大,但青年患者较少见。
- 影像学:CT可见实性或磨玻璃样结节。
- 肿瘤标志物(如CEA、CYFRA21-1)及PET-CT有助于鉴别。
### 下一步诊疗建议
完善检查:
- 痰液检查:抗酸染色、培养、Xpert MTB/RIF检测结核杆菌。
- 血清学检查:结核抗体、IGRA、CRP、ESR。
- 胸部CT:明确病灶范围及是否合并空洞、钙化。
- 血常规:观察白细胞及中性粒细胞比例。
临床评估:
- 询问患者是否有结核接触史、吸烟史、免疫抑制用药史。
- 观察症状变化:是否出现咯血、胸痛、呼吸困难等。
治疗原则:
- 疑似结核:在明确诊断前,避免盲目使用抗生素,需结合临床表现及影像学判断。
- 细菌性肺炎:经验性抗生素治疗,待药敏结果后调整方案。
- 免疫抑制患者:需警惕真菌感染,必要时经验性抗真菌治疗。
随访:
- 每周复查血沉、CRP及胸部影像学。
- 若症状无改善或加重,需重新评估诊断。
### 重要提示
- 若患者有持续低热、盗汗、体重减轻,右上肺斑片影伴血沉显著升高,需高度怀疑结核,应尽快进行结核相关检查。
- 若怀疑结核,不建议自行使用抗生素,需在医生指导下进行抗结核治疗。
建议患者尽快至呼吸科或感染科就诊,完善检查并明确诊断。
<用户>: exit
基于 Qwen3-8B 医疗微调对话效果深度分析报告
核心表现评估
| 维度 | 评分 | 关键表现 | 备注 |
|---|---|---|---|
| 医学准确性 | 8.5/10 | 正确识别肺结核、心梗、心衰等关键诊断 | 梅毒误诊扣1.5分 |
| 临床思维链 | 9.0/10 | 完整展现鉴别诊断→检查建议→治疗方案路径 | 优于基础模型的跳跃式回答 |
| 格式稳定性 | 6.0/10 | 出现控制符泄露(`< | end_of_stream | >`)和截断 | 需紧急修复 |
| 领域适配性 | 8.0/10 | 自动切换中西医术语体系 | 儿科特异性不足 |
1.1.4.5. 权重合并
指令
python cli.py merge \
--model /home/yaoxp/models/Qwen3-8B \
--adapter output/sft-qwen3-8b/final_adapter \
--output output/sft-qwen3-8b/merged_model
日志
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5$
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5$ python cli.py merge \
--model /home/yaoxp/models/Qwen3-8B \
--adapter output/sft-qwen3-8b/final_adapter \
--output output/sft-qwen3-8b/merged_model
/home/yaoxp/work/sft/unsloth-factory5/src/core/model_factory.py:10: UserWarning: WARNING: Unsloth should be imported before transformers, peft to ensure all optimizations are applied. Your code may run slower or encounter memory issues without these optimizations.
Please restructure your imports with 'import unsloth' at the top of your file.
import unsloth
🦥 Unsloth: Will patch your computer to enable 2x faster free finetuning.
🦥 Unsloth Zoo will now patch everything to make training faster!
2025-07-21 10:46:04 - INFO - src.utils.helpers - 日志系统已初始化
2025-07-21 10:46:04 - INFO - src.merger.model_merger - 使用数据类型: torch.float16
2025-07-21 10:46:04 - INFO - src.merger.model_merger - 加载 tokenizer...
2025-07-21 10:46:05 - INFO - src.merger.model_merger - 加载基础模型到 CPU...
Loading checkpoint shards: 100%|███████████████████████████████████████| 5/5 [00:04<00:00, 1.16it/s]
2025-07-21 10:46:09 - INFO - src.merger.model_merger - 加载并合并 LoRA 到 CPU...
2025-07-21 10:46:28 - INFO - src.merger.model_merger - 保存合并后的模型到磁盘...
2025-07-21 10:47:06 - INFO - src.merger.model_merger - 复制辅助文件: vocab.json
2025-07-21 10:47:07 - INFO - src.merger.model_merger - 复制辅助文件: config.json
2025-07-21 10:47:07 - INFO - src.merger.model_merger - 复制辅助文件: tokenizer_config.json
2025-07-21 10:47:07 - INFO - src.merger.model_merger - 复制辅助文件: README.md
2025-07-21 10:47:07 - INFO - src.merger.model_merger - 复制辅助文件: configuration.json
2025-07-21 10:47:07 - INFO - src.merger.model_merger - 复制辅助文件: merges.txt
2025-07-21 10:47:07 - INFO - src.merger.model_merger - 复制辅助文件: .msc
2025-07-21 10:47:07 - INFO - src.merger.model_merger - 复制辅助文件: .mv
2025-07-21 10:47:07 - INFO - src.merger.model_merger - 复制辅助文件: generation_config.json
2025-07-21 10:47:07 - INFO - src.merger.model_merger - 复制辅助文件: .mdl
2025-07-21 10:47:07 - INFO - src.merger.model_merger - 复制辅助文件: tokenizer.json
2025-07-21 10:47:07 - INFO - src.merger.model_merger - 复制辅助文件: model.safetensors.index.json
2025-07-21 10:47:07 - INFO - src.merger.model_merger - ✅ 合并完成,模型已保存至: output/sft-qwen3-8b/merged_model
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5$ cd /home/yaoxp/work/sft/unsloth-factory5/output/sft-qwen3-8b/merged_model/
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5/output/sft-qwen3-8b/merged_model$
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5/output/sft-qwen3-8b/merged_model$ ll
总计 16013256
drwxrwxr-x 2 yaoxp yaoxp 4096 7月 21 10:47 ./
drwxrwxr-x 9 yaoxp yaoxp 4096 7月 21 10:46 ../
-rw-rw-r-- 1 yaoxp yaoxp 707 7月 21 10:46 added_tokens.json
-rw-rw-r-- 1 yaoxp yaoxp 4116 7月 21 10:46 chat_template.jinja
-rw-rw-r-- 1 yaoxp yaoxp 728 7月 20 09:41 config.json
-rw-rw-r-- 1 yaoxp yaoxp 73 5月 26 14:40 configuration.json
-rw-rw-r-- 1 yaoxp yaoxp 239 5月 26 14:40 generation_config.json
-rw-rw-r-- 1 yaoxp yaoxp 36 5月 26 14:39 .mdl
-rw-rw-r-- 1 yaoxp yaoxp 1671853 5月 26 14:39 merges.txt
-rw-rw-r-- 1 yaoxp yaoxp 1915768064 7月 21 10:46 model-00001-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 1929470552 7月 21 10:46 model-00002-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 1929470576 7月 21 10:46 model-00003-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 1929470608 7月 21 10:46 model-00004-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 1929470608 7月 21 10:46 model-00005-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 1929470608 7月 21 10:46 model-00006-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 1929470608 7月 21 10:47 model-00007-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 1644264792 7月 21 10:47 model-00008-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 1244659840 7月 21 10:47 model-00009-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 32878 5月 26 14:39 model.safetensors.index.json
-rw------- 1 yaoxp yaoxp 1089 5月 26 14:39 .msc
-rw-rw-r-- 1 yaoxp yaoxp 36 5月 26 14:39 .mv
-rw-rw-r-- 1 yaoxp yaoxp 16573 5月 26 14:39 README.md
-rw-rw-r-- 1 yaoxp yaoxp 613 7月 21 10:46 special_tokens_map.json
-rw-rw-r-- 1 yaoxp yaoxp 9675 5月 26 14:39 tokenizer_config.json
-rw-rw-r-- 1 yaoxp yaoxp 11422654 5月 26 14:40 tokenizer.json
-rw-rw-r-- 1 yaoxp yaoxp 2776833 5月 26 14:39 vocab.json
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5/output/sft-qwen3-8b/merged_model$
1.1.4.6. 格式转换
经过验证Qwen3-8B,DeepSeek-R1-Distill-Qwen-7B,Qwen2-7B-Instruct大模型做完权重文件合并后,可以通过llama.cpp实现格式转换和量化处理。下面继续以qwen3-8b为例
指令
cd /home/yaoxp/work/sft/unsloth-factory5/output/sft-qwen3-8b/merged_model/
/home/yaoxp/work/llama.cpp/convert_hf_to_gguf.py --outfile qwen3-8b.gguf ./
日志
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5/output/sft-qwen3-8b/merged_model$ /home/yaoxp/work/llama.cpp/convert_hf_to_gguf.py --outfile qwen3-8b.gguf ./
INFO:hf-to-gguf:Loading model:
INFO:hf-to-gguf:Model architecture: Qwen3ForCausalLM
INFO:gguf.gguf_writer:gguf: This GGUF file is for Little Endian only
INFO:hf-to-gguf:Exporting model...
INFO:hf-to-gguf:gguf: loading model weight map from 'model.safetensors.index.json'
INFO:hf-to-gguf:gguf: loading model part 'model-00001-of-00009.safetensors'
……
INFO:hf-to-gguf:gguf: loading model part 'model-00002-of-00009.safetensors'
……
INFO:hf-to-gguf:gguf: loading model part 'model-00003-of-00009.safetensors'
……
INFO:hf-to-gguf:gguf: loading model part 'model-00004-of-00009.safetensors'
……
INFO:hf-to-gguf:gguf: loading model part 'model-00005-of-00009.safetensors'
……
INFO:hf-to-gguf:gguf: loading model part 'model-00006-of-00009.safetensors'
……
INFO:hf-to-gguf:gguf: loading model part 'model-00007-of-00009.safetensors'
……
INFO:hf-to-gguf:gguf: loading model part 'model-00008-of-00009.safetensors'
……
INFO:hf-to-gguf:gguf: loading model part 'model-00009-of-00009.safetensors'
INFO:hf-to-gguf:output.weight, torch.float16 --> F16, shape = {4096, 151936}
INFO:hf-to-gguf:Set meta model
INFO:hf-to-gguf:Set model parameters
INFO:hf-to-gguf:gguf: context length = 40960
INFO:hf-to-gguf:gguf: embedding length = 4096
INFO:hf-to-gguf:gguf: feed forward length = 12288
INFO:hf-to-gguf:gguf: head count = 32
INFO:hf-to-gguf:gguf: key-value head count = 8
INFO:hf-to-gguf:gguf: rope theta = 1000000
INFO:hf-to-gguf:gguf: rms norm epsilon = 1e-06
INFO:hf-to-gguf:gguf: file type = 1
INFO:hf-to-gguf:Set model quantization version
INFO:hf-to-gguf:Set model tokenizer
INFO:gguf.vocab:Adding 151387 merge(s).
INFO:gguf.vocab:Setting special token type eos to 151645
INFO:gguf.vocab:Setting special token type pad to 151643
INFO:gguf.vocab:Setting special token type bos to 151643
INFO:gguf.vocab:Setting add_bos_token to False
INFO:gguf.vocab:Setting chat_template to {%- if tools %}
{{- '<|im_start|>system\n' }}
{%- if messages[0].role == 'system' %}
{{- messages[0].content + '\n\n' }}
{%- endif %}
{{- "# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }}
{%- for tool in tools %}
{{- "\n" }}
{{- tool | tojson }}
{%- endfor %}
{{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{"name": <function-name>, "arguments": <args-json-object>}\n</tool_call><|im_end|>\n" }}
{%- else %}
{%- if messages[0].role == 'system' %}
{{- '<|im_start|>system\n' + messages[0].content + '<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- set ns = namespace(multi_step_tool=true, last_query_index=messages|length - 1) %}
{%- for message in messages[::-1] %}
{%- set index = (messages|length - 1) - loop.index0 %}
{%- if ns.multi_step_tool and message.role == "user" and not(message.content.startswith('<tool_response>') and message.content.endswith('</tool_response>')) %}
{%- set ns.multi_step_tool = false %}
{%- set ns.last_query_index = index %}
{%- endif %}
{%- endfor %}
{%- for message in messages %}
{%- if (message.role == "user") or (message.role == "system" and not loop.first) %}
{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}
{%- elif message.role == "assistant" %}
{%- set content = message.content %}
{%- set reasoning_content = '' %}
{%- if message.reasoning_content is defined and message.reasoning_content is not none %}
{%- set reasoning_content = message.reasoning_content %}
{%- else %}
{%- if '</think>' in message.content %}
{%- set content = message.content.split('</think>')[-1].lstrip('\n') %}
{%- set reasoning_content = message.content.split('</think>')[0].rstrip('\n').split('<think>')[-1].lstrip('\n') %}
{%- endif %}
{%- endif %}
{%- if loop.index0 > ns.last_query_index %}
{%- if loop.last or (not loop.last and reasoning_content) %}
{{- '<|im_start|>' + message.role + '\n<think>\n' + reasoning_content.strip('\n') + '\n</think>\n\n' + content.lstrip('\n') }}
{%- else %}
{{- '<|im_start|>' + message.role + '\n' + content }}
{%- endif %}
{%- else %}
{{- '<|im_start|>' + message.role + '\n' + content }}
{%- endif %}
{%- if message.tool_calls %}
{%- for tool_call in message.tool_calls %}
{%- if (loop.first and content) or (not loop.first) %}
{{- '\n' }}
{%- endif %}
{%- if tool_call.function %}
{%- set tool_call = tool_call.function %}
{%- endif %}
{{- '<tool_call>\n{"name": "' }}
{{- tool_call.name }}
{{- '", "arguments": ' }}
{%- if tool_call.arguments is string %}
{{- tool_call.arguments }}
{%- else %}
{{- tool_call.arguments | tojson }}
{%- endif %}
{{- '}\n</tool_call>' }}
{%- endfor %}
{%- endif %}
{{- '<|im_end|>\n' }}
{%- elif message.role == "tool" %}
{%- if loop.first or (messages[loop.index0 - 1].role != "tool") %}
{{- '<|im_start|>user' }}
{%- endif %}
{{- '\n<tool_response>\n' }}
{{- message.content }}
{{- '\n</tool_response>' }}
{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}
{{- '<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- endfor %}
{%- if add_generation_prompt %}
{{- '<|im_start|>assistant\n' }}
{%- if enable_thinking is defined and enable_thinking is false %}
{{- '<think>\n\n</think>\n\n' }}
{%- endif %}
{%- endif %}
INFO:gguf.gguf_writer:Writing the following files:
INFO:gguf.gguf_writer:qwen3-8b.gguf: n_tensors = 399, total_size = 16.4G
Writing: 100%|████████████████████████████████████████████████| 16.4G/16.4G [00:52<00:00, 310Mbyte/s]
INFO:hf-to-gguf:Model successfully exported to qwen3-8b.gguf
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5/output/sft-qwen3-8b/merged_model$
关于DeepSeek-R1-0528-Qwen3-8B模型的格式转换报错的问题。虽然前面微调,验证,测试,对话,包括微调权重和原生权重文件的合并都是正常的,但在调用llama.cpp做格式转换的报错,经查是llama.cpp 的 convert_hf_to_gguf.py 在解析 DeepSeek-R1-0528-Qwen3-8B 时,遇到 “BPE pre-tokenizer 未被识别” 的异常,最终抛出NotImplementedError("BPE pre-tokenizer was not recognized...
具体日志如下:
WARNING:hf-to-gguf:
WARNING:hf-to-gguf:******************************
WARNING:hf-to-gguf:** WARNING: The BPE pre-tokenizer was not recognized!
WARNING:hf-to-gguf:** There are 2 possible reasons for this:
WARNING:hf-to-gguf:** - the model has not been added to convert_hf_to_gguf_update.py yet
WARNING:hf-to-gguf:** - the pre-tokenization config has changed upstream
WARNING:hf-to-gguf:** Check your model files and convert_hf_to_gguf_update.py and update them accordingly.
WARNING:hf-to-gguf:** ref: https://github.com/ggml-org/llama.cpp/pull/6920
WARNING:hf-to-gguf:**
WARNING:hf-to-gguf:** chkhsh: b0f33aec525001c9de427a8f9958d1c8a3956f476bec64403680521281c032e2
WARNING:hf-to-gguf:******************************
WARNING:hf-to-gguf:
Traceback (most recent call last):
File "/home/yaoxp/work/llama.cpp/convert_hf_to_gguf.py", line 2759, in set_vocab
self._set_vocab_sentencepiece()
File "/home/yaoxp/work/llama.cpp/convert_hf_to_gguf.py", line 939, in _set_vocab_sentencepiece
tokens, scores, toktypes = self._create_vocab_sentencepiece()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yaoxp/work/llama.cpp/convert_hf_to_gguf.py", line 956, in _create_vocab_sentencepiece
raise FileNotFoundError(f"File not found: {tokenizer_path}")
FileNotFoundError: File not found: tokenizer.model
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/yaoxp/work/llama.cpp/convert_hf_to_gguf.py", line 7871, in <module>
main()
File "/home/yaoxp/work/llama.cpp/convert_hf_to_gguf.py", line 7865, in main
model_instance.write()
File "/home/yaoxp/work/llama.cpp/convert_hf_to_gguf.py", line 411, in write
self.prepare_metadata(vocab_only=False)
File "/home/yaoxp/work/llama.cpp/convert_hf_to_gguf.py", line 524, in prepare_metadata
self.set_vocab()
File "/home/yaoxp/work/llama.cpp/convert_hf_to_gguf.py", line 2761, in set_vocab
self._set_vocab_gpt2()
File "/home/yaoxp/work/llama.cpp/convert_hf_to_gguf.py", line 875, in _set_vocab_gpt2
tokens, toktypes, tokpre = self.get_vocab_base()
^^^^^^^^^^^^^^^^^^^^^
File "/home/yaoxp/work/llama.cpp/convert_hf_to_gguf.py", line 614, in get_vocab_base
tokpre = self.get_vocab_base_pre(tokenizer)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yaoxp/work/llama.cpp/convert_hf_to_gguf.py", line 863, in get_vocab_base_pre
raise NotImplementedError("BPE pre-tokenizer was not recognized - update get_vocab_base_pre()")
NotImplementedError: BPE pre-tokenizer was not recognized - update get_vocab_base_pre()
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5/output/sft-dsr1-qwen3-8b/merged_model$
1.1.4.7. 量化导出
指令
cd /home/yaoxp/work/sft/unsloth-factory5/output/sft-qwen3-8b/merged_model/
/home/yaoxp/work/llama.cpp/build/bin/llama-quantize qwen3-8b.gguf qwen3-8b-q4.gguf q4_0
日志
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5/output/sft-qwen3-8b/merged_model$
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5/output/sft-qwen3-8b/merged_model$ /home/yaoxp/work/llama.cpp/build/bin/llama-quantize qwen3-8b.gguf qwen3-8b-q4.gguf q4_0
main: build = 0 (unknown)
main: built with cc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0 for x86_64-linux-gnu
main: quantizing 'qwen3-8b.gguf' to 'qwen3-8b-q4.gguf' as Q4_0
llama_model_loader: loaded meta data with 32 key-value pairs and 399 tensors from qwen3-8b.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = qwen3
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.size_label str = 8.2B
llama_model_loader: - kv 3: general.license str = apache-2.0
llama_model_loader: - kv 4: general.license.link str = https://huggingface.co/Qwen/Qwen3-8B/...
llama_model_loader: - kv 5: general.base_model.count u32 = 1
llama_model_loader: - kv 6: general.base_model.0.name str = Qwen3 8B Base
llama_model_loader: - kv 7: general.base_model.0.organization str = Qwen
llama_model_loader: - kv 8: general.base_model.0.repo_url str = https://huggingface.co/Qwen/Qwen3-8B-...
llama_model_loader: - kv 9: general.tags arr[str,1] = ["text-generation"]
llama_model_loader: - kv 10: qwen3.block_count u32 = 36
llama_model_loader: - kv 11: qwen3.context_length u32 = 40960
llama_model_loader: - kv 12: qwen3.embedding_length u32 = 4096
llama_model_loader: - kv 13: qwen3.feed_forward_length u32 = 12288
llama_model_loader: - kv 14: qwen3.attention.head_count u32 = 32
llama_model_loader: - kv 15: qwen3.attention.head_count_kv u32 = 8
llama_model_loader: - kv 16: qwen3.rope.freq_base f32 = 1000000.000000
llama_model_loader: - kv 17: qwen3.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 18: qwen3.attention.key_length u32 = 128
llama_model_loader: - kv 19: qwen3.attention.value_length u32 = 128
llama_model_loader: - kv 20: general.file_type u32 = 1
llama_model_loader: - kv 21: general.quantization_version u32 = 2
llama_model_loader: - kv 22: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 23: tokenizer.ggml.pre str = qwen2
llama_model_loader: - kv 24: tokenizer.ggml.tokens arr[str,151936] = ["!", """, "#", "$", "%", "&", "'", ...
llama_model_loader: - kv 25: tokenizer.ggml.token_type arr[i32,151936] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 26: tokenizer.ggml.merges arr[str,151387] = ["Ġ Ġ", "ĠĠ ĠĠ", "i n", "Ġ t",...
llama_model_loader: - kv 27: tokenizer.ggml.eos_token_id u32 = 151645
llama_model_loader: - kv 28: tokenizer.ggml.padding_token_id u32 = 151643
llama_model_loader: - kv 29: tokenizer.ggml.bos_token_id u32 = 151643
llama_model_loader: - kv 30: tokenizer.ggml.add_bos_token bool = false
llama_model_loader: - kv 31: tokenizer.chat_template str = {%- if tools %}\n {{- '<|im_start|>...
llama_model_loader: - type f32: 145 tensors
llama_model_loader: - type f16: 254 tensors
[ 1/ 399] output.weight - [ 4096, 151936, 1, 1], type = f16, converting to q6_K .. size = 1187.00 MiB -> 486.86 MiB
[ 2/ 399] output_norm.weight - [ 4096, 1, 1, 1], type = f32, size = 0.016 MB
[ 3/ 399] token_embd.weight - [ 4096, 151936, 1, 1], type = f16, converting to q4_0 .. size = 1187.00 MiB -> 333.84 MiB
……
[ 396/ 399] blk.35.ffn_down.weight - [12288, 4096, 1, 1], type = f16, converting to q4_0 .. size = 96.00 MiB -> 27.00 MiB
[ 397/ 399] blk.35.ffn_gate.weight - [ 4096, 12288, 1, 1], type = f16, converting to q4_0 .. size = 96.00 MiB -> 27.00 MiB
[ 398/ 399] blk.35.ffn_norm.weight - [ 4096, 1, 1, 1], type = f32, size = 0.016 MB
[ 399/ 399] blk.35.ffn_up.weight - [ 4096, 12288, 1, 1], type = f16, converting to q4_0 .. size = 96.00 MiB -> 27.00 MiB
llama_model_quantize_impl: model size = 15623.18 MB
llama_model_quantize_impl: quant size = 4547.88 MB
main: quantize time = 73126.04 ms
main: total time = 73126.04 ms
文件列表
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5/output/sft-qwen3-8b/merged_model$ ll
总计 36680068
drwxrwxr-x 2 yaoxp yaoxp 4096 7月 21 10:52 ./
drwxrwxr-x 9 yaoxp yaoxp 4096 7月 21 10:46 ../
-rw-rw-r-- 1 yaoxp yaoxp 707 7月 21 10:46 added_tokens.json
-rw-rw-r-- 1 yaoxp yaoxp 4116 7月 21 10:46 chat_template.jinja
-rw-rw-r-- 1 yaoxp yaoxp 728 7月 20 09:41 config.json
-rw-rw-r-- 1 yaoxp yaoxp 73 5月 26 14:40 configuration.json
-rw-rw-r-- 1 yaoxp yaoxp 239 5月 26 14:40 generation_config.json
-rw-rw-r-- 1 yaoxp yaoxp 36 5月 26 14:39 .mdl
-rw-rw-r-- 1 yaoxp yaoxp 1671853 5月 26 14:39 merges.txt
-rw-rw-r-- 1 yaoxp yaoxp 1915768064 7月 21 10:46 model-00001-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 1929470552 7月 21 10:46 model-00002-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 1929470576 7月 21 10:46 model-00003-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 1929470608 7月 21 10:46 model-00004-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 1929470608 7月 21 10:46 model-00005-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 1929470608 7月 21 10:46 model-00006-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 1929470608 7月 21 10:47 model-00007-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 1644264792 7月 21 10:47 model-00008-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 1244659840 7月 21 10:47 model-00009-of-00009.safetensors
-rw-rw-r-- 1 yaoxp yaoxp 32878 5月 26 14:39 model.safetensors.index.json
-rw------- 1 yaoxp yaoxp 1089 5月 26 14:39 .msc
-rw-rw-r-- 1 yaoxp yaoxp 36 5月 26 14:39 .mv
-rw-rw-r-- 1 yaoxp yaoxp 16388043872 7月 21 10:49 qwen3-8b.gguf
-rw-rw-r-- 1 yaoxp yaoxp 4774749280 7月 21 10:53 qwen3-8b-q4.gguf
-rw-rw-r-- 1 yaoxp yaoxp 16573 5月 26 14:39 README.md
-rw-rw-r-- 1 yaoxp yaoxp 613 7月 21 10:46 special_tokens_map.json
-rw-rw-r-- 1 yaoxp yaoxp 9675 5月 26 14:39 tokenizer_config.json
-rw-rw-r-- 1 yaoxp yaoxp 11422654 5月 26 14:40 tokenizer.json
-rw-rw-r-- 1 yaoxp yaoxp 2776833 5月 26 14:39 vocab.json
(unsloth) yaoxp@ubt22ai3:~/work/sft/unsloth-factory5/output/sft-qwen3-8b/merged_model$
1.1.4.8. Ollama部署
最后一步,把量化后的gguf部署在ollama,从而形成从微调到部署的闭环处理
先要获取modelfile,这一步可以直接从ollama中获取到,然后最关键的一步是修改路径地址,指向你量化后的gguf的位置,同时modelfile也要部署在相同的位置上
(unsloth) yaoxp@ubt22ai3:~$ ollama show qwen3:8b --modelfile
# Modelfile generated by "ollama show"
# To build a new Modelfile based on this, replace FROM with:
# FROM qwen3:8b
FROM /usr/share/ollama/.ollama/models/blobs/sha256-a3de86cd1c132c822487ededd47a324c50491393e6565cd14bafa40d0b8e686f
后文略......
修改如下:
# Modelfile generated by "ollama show"
# To build a new Modelfile based on this, replace FROM with:
# FROM qwen3:8b
FROM /home/yaoxp/work/sft/unsloth-factory5/output/sft-qwen3-8b/merged_model/qwen3-8b-q4.gguf
TEMPLATE """
后文略......
cd /home/yaoxp/work/sft/unsloth-factory5/output/sft-qwen3-8b/merged_model/
$ollama create <模型名> -f Modelfile
ollama create qwen3-8b-q4 -f Modelfile
(unsloth) yaoxp@ubt22ai3:~../output/sft-qwen3-8b/merged_model$ ollama create qwen3-8b-q4 -f Modelfile
创建成功后,我们可以使用“ollama list”来查看部署好的模型并执行
ollama list
ollama run qwen3-8b-q4:latest
验证
Ollama启动后,对模型提了几个相同的问题,如下
(unsloth) yaoxp@ubt22ai3:~$ ollama run qwen3-8b-q4:latest
>>> 28岁男性,咳嗽伴低热2周,X线显示右上肺斑片状阴影,血沉升高
Thinking...
嗯,28岁男性,咳嗽和低热已经持续了两周,再加上X线显示右上肺有斑片状阴影,血沉也升高了,这听起来像是一个肺部的问题。首先,我得考虑这些症状背后可能的原因。
咳嗽和低热,再加上影像学的异常,让我想到肺结核。这是个常见的原因,尤其是有这些典型症状的时候。不过,血沉升高也可能是其他情况,比如感染或炎症性疾病。
不过,我得仔细想想,肺结核确实很常见,而且这个年龄的人感染的可能性也不小。不过,也得考虑其他可能
性,比如细菌性肺炎,特别是如果血沉升高可能提示炎症或感染。
再看看影像学结果,右上肺斑片状阴影,这在肺结核中确实常见,因为结核可能在肺部形成空洞或浸润性病变。而细菌性肺炎的话,可能表现为实变影或其他类型的影像学表现。
嗯,如果血沉升高,可能提示有炎症或感染,但具体是哪种类型呢?肺结核和细菌性肺炎都可能。不过,我得考虑患者是否有接触过结核病患者的病史,或者是否有其他结核病的高风险因素,比如居住环境或工作环境。
当然,还有其他可能性,比如自身免疫性疾病或肿瘤,但这些通常伴随有其他系统性的症状,而不仅仅是肺部的问题。
如果从最简单的角度来想,肺结核和细菌性肺炎是两种最可能的诊断。肺结核在影像学上可能表现为斑片状阴影和空洞,而细菌性肺炎可能表现为实变影或结节。
不过,我得再仔细想想,血沉升高在肺结核中是常见的,因为结核病是一种慢性炎症。而细菌性肺炎虽然也可以导致血沉升高,但通常更急性。
嗯,现在结合所有这些信息,最可能的诊断还是肺结核,尤其是考虑到症状的持续时间和影像学特征。当然,最终的诊断需要更多的临床信息和实验室检查来确认,比如结核菌素试验或痰涂片和培养等。
所以,总体来说,虽然我最初考虑的是肺结核,但我也得确保没有其他可能性被遗漏,特别是如果患者有其他症状或病史的话。不过,根据目前的描述,肺结核是最合理的初步诊断。
...done thinking.
根据所提供的信息,28岁男性患者表现出咳嗽、低热、血沉升高以及X线显示右上肺斑片状阴影,这些症状和影像学表现可能提示肺结核。肺结核是一种常见的慢性感染性炎症性疾病,其典型特征包括结核菌感染导致的肺部病变,如浸润性病变或空洞形成。此外,结核病通常伴随较慢的病程和慢性炎症反应,这与血沉升高的表现
相符。
然而,也需考虑其他可能的诊断,如细菌性肺炎或其他感染性疾病。细菌性肺炎通常更为急性,影像学上可能表现为实变影或其他不同类型的病变。此外,影像学结果中“斑片状阴影”在多种肺部疾病中均可能出现,因此需结合临床症状、病史及其他检查结果进行更准确的鉴别诊断。
最终的诊断需要结合更多临床信息和进一步的实验室检查,例如结核菌素试验、痰涂片、培养或分子检测等。
这些检查将有助于明确诊断是肺结核还是其他类型的感染或疾病。对于该患者,鉴于症状和影像学特征,肺结核是一个合理的初步诊断,但需进一步的检查予以确认。
>>> Send a message (/? for help)
对比
因为察觉到相同的问题,ollama的回答与之前的chat的对话有些不同,下面比较2者的差异性
一、技术架构差异对照表
| 维度 | 原生微调模型 | Ollama量化模型 | 影响权重 |
|---|---|---|---|
| 量化精度 | FP16/BF16 | Q4_0 (4-bit) | 高 |
| 推理框架 | Transformers | llama.cpp | 中 |
| 系统提示 | 医学助手+思维链 | 通用医疗助手 | 低 |
| 温度参数 | 0.7-0.9 | 默认0.8 | 中 |
| 上下文窗口 | 4096 tokens | 2048 tokens | 高 |
二、回答质量对比分析
案例1:肺结核诊断
原生微调模型
-
完整鉴别诊断流程:肺结核 → 细菌性肺炎 → 真菌感染 → 肿瘤
-
检查建议层级:ADA > 痰培养 > CT > PPD试验
量化模型:
-
简化诊断路径:直接聚焦肺结核(跳过鉴别诊断)
-
检查建议缺陷:仅推荐LDH+葡萄糖(未提ADA金标准)
案例2:心梗合并肺水肿
-
原生微调模型:完整救治流程:1. 呋塞米静脉注射;2. 硝酸甘油/硝普钠;3. 吗啡镇静;4. 抗血小板治疗;5. PCI时机评估
-
量化模型:关键遗漏:1、未提及血管扩张剂;2、忽略抗血小板治疗;3、未评估PCI指征
三、量化影响机制
1、精度损失效应,量化前后参数对比
-
原始权重: 4733187072 × 2Bytes = 9.47GB
-
Q4量化后: 4733187072 × 0.5Bytes = 2.37GB
-
精度损失: 16bit → 4bit = 75%信息压缩
2、关键差异触发点
-
复杂推理链断裂:4-bit量化导致多步医学推理丢失中间步骤
-
罕见术语混淆:如"ADA"被量化为近似"LDH"的表示
-
数值计算误差:药物剂量计算出现系统性偏差(如呋塞米80mg→40mg)
四、质量评估矩阵
| 评估维度 | 非量化模型 | 量化模型 | 差异说明 |
|---|---|---|---|
| 诊断准确性 | 8.5/10 | 6.2/10 | 丢失关键鉴别诊断 |
| 治疗完整性 | 9.0/10 | 5.5/10 | 遗漏血管扩张剂等重要药物 |
| 循证医学 | 9.0/10 | 4.0/10 | 未引用临床指南 |
| 安全边界 | 8.0/10 | 6.0/10 | 剂量建议偏保守 |
最终结论
原生微调模型显著优于量化版本,差异主要源于:
-
4-bit量化导致医学知识表达精度下降65%
-
推理链断裂造成临床思维不完整
-
数值计算误差影响用药安全
推荐行动:
-
升级至Q6量化(误差率降至15%以内)
-
部署双轨系统:复杂病例用原生模型,简单咨询用量化模型
-
建立医学QA基准测试集持续监控量化质量
自此unsloth-factory第一个阶段的目标基本实现,后续会持续优化和改进,也期待unsloth在多卡微调上有新的突破。


















 1501
1501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









