




笔者近期上了国科大周晓飞老师《强化学习及其应用》课程,计划整理一个强化学习系列笔记。笔记中所引用的内容部分出自周老师的课程PPT。笔记中如有不到之处,敬请批评指正。
文章目录
1.1 概述
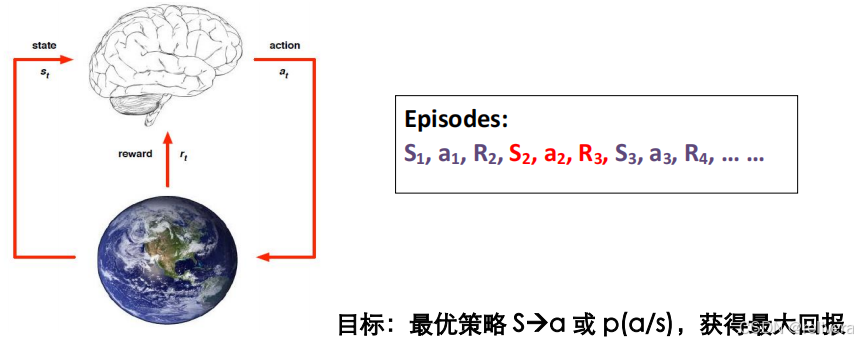
强化学习:通过与环境互动,获取环境反馈的样本;回报(作为监督),进行最优决策的机器学习。
强化学习的过程可以用下图进行描述:在状态S1下选择动作a1,获取回报R1的同时跳转到状态S2;在状态S2下选择动作a2,获取回报R2的同时跳转到状态S3……如此循环下去。
强化学习的目标就是:对于给定的状态S,我们能选一个比较好的动作a,使得回报最大。
1.2 Markov决策过程
1.2.1 Markov Process (MP) 马尔科夫过程
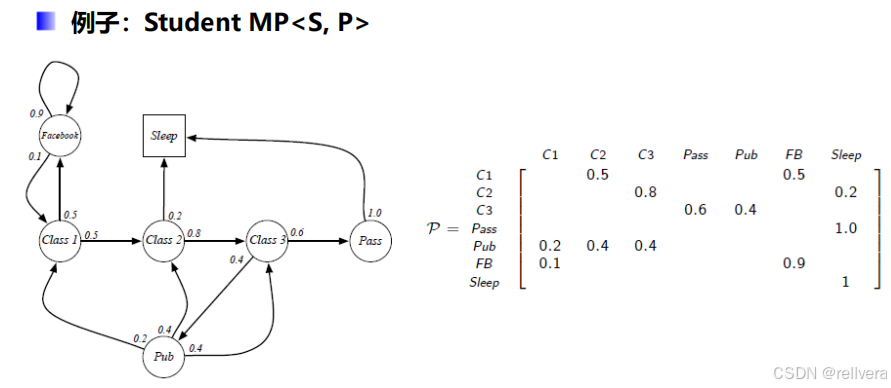
一个马尔科夫过程是一个元组<S,P>,其中S表示一个有限的状态集合,P表示一个状态转移矩阵。
比如:下图矩阵P中的P1n表示,t时刻状态为n的情况下,t+1时刻转移到状态1的概率。矩阵P中的第一行表示从状态1转移出去的概率,最后一行表示从状态n转移出去的概率,所以矩阵中每一行的和都是1。

这是Markov过程的一个例子:
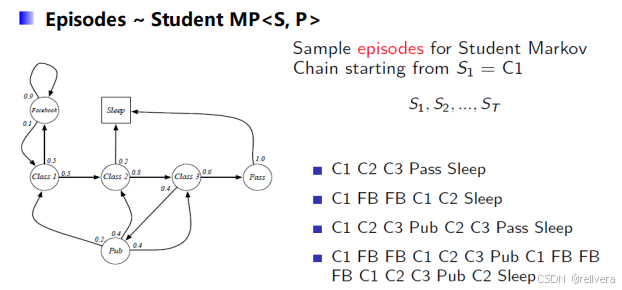
在这个例子中,假设初始状态为C1(即class1),进行4次采样,可以得到4个采样结果:
1.2.2 Markov Reward Process (MRP) 马尔科夫回报过程
马尔科夫回报过程也是一个元组 < S , P , R , γ > <S,P,R,\gamma> <S,P,R,γ>,相比于马尔科夫过程MP,MRP多了 R R R和 γ \gamma γ。其中, R R R表示在给定状态 s s s的情况下,未来回报的期望。 γ \gamma γ则是折扣因子。

那么,该怎么计算回报呢?假设当前时间为 t t t,要计算从时间 t t t开始获得的奖励 G t G_t Gt。最直接的方法是计算 G t = R t + 1 + R t + 2 + R t + 3 . . . . . . G_t=R_{t+1}+R_{t+2}+R_{t+3}...... Gt=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









