




 小白接到任务去除文档中不必要的换行符,起初误删所有换行,后经程序员小明指导,利用正则表达式分两种情况解决了问题:1. 查找句号、感叹号、引号后直接跟换行符的,替换为这两个字符;2. 查找非句号、感叹号、引号字符后的多个换行符,只保留该字符。
小白接到任务去除文档中不必要的换行符,起初误删所有换行,后经程序员小明指导,利用正则表达式分两种情况解决了问题:1. 查找句号、感叹号、引号后直接跟换行符的,替换为这两个字符;2. 查找非句号、感叹号、引号字符后的多个换行符,只保留该字符。
没有云山雾罩的技术名词,没有讳莫如深的互联网黑话;关注本专栏,IT技术不再深不可攀,技术细节小白也能读懂!
这天上班不久,小白正在划水摸鱼。忽然接到了老板电话。
老板:“小白啊,有个从网上下载的文档,不知怎的,一段还没结束就换行了,你把这些换行问题上午解决了发给小刘,下午我需要!!”
不就是去除换行符嘛,小菜一碟。
小白打开文档,果然问题如老板所说。部分内容如下所示:

这似乎难不倒小白,他轻车熟路地打开Notepad++,选择菜单【搜索】->【替换…】,打开【替换】对话框。
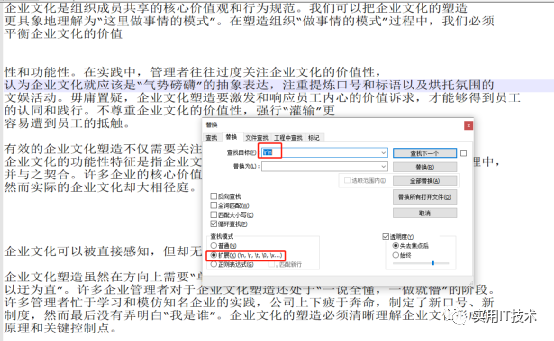
小白作为”百度资深专家“,知道换行符是特殊字符,用“\r\n”来代替,还需要打开【查找模式】下的【扩展】选项。
在【查找目标】处填入“\r\n”,【替换为】处什么都不填,然后点击【全部替换】,顺利搞定,发给小刘,继续摸鱼… …

正当小白摸鱼进入佳境的时候,美女小刘阴着脸过来了!
小刘:“小白,你发的文档把所有行都删了,整个文档只有一行。你也不检查一下,快要到中午了,你赶紧把这问题解决一下。”
听了小刘的话,小白惊出一身冷汗。对啊,光顾着删除无用的换行符,结果将有用的换行符一并删除了。
怎么办呢,百度了十多分钟,小白脑袋里还是一堆浆糊。算了,一行一行改吧,可是当看到原始文档有9万多行的时候,小白绝望了!
在绝望中,小白忽
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1315
1315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









