






一、背景需求
昨天做了福字、姓名对联横批的学具。打印一张大红色A4纸做测试

我找了几个能力强的孩子描字
1.对联文字:已经考虑笔画小于15笔,他们描的勉强还行,但因为字比较小(过去是28CM竖条,现在大约19CM高),所以字迹不清晰。

2.横批文字:文字更小,老师描字都费劲,小孩描字肯定糊成一团。考虑直接做成黑色字体(顶部加动物图案,不要学号数字,因为不涉及个人的名字,横批可以自主挑选)

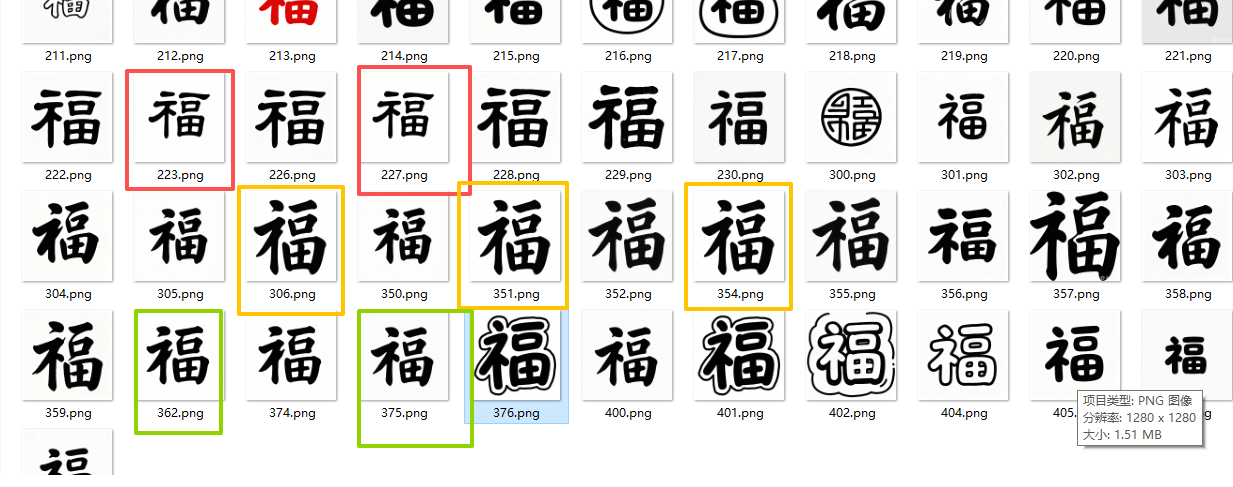
3.福字:空心福字灰色后,幼儿需要描黑线、再涂内部白色,我自己试了一下,感觉线描弯弯曲曲很难描准。再涂空心部分,幼儿根本搞不清楚。




所以必须改成实心字(黑色填充转灰色填充),这样幼儿就知道只要对灰色部分涂色,口、田部分可能会空心。
二、AI福字(实心字体)
因此用AI绘画再做实心字。


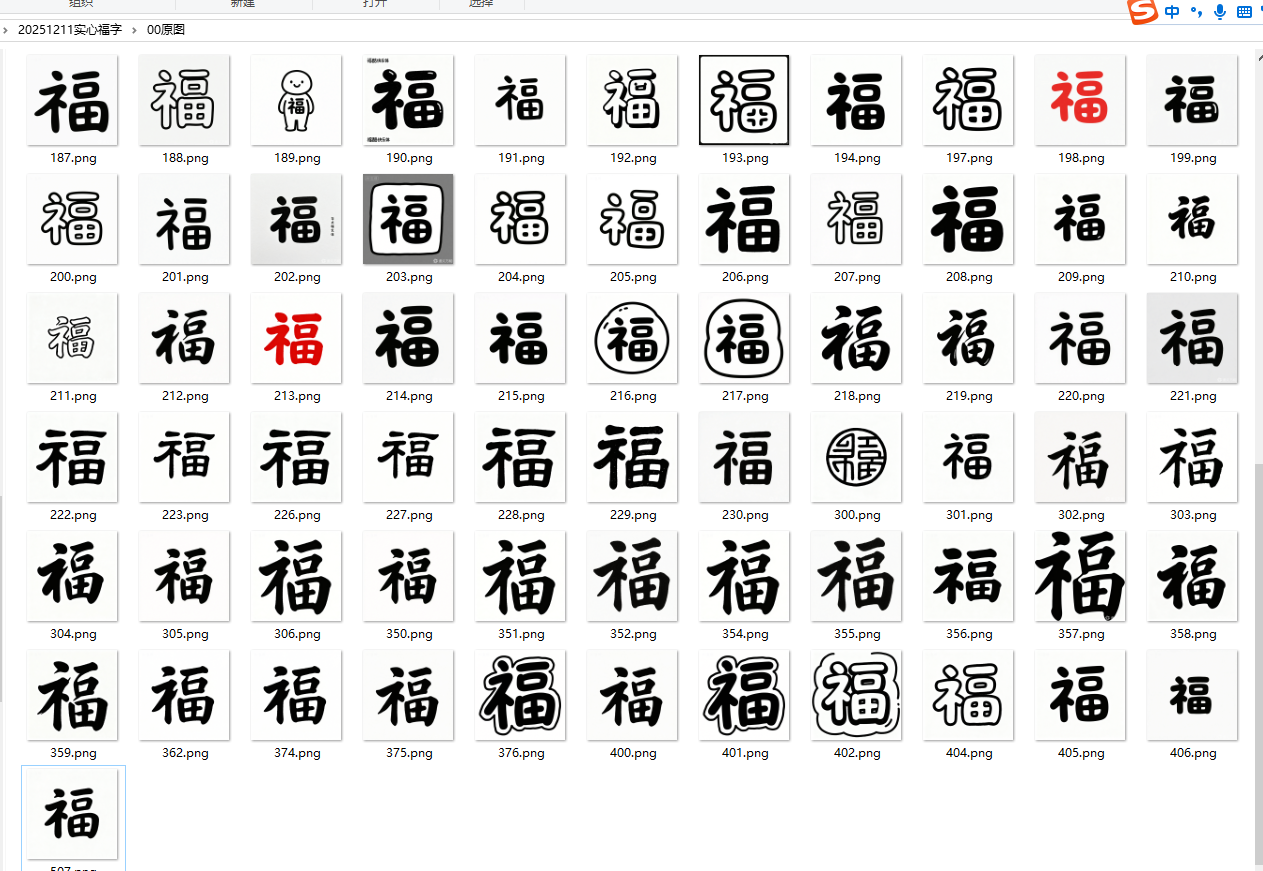
我想要更多适合幼儿感知的字体



关键词:简笔画,白色背景,汉仪乐喵体字体,福字,实心字,实心字 ,实心字,粗胖,没有颜色,正面图。

因为在网络不佳的地方下载图片,经常卡顿,我只能点前几张图片,再重复下载。
太多了

很准
'''
使用imagehash库(更精确)获取重复图片的名称
方案一:直接删除重复图片(保留第一张)
Deepseek,阿夏
20251210
'''
import os
from collections import defaultdict
from PIL import Image
import imagehash
def find_and_delete_duplicates(folder_path, hash_size=8, similarity_threshold=95, delete_files=False):
"""
查找并删除重复/相似的图片,保留每个重复组中的第一张
参数:
folder_path: 文件夹路径
hash_size: 哈希大小,越小越精确但越慢
similarity_threshold: 相似度阈值,高于此值认为是重复
delete_files: 是否真正删除文件,如果为False则只显示结果
"""
image_extensions = {'.jpg', '.jpeg', '.png', '.gif', '.bmp', '.webp', '.tiff', '.jfif'}
print(f"开始扫描文件夹: {folder_path}")
print("支持的图片格式:", ', '.join(image_extensions))
print(f"相似度阈值: {similarity_threshold}%")
print(f"删除模式: {'已启用' if delete_files else '仅预览(不删除)'}")
print("=" * 60)
# 存储图片信息
image_files = []
# 收集所有图片文件
for root, dirs, files in os.walk(folder_path):
for file in files:
file_lower = file.lower()
if any(file_lower.endswith(ext) for ext in image_extensions):
file_path = os.path.join(root, file)
image_files.append(file_path)
print(f"共找到 {len(image_files)} 张图片")
if len(image_files) == 0:
print("没有找到图片文件")
return
# 计算所有图片的哈希值
hashes = []
for i, file_path in enumerate(image_files, 1):
try:
with Image.open(file_path) as img:
# 使用phash(感知哈希),对图片的微小变化不敏感
img_hash = imagehash.phash(img, hash_size)
hashes.append((file_path, img_hash))
if i % 50 == 0 or i == len(image_files):
print(f"已处理 {i}/{len(image_files)} 张图片")
except Exception as e:
print(f"无法处理 {file_path}: {e}")
hashes.append((file_path, None))
print("\n开始比较图片相似度...")
# 查找重复图片
duplicates_groups = []
processed = set()
for i, (file1, hash1) in enumerate(hashes):
if hash1 is None or i in processed:
continue
duplicates = [file1]
for j, (file2, hash2) in enumerate(hashes[i+1:], i+1):
if hash2 is None or j in processed:
continue
# 计算相似度
hash_diff = hash1 - hash2
similarity = 100 - (hash_diff / (hash_size * hash_size) * 100)
if similarity >= similarity_threshold:
duplicates.append(file2)
processed.add(j)
if len(duplicates) > 1:
duplicates_groups.append(duplicates)
# 输出结果并处理
if not duplicates_groups:
print("\n✓ 恭喜!没有找到重复的图片")
return
total_duplicates = sum(len(group) - 1 for group in duplicates_groups)
print(f"\n⚠️ 发现 {len(duplicates_groups)} 组重复图片,共 {total_duplicates} 张重复图片")
# 统计信息
total_size_to_delete = 0
files_to_delete = []
for i, group in enumerate(duplicates_groups, 1):
print(f"\n第 {i} 组 ({len(group)} 张图片):")
# 保留第一张,删除其余的
keep_file = group[0]
delete_files_group = group[1:]
print(f" 保留: {os.path.basename(keep_file)} (大小: {os.path.getsize(keep_file)/1024:.1f} KB)")
for file_path in delete_files_group:
file_size = os.path.getsize(file_path)
total_size_to_delete += file_size
files_to_delete.append(file_path)
if delete_files:
try:
os.remove(file_path)
print(f" ✗ 已删除: {os.path.basename(file_path)} (大小: {file_size/1024:.1f} KB)")
except Exception as e:
print(f" ✗ 删除失败: {os.path.basename(file_path)} - {e}")
else:
print(f" ✗ 将删除: {os.path.basename(file_path)} (大小: {file_size/1024:.1f} KB)")
# 显示总结信息
print("\n" + "=" * 60)
print("操作总结:")
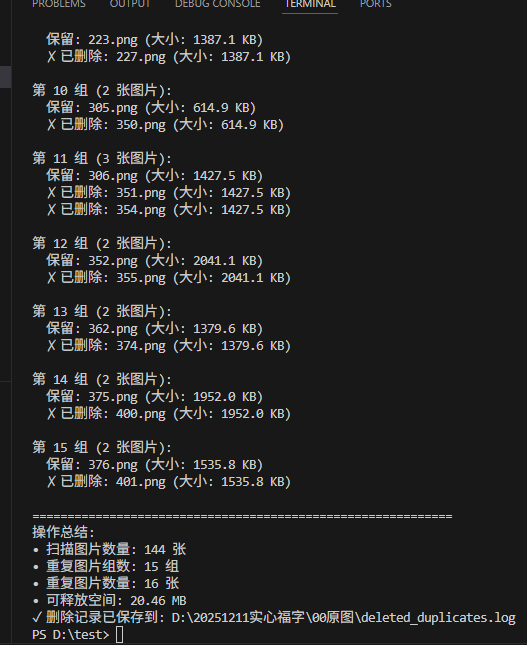
print(f"• 扫描图片数量: {len(image_files)} 张")
print(f"• 重复图片组数: {len(duplicates_groups)} 组")
print(f"• 重复图片数量: {total_duplicates} 张")
print(f"• 可释放空间: {total_size_to_delete/1024/1024:.2f} MB")
if not delete_files and files_to_delete:
print("\n⚠️ 注意:当前为预览模式,没有实际删除文件")
print("如需真正删除,请设置 delete_files=True")
# 保存删除记录(可选)
if delete_files and files_to_delete:
log_file = os.path.join(folder_path, "deleted_duplicates.log")
with open(log_file, 'w', encoding='utf-8') as f:
f.write(f"重复图片删除记录 - {os.path.basename(folder_path)}\n")
f.write(f"删除时间: {os.path.getctime(__file__)}\n")
f.write(f"共删除 {len(files_to_delete)} 张重复图片\n")
f.write(f"释放空间: {total_size_to_delete/1024/1024:.2f} MB\n\n")
f.write("删除的文件列表:\n")
for file_path in files_to_delete:
f.write(f"{file_path}\n")
print(f"✓ 删除记录已保存到: {log_file}")
# 使用示例
if __name__ == "__main__":
folder_path = r"D:\20251211实心福字\00原图" # 你的文件夹路径
# 先预览(不删除)
print("第一步:预览模式(不删除文件)")
find_and_delete_duplicates(
folder_path=folder_path,
similarity_threshold=95, # 相似度阈值,可调整
delete_files=False # 设为True才会真正删除
)
# 确认后再删除
input("\n按回车键继续查看删除选项...")
confirm = input("是否要真正删除重复图片?(输入 'yes' 确认): ")
if confirm.lower() == 'yes':
print("\n开始删除重复图片...")
find_and_delete_duplicates(
folder_path=folder_path,
similarity_threshold=95,
delete_files=True # 真正删除
)
else:
print("操作已取消")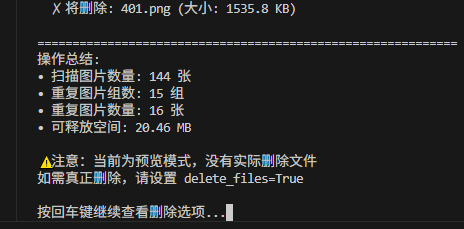
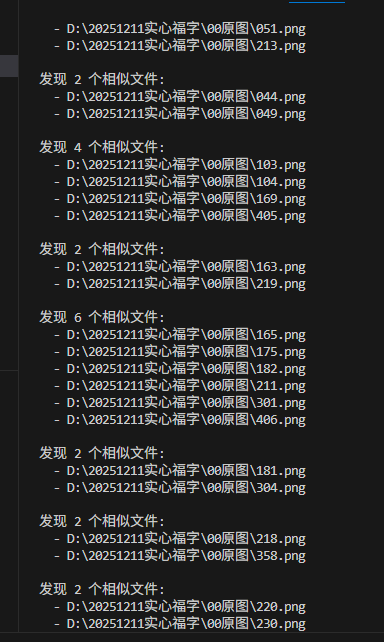
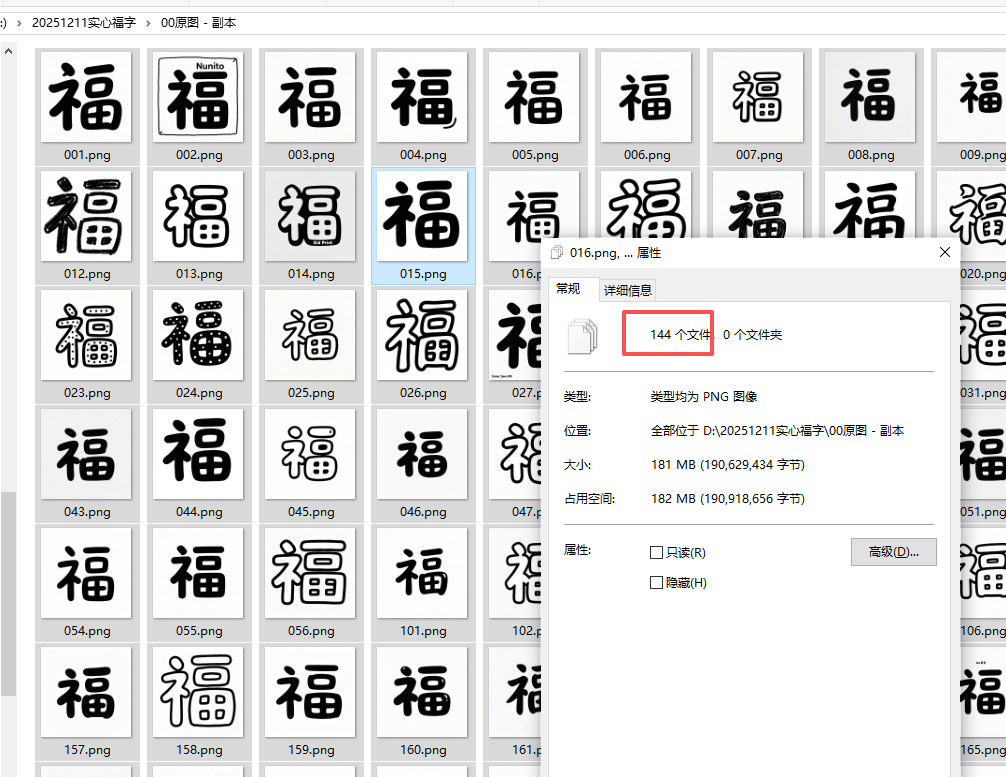
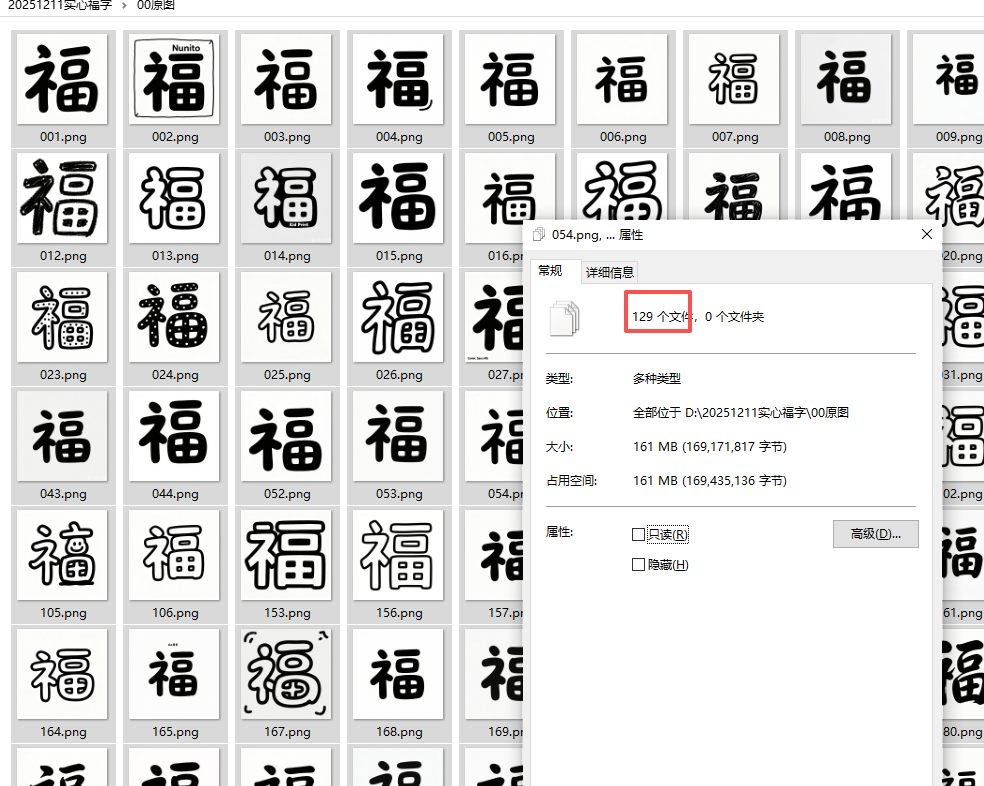
下载144张,删除重复后,保留129张
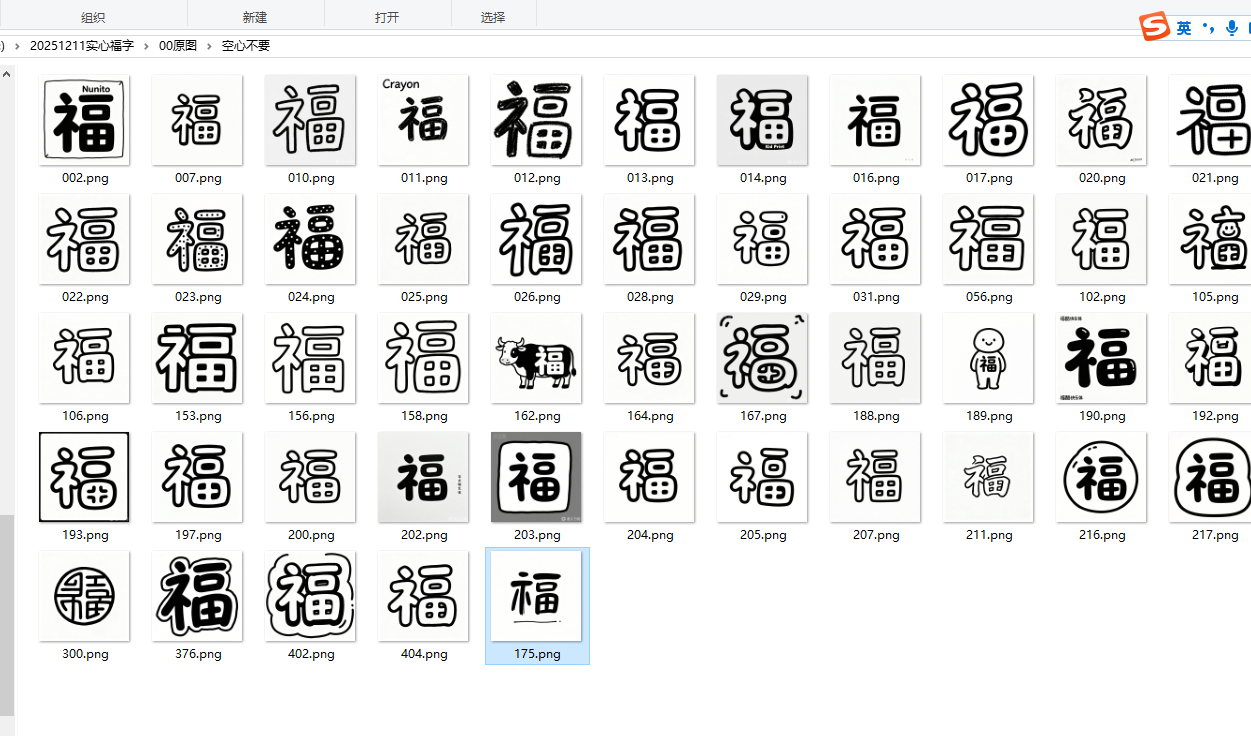
删除空心字、其他类型图片

三、福字和对联横批文字的处理
把黑色变成灰色,白色变成透明色
'''
福字黑色部分变成灰色(背景是透明色)
Deepseek,阿夏
20251210
'''
import os
from PIL import Image
# ===================== 配置参数(可根据实际需求修改) =====================
path = r'D:\20251211实心福字'
INPUT_FOLDER = path + r"\08原图切边_黑白二色_透明背景_拉伸" # 源图片文件夹路径
OUTPUT_FOLDER = path + r"\09灰色" # 处理后图片保存路径
TARGET_COLOR = (0, 0, 0, 255) # 要替换的目标颜色(RGBA格式,纯黑色且不透明)
REPLACE_COLOR = (192, 192, 192, 255) # 替换后的颜色(RGBA格式,灰色且不透明)
SUPPORTED_FORMATS = ('.jpg', '.jpeg', '.png', '.bmp', '.gif', '.tiff', '.webp') # 支持的图片格式
def process_image(img_path, output_path):
"""
处理单张图片:替换指定颜色并保存
:param img_path: 源图片路径
:param output_path: 处理后图片保存路径
"""
try:
# 打开图片并确保为RGBA模式(保留透明度)
with Image.open(img_path) as img:
# 确保图片是RGBA模式(有透明通道)
if img.mode != 'RGBA':
img = img.convert('RGBA')
# 创建一个新的透明图片作为背景
new_img = Image.new('RGBA', img.size, (0, 0, 0, 0))
pixels = img.load()
new_pixels = new_img.load()
# 获取图片宽高
width, height = img.size
# 遍历所有像素
for x in range(width):
for y in range(height):
# 获取当前像素的RGBA值
r, g, b, a = pixels[x, y]
# 判断是否为目标颜色(黑色且不透明)
if (r, g, b) == TARGET_COLOR[:3] and a == 255:
# 替换为灰色但保持透明区域不变
new_pixels[x, y] = REPLACE_COLOR
else:
# 如果不是黑色,保持原样(包括透明区域)
new_pixels[x, y] = (r, g, b, a)
# 保存处理后的图片(保持PNG格式以保留透明度)
if not output_path.lower().endswith('.png'):
output_path = os.path.splitext(output_path)[0] + '.png'
new_img.save(output_path)
print(f"✅ 处理完成:{os.path.basename(img_path)} → {os.path.basename(output_path)}")
except Exception as e:
print(f"❌ 处理失败:{os.path.basename(img_path)} | 错误:{str(e)}")
def main():
# 创建输出文件夹(不存在则创建)
os.makedirs(OUTPUT_FOLDER, exist_ok=True)
# 遍历源文件夹下的所有图片
img_files = [
f for f in os.listdir(INPUT_FOLDER)
if f.lower().endswith(SUPPORTED_FORMATS)
]
if not img_files:
print(f"⚠️ 源文件夹 {INPUT_FOLDER} 中未找到支持格式的图片!")
return
# 批量处理每张图片
for filename in img_files:
# 拼接源图片路径和输出图片路径
input_path = os.path.join(INPUT_FOLDER, filename)
# 输出文件统一使用PNG格式以保留透明度
output_filename = os.path.splitext(filename)[0] + '.png'
output_path = os.path.join(OUTPUT_FOLDER, output_filename)
# 处理图片
process_image(input_path, output_path)
print(f"\n🎉 所有图片处理完成!处理后的图片已保存至:{OUTPUT_FOLDER}")
print(f"🔧 所有输出图片已转换为PNG格式以保留透明背景")
if __name__ == "__main__":
main()

旋转45度的菱形福字贴 15CM手工纸顶格
'''
通义万相实心福字,旋转45度,缩小到0,8(无白边顶格),用于插入15CM手工纸,一页1图 13.6CNM大小
Deepseek,阿夏
20251210
'''
import os
from PIL import Image, ImageDraw
import math
def process_images(source_folder, target_folder, bg_size=1200):
"""
处理图片:旋转45度,缩小80%,贴到白色背景上
Args:
source_folder: 源图片文件夹路径
target_folder: 目标文件夹路径
bg_size: 背景图片大小(正方形)
"""
# 创建目标文件夹(如果不存在)
if not os.path.exists(target_folder):
os.makedirs(target_folder)
# 支持的图片格式
supported_formats = ('.jpg', '.jpeg', '.png', '.bmp', '.gif', '.tiff')
# 遍历源文件夹中的所有文件
for filename in os.listdir(source_folder):
# 检查是否为支持的图片格式
if filename.lower().endswith(supported_formats):
try:
# 构建完整的文件路径
source_path = os.path.join(source_folder, filename)
# 打开图片
img = Image.open 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











