




背景需求:
今天浏览电脑里所有的字体(中文、英文),有发现了一款适合做数字描字帖的粗体字体——Gill Sans MT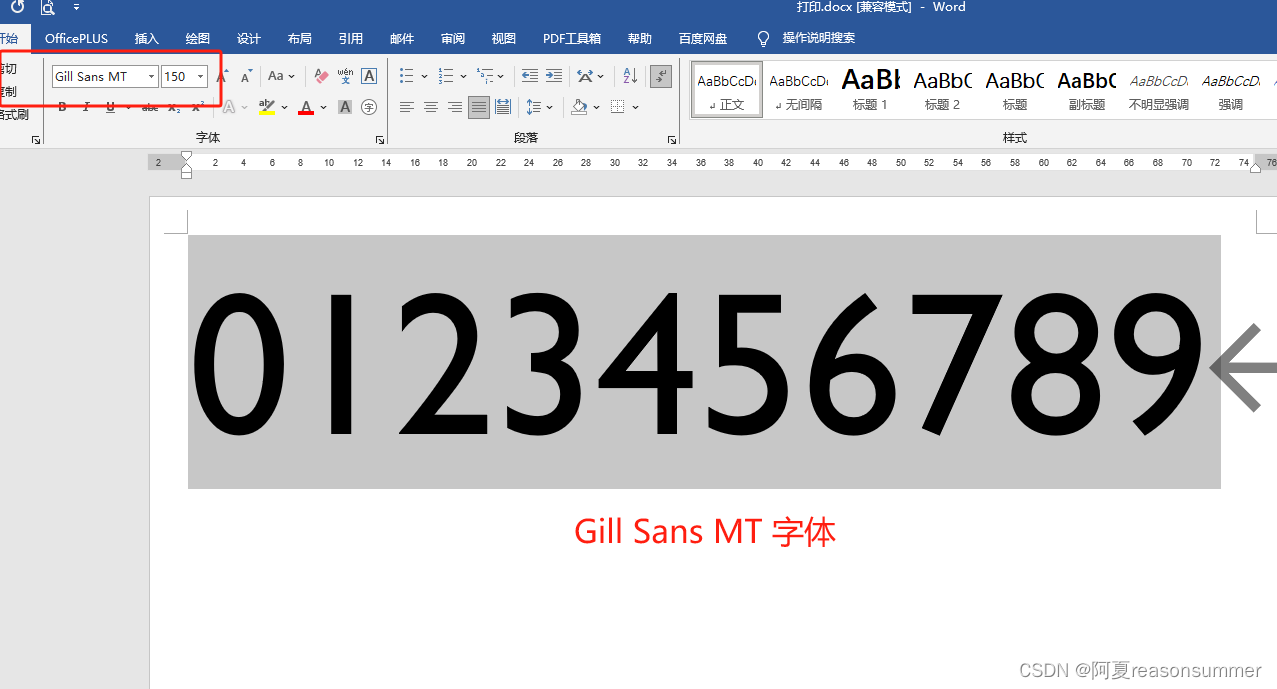
具体代码和以下两个字体一样,只是修改的字体大小(字号改小)
【教学类-44-05】20240201 德彪钢笔行书(实线字体)制作的数字描字帖-优快云博客文章浏览阅读396次,点赞6次,收藏5次。【教学类-44-05】20240201 德彪钢笔行书(实线字体)制作的数字描字帖 https://blog.youkuaiyun.com/reasonsummer/article/details/135970895【教学类-44-04】20240130 print dashed(虚线字体)制作的数字描字帖-优快云博客文章浏览阅读796次,点赞9次,收藏3次。【教学类-44-04】20240130 print dashed(虚线字体)制作的数字描字帖_print dashedhttps://blog.youkuaiyun.com/reasonsummer/article/details/135940963
https://blog.youkuaiyun.com/reasonsummer/article/details/135970895【教学类-44-04】20240130 print dashed(虚线字体)制作的数字描字帖-优快云博客文章浏览阅读796次,点赞9次,收藏3次。【教学类-44-04】20240130 print dashed(虚线字体)制作的数字描字帖_print dashedhttps://blog.youkuaiyun.com/reasonsummer/article/details/135940963
素材准备:




段落固定值41磅,写入的数字是最大55磅
原始代码展示:
'''
作者:阿夏
时间:2024年3月23日
名称:阿拉伯数字字帖 01数字字帖_Gill Sans MT(不加粗) AI缩略版代码
'''
import os
from docx import Document
from docx.shared import Pt, RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docx2pdf import convert
from PyPDF2 import PdfMerger
# 多少份(必须双数)
num = 2
lie = 16
hang = 10
ziti = 'Gill Sans MT'
size = 43
path=r'C:\Users\jg2yXRZ\OneDrive\桌面\数字描字帖'
imagePath = path+r'\零时Word'
if not os.path.exists(imagePath):
os.makedirs(imagePath)
number = [i for i in range(10) for _ in range(lie)]
bg = ['{:02d}{:02d}'.format(x, y) for x in range(hang) for y in range(lie)]
for n in range(int(num/2)):
doc = Document(path+fr"\01数字描字本_模板字帖.docx")
for b in range(2):
table = doc.tables[b]
for t in range(len(bg)):
pp, qq, k = int(bg[t][0:2]), int(bg[t][2:4]), number[t]
run = table.cell(pp, qq).paragraphs[0].add_run(str(k))
run.font.name = ziti
run.font.size = Pt(size)
run.bold = False
run.font.color.rgb = RGBColor(220, 220, 220)
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), ziti)
table.cell(pp, qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
doc.save(imagePath+fr'\{n:02d}.docx')
convert(imagePath+fr'\{n:02d}.docx', imagePath+fr'\{n:02d}.pdf')
pdf_lst = [os.path.join(imagePath, filename) for filename in os.listdir(imagePath) if filename.endswith('.pdf')]
pdf_lst.sort()
file_merger = PdfMerger()
for pdf in pdf_lst:
file_merger.append(pdf)
file_merger.write(path+fr'\(打印合集){ziti}字帖 阿拉伯数字0-9({num}份).pdf')
file_merger.close()
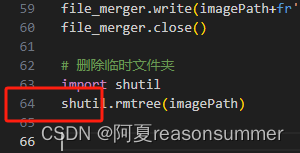
# 删除临时文件夹
import shutil
shutil.rmtree(imagePath)
# import xlwt
# import xlrd
# import os
# import random
# from win32com.client import constants,gencache
# from win32com.client.gencache import EnsureDispatch
# from win32com.client import constants # 导入枚举常数模块
# import os,time
# import docx
# from docx import Document
# from docx.shared import Pt
# from docx.shared import RGBColor
# from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
# from docx.oxml.ns import qn
# num=2
# # int(input('多少份双数\n'))
# lie=16
# hang=10
# ziti='Gill Sans MT'
# size=43
# # 新建一个”装N份word和PDF“的临时文件夹
# imagePath1=r'C:\Users\jg2yXRZ\OneDrive\桌面\数字描字帖\零时Word'
# if not os.path.exists(imagePath1): # 判断存放图片的文件夹是否存在
# os.makedirs(imagePath1) # 若图片文件夹不存在就创建
# print('-----第1步 制作数字-------')
# number=[]
# for i in range(0,10):
# for h in range(lie):
# number.append(i)
# print(number)
# print('-----第2步 制作表格-------')
# # # 25个数组【】
# # #单元格坐标
# bg=[]
# for x in range(hang):
# for y in range(lie):
# z2='{}{}'.format('%02d'%x,'%02d'%y)
# bg.append(z2)
# print(bg)
# # # ['00', '01', '02', '03', '04', '10', '11', '12', '13', '15', '20', '21', '22', '23', '24']
# for n in range(int(num/2)):
# doc = docx.Document(r"C:\Users\jg2yXRZ\OneDrive\桌面\数字描字帖\01数字描字本_模板字帖.docx")
# for b in range(2):
# table = doc.tables[b]
# # print(p)
# for t in range(len(bg)): # 0-15
# # print(list[t])
# pp=int(bg[t][0:2]) # 提取表格bg里面每个元素的第0个数字==单元格X坐标 t=索引数字
# qq=int(bg[t][2:4])
# k=int(number[t])
# # f=font[t]
# print(pp,qq,k)
# run=table.cell(pp,qq).paragraphs[0].add_run(str(k)) # 在单元格0,0(第1行第1列)输入第0个名字
# run.font.name =ziti #输入时不同字体
# run.font.size = Pt(size) #输入字体大小80或68号
# run.bold=False # 不加粗
# run.font.color.rgb = RGBColor(220,220,220) #设置颜色灰色
# r = run._element
# r.rPr.rFonts.set(qn('w:eastAsia'),ziti )#将输入语句中的中文部分字体变为华文行楷
# table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
# doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\数字描字帖\零时Word\{}.docx'.format('%02d'%n))#保存为XX学号的零时word
# from docx2pdf import convert
# # docx 文件另存为PDF文件
# inputFile = r"C:\Users\jg2yXRZ\OneDrive\桌面\数字描字帖\零时Word\{}.docx".format('%02d'%n)# 要转换的文件:已存在
# outputFile = r"C:\Users\jg2yXRZ\OneDrive\桌面\数字描字帖\零时Word\{}.pdf".format('%02d'%n) # 要生成的文件:不存在
# # 先创建 不存在的 文件
# f1 = open(outputFile,'w')
# f1.close()
# # 再转换往PDF中写入内容
# convert(inputFile, outputFile)
# from docx2pdf import convert
# print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# import os
# from PyPDF2 import PdfMerger
# target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/数字描字帖/零时Word'
# pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
# pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
# pdf_lst.sort()
# file_merger = PdfMerger()
# for pdf in pdf_lst:
# print(pdf)
# file_merger.append(pdf)
# # file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/数字描字帖/(打印合集)大班A整页描字帖2乘5加表格-4名字-({}人).pdf".format(num))
# file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/数字描字帖/(打印合集){}字帖 阿拉伯数字0-9({}份).pdf".format(ziti,num))
# file_merger.close()
# # doc.Close()
# # # print('----------第5步:删除临时文件夹------------')
# import shutil
# shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/数字描字帖/零时Word') #递归删除文件夹,即:删除非空文件夹`
终端展示
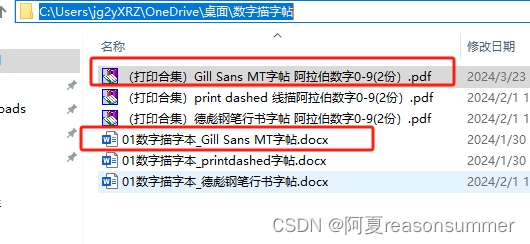
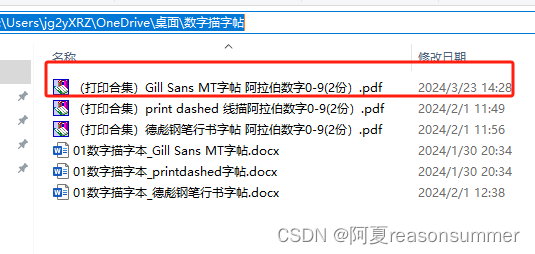
结果展示:

字体特性:
1、很粗:可以用记号笔描
2、近似手写体:1这个数字也没有勾,但是没有倾斜。
优化设计
我感觉以上代码太长了117行,所以用AI对话大师写个简略班的
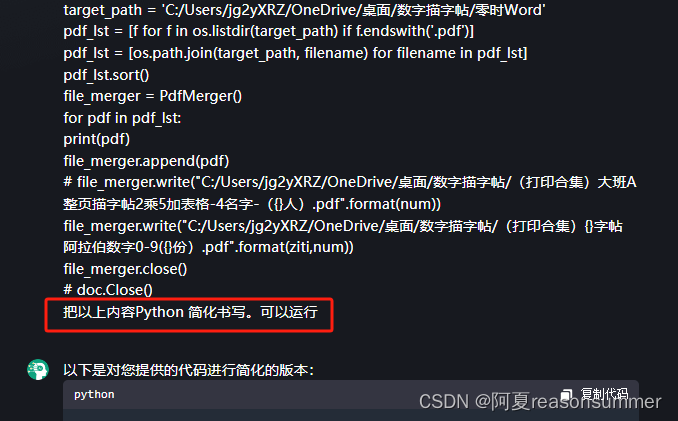
'''
作者:阿夏
时间:2024年3月23日
名称:阿拉伯数字字帖 01数字字帖_Gill Sans MT(不加粗) AI缩略版代码
'''
import os
from docx import Document
from docx.shared import Pt, RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docx2pdf import convert
from PyPDF2 import PdfMerger
# 多少份(必须双数)
num = 2
lie = 16
hang = 10
ziti = 'Gill Sans MT'
size = 43
path=r'C:\Users\jg2yXRZ\OneDrive\桌面\数字描字帖'
imagePath = path+r'\零时Word'
if not os.path.exists(imagePath):
os.makedirs(imagePath)
number = [i for i in range(10) for _ in range(lie)]
bg = ['{:02d}{:02d}'.format(x, y) for x in range(hang) for y in range(lie)]
for n in range(int(num/2)):
doc = Document(path+fr"\01数字描字本_{ziti}字帖.docx")
for b in range(2):
table = doc.tables[b]
for t in range(len(bg)):
pp, qq, k = int(bg[t][0:2]), int(bg[t][2:4]), number[t]
run = table.cell(pp, qq).paragraphs[0].add_run(str(k))
run.font.name = ziti
run.font.size = Pt(size)
run.bold = False
run.font.color.rgb = RGBColor(220, 220, 220)
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), ziti)
table.cell(pp, qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
doc.save(imagePath+fr'\{n:02d}.docx')
convert(imagePath+fr'\{n:02d}.docx', imagePath+fr'\{n:02d}.pdf')
pdf_lst = [os.path.join(imagePath, filename) for filename in os.listdir(imagePath) if filename.endswith('.pdf')]
pdf_lst.sort()
file_merger = PdfMerger()
for pdf in pdf_lst:
file_merger.append(pdf)
file_merger.write(path+fr'\(打印合集){ziti}字帖 阿拉伯数字0-9({num}份).pdf')
file_merger.close()
# 删除临时文件夹
import shutil
shutil.rmtree(imagePath)
只有64行,少多了





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











